







 本文详细介绍了Java中Set接口的实现类:HashSet、LinkedHashSet和TreeSet。HashSet是最简单的实现,基于HashMap,保证元素唯一,允许一个null。LinkedHashSet在HashSet基础上增加双链表,保持插入顺序。TreeSet实现了SortedSet接口,具有排序功能,基于TreeMap实现。
本文详细介绍了Java中Set接口的实现类:HashSet、LinkedHashSet和TreeSet。HashSet是最简单的实现,基于HashMap,保证元素唯一,允许一个null。LinkedHashSet在HashSet基础上增加双链表,保持插入顺序。TreeSet实现了SortedSet接口,具有排序功能,基于TreeMap实现。
java.util 中实现 set 接口的常用类主要有三个:
- HashSet
- LinkedHashSet
- TreeSet
我一个个来分析。
1 Set接口
一个不包含重复元素的 collection。更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。正如其名称所暗示的,此接口模仿了数学上的 set 抽象。

2 HashSet
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
此类为基本操作提供了稳定性能,这些基本操作包括 add、remove、contains 和 size,假定哈希函数将这些元素正确地分布在桶中。对此 set 进行迭代所需的时间与 HashSet 实例的大小(元素的数量)和底层 HashMap 实例(桶的数量)的“容量”的和成比例。因此,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
注意,此实现不是同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));此类的 iterator 方法返回的迭代器是快速失败 的:在创建迭代器之后,如果对 set 进行修改,除非通过迭代器自身的 remove 方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒将来在某个不确定时间发生任意不确定行为的风险。

源码分析
2.1 构造方法
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}从上面这一段代码不难看出,HashSet的底层就是一个HashMap,然后还有Cloneable、Serializable的性质。
2.2 基本操作
完全基于HashMap实现,所以非常简单,这里直接贴代码。如果对HashMap不了解,可以参考这篇博文:http://blog.csdn.net/dustin_cds/article/details/50837771。
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}3 LinkedHashSet
是HashSet的子类。
具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。此实现与 HashSet 的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。注意,插入顺序不 受在 set 中重新插入的 元素的影响。(如果在 s.contains(e) 返回 true 后立即调用 s.add(e),则元素 e 会被重新插入到 set s 中。)
此实现可以让客户免遭未指定的、由 HashSet 提供的通常杂乱无章的排序工作,而又不致引起与 TreeSet 关联的成本增加。使用它可以生成一个与原来顺序相同的 set 副本,并且与原 set 的实现无关:
void foo(Set s) {
Set copy = new LinkedHashSet(s);
...
}如果模块通过输入得到一个 set,复制这个 set,然后返回由此副本决定了顺序的结果,这种情况下这项技术特别有用。(客户通常期望内容返回的顺序与它们出现的顺序相同。)
此类提供所有可选的 Set 操作,并且允许 null 元素。与 HashSet 一样,它可以为基本操作(add、contains 和 remove)提供稳定的性能,假定哈希函数将元素正确地分布到存储段中。由于增加了维护链接列表的开支,其性能很可能会比 HashSet 稍逊一筹,不过,这一点例外:LinkedHashSet 迭代所需时间与 set 的大小 成正比,而与容量无关。HashSet 迭代很可能支出较大,因为它所需迭代时间与其容量 成正比。
链接的哈希 set 有两个影响其性能的参数:初始容量 和加载因子。它们与 HashSet 中的定义极其相同。注意,为初始容量选择非常高的值对此类的影响比对 HashSet 要小,因为此类的迭代时间不受容量的影响。
源码分析
刚刚打开LinkedHashSet的源码,我懵逼了。这里面所有方法都是直接调用HashSet的方法啊!? 那说明文档里,它怎么会有那么多和HashSet不一样的特性呢?于是到网上一搜,才知道原来是我在浏览HashSet的源码的时候没有注意到一个特殊的地方。原来HashSet中有一个专门给LinkedHashSet使用的构造方法,它的底层实现是LinkedHashMap:
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}注意“is only used by LinkedHashSet”这个表达。另外,为什么像这样来写代码,我没有找到答案,如果有网友知道请不吝赐教。
4 TreeSet
基于 TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。此实现为基本操作(add、remove 和 contains)提供受保证的 log(n) 时间开销。
另外,TreeSet实现的是NavigableSet接口(NavigableSet –> SortedSet –> Set)。
**TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。**TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。
4.1 SortedSet
进一步提供关于元素的总体排序 的 Set。这些元素使用其自然顺序进行排序,或者根据通常在创建有序 set 时提供的 Comparator 进行排序。该 set 的迭代器将按元素升序遍历 set。提供了一些附加的操作来利用这种排序。(此接口是 SortedMap 的 set 对应接口)。

