






聚合报告会为测试中的每一个不同采样,在表格中创建一行统计值,如图12-10所示。对每一个采样,它都会统计服务器响应信息,并提供请求数目、Min、Max、Average、Error%、Throughput(requesr/second)及Throughput(Kilobytes per second)等统计值。一旦测试结束,那么吞吐率(Throughput)就是贯穿整个测试阶段的统计值。
吞吐率是从采样目标(如HTTP采样中的远程服务器)的角度来计算的。JMeter会计算请求产生需求的总时间,如果同一个线程中存在其他采样器和定时器,机会增加总的时间,从而减小吞吐率的值。因此两个名称不同(其他完全相同)的采样器,相对于两个名称相同的采样器而言,吞吐率会减半。因此用户需要为采样器正确命名,才能通过聚合报告获取正确的值。
计算Median(中间值)和90%Line(90%阈值)会占用更多内存。JMeter2.3.4及其以前版本,每个采样的细节信息都是独立存储的,这就意味着需要占用很多内存。新版本Jmeter将同一时刻的采样绑定在一起,因此占用的内存会减少很多,不过,对于需求秒数才能完成的采样而言,意味着相同时刻的采样数会变少,在这种情况下就会需要更多内存。聚合报告与Summary Report的功能完全相同,不过监听器Sunmmary Report不会存储单个采样的信息,因此只需要固定大小的内存。

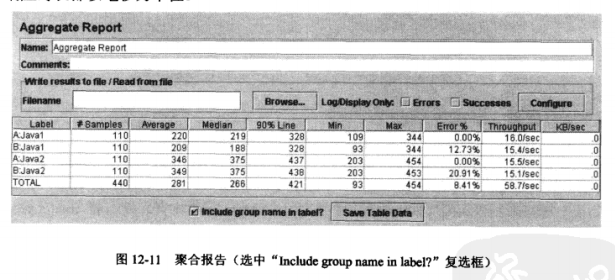
Label:采样标签。如果选中了“Include group name in label?”复选框,那么线程组的名称就会作为前缀,如图12-11所示,这样就能在必要的时候分线程组不同而标签相同的采样。
#Samples:标签名相同的总采样数。
Average: 一系列采样结果的平均响应时长。
Median:一系列采样结果响应时长的中间值。50%的采样响应时长不超过该值,剩下的采样响应时长不会比该值少。
90%Line:90%的采样响应时长不超过该值,剩下的采样响应时长不会比该值少。
Min: 标签名相同的采样中,最小的响应时长。
Max: 标签名相同的采样中,最大的响应时长。
Error%:采样发生错误的比率。
Throughput:该吞吐量以每秒/分钟/小时发生的采样数来衡量。单元时间已经选定,因此显示的吞吐率至少是1.0.如果将吞吐率保存到CSV文件中,它以请求数/秒的格式保存,例如30.0请求/分钟被保存为0.5。
KB/sec:该吞吐率以每秒KB来衡量。
响应时长都以毫秒为单位。















 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