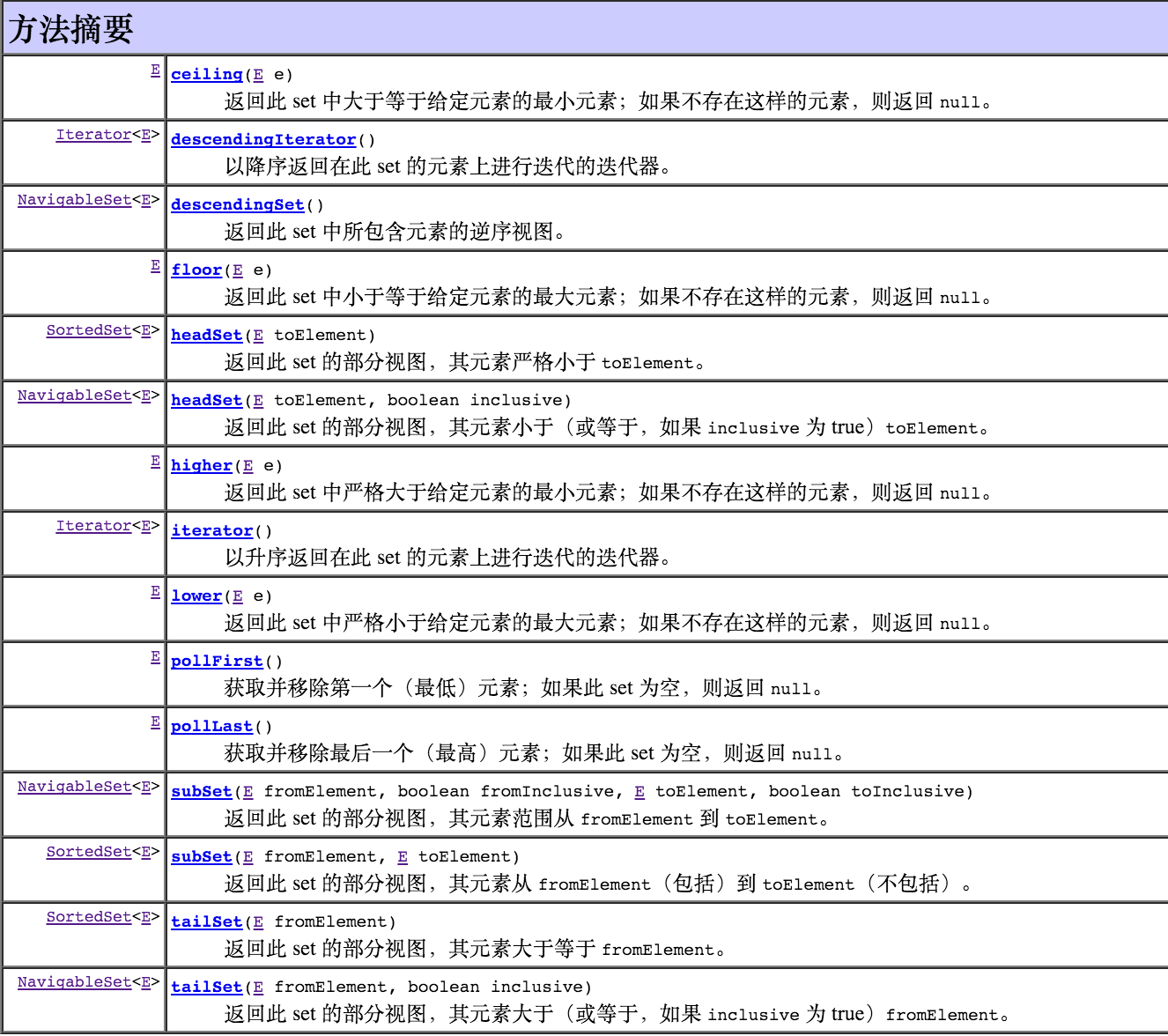
4.2 NavigableSet
扩展的 SortedSet,具有了为给定搜索目标报告最接近匹配项的导航方法。方法 lower、floor、ceiling 和 higher 分别返回小于、小于等于、大于等于、大于给定元素的元素,如果不存在这样的元素,则返回 null。可以按升序或降序访问和遍历 NavigableSet。descendingSet 方法返回 set 的一个视图,该视图表示的所有关系方法和方向方法都是逆向的。升序操作和视图的性能很可能比降序操作和视图的性能要好。此外,此接口还定义了 pollFirst 和 pollLast 方法,它们返回并移除最小和最大的元素(如果存在),否则返回 null。subSet、headSet 和 tailSet 方法与名称相似的 SortedSet 方法的不同之处在于:可以接受用于描述是否包括(或不包括)下边界和上边界的附加参数。任何 NavigableSet 的 Submap 必须实现 NavigableSet 接口。
导航方法的返回值在允许 null 元素的实现中可能是不确定的。不过,即使在这种情况下,也可以通过检查 contains(null) 来明确结果。为了避免这样的问题,建议在此接口的实现中不 允许插入 null 元素。(注意,Comparable 元素的有序集本身不允许 null。)
4.3 源码分析
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<E,Object>());
}所以,TreeSet是基于TreeMap实现的。
5 总结
经过上面的分析,我们不能发现Set类都是基于Map类实现的,所以再底层一些的原理,需要通过学习Map类的源码来掌握,博主将在下一篇博文里分析。
对于Set类的学习,其实学习好接口即可,因为接口就是协议,就是他们的特性啊。三个Set实现的区别是:
- HashSet:Set的最简单的实现,即保证元素唯一,并且允许插入一个null;
- LinkedHashSet:在HashSet的基础上增加了 双链表维护插入顺序的机制;
- TreeSet:唯一实现了SortedSet的类,自带排序功能。















 3471
3471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









