






掌握高并发、高可用架构
第二课 并发编程
从本课开始学习并发编程的内容。主要介绍并发编程的基础知识、锁、内存模型、线程池、各种并发容器的使用。
第八节 并发容器类
并发容器 CAS
借了一张图,展示了JDK的容器类族谱。
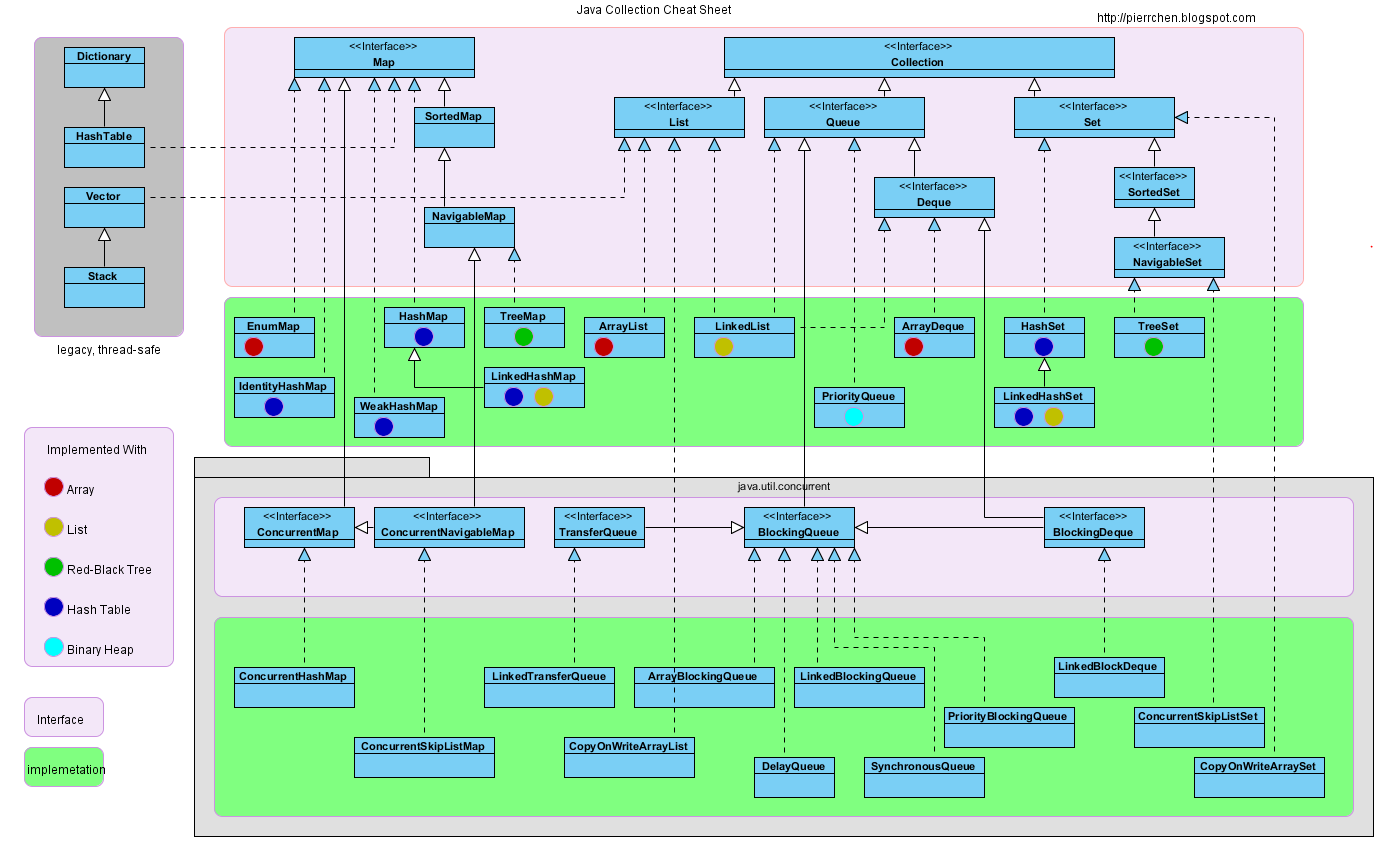
Map
Interface:
Map
SortedMap
NavigableMap
ConcurrentMap
ConcurrentNavigableMap
Class:
EnumMap
HashMap
WeakHashMap
IdentifyHashMap
TreeMap
LinkedHashMap
ConcurrentHashMap
ConcurrentSipListMap
Collection
List
Interface:
List
Class:
ArrayList
LinkedList
CopyOnWriteArrayList
Queue
Interface:
Queue
Deque
BlockingQueue
BlockingDeque
TransferQueue
Class:
ArrayDeque
PriorityQueue
ArrayBlockingQueue
LinkedBlockingQueue
SynchronousQueue
PriorityBlockingQueue
LinkedTransferQueue
DelayQUeue
LinkedBlockingDeque
Set
Interface:
Set
SortedSet
NavigableSet
Class:
HashSet
TreeSet,可对元素进行排序
LinkedHashSet,保持了元素的插入顺序
CopyOnWriteArraySet
ConcurrentSkipListSet并发List
-
CopyOnWriteArrayList,是ArrayList的线程安全体,由可变数组来实现。和ArrayList的区别是其数组内部均为有效数据。CopyOnWrite机制的一种容器:当添加一个元素时,不直接添加到当前容器,而是先将当前容器进行复制,复制出一个新的容器,并把元素添加到新容器中,完成之后,再将原容器的引用指向新容器;删除一个元素,也是同理的。
优点:可以对CopyOnWrite容器进行并发读操作,而不加锁
缺点:写操作效率低下,内存占用率高;做不到实时一致性
总结,适合读多写少的数据
并发Queue
并发的Queue主要有4种,共9个:
BlockingQueue,阻塞队列,包括ArrayBlockingQueue、DelayQueue、LinkedBlockingQueue、PriorityBlockingQuee、SynchronousQueueConcurrentLinkedDequeLinkedBlockingDequeConcurrentLinkedQueueLinkedTransferQueue
下面挨个来介绍。
-
ArrayBlockingQueue,是一个数组实现的有界阻塞队列。内部由一个ReentrantLock来控制生产和消费,两个Condition(notEmpty和notFull)控制,当取数据时,如果队列为空,则notEmpty.await();当添加数据时,如果队列满了,则notFull.await()。取出数据后,执行notFull.signal();添加数据后,执行notEmpty.signal()。队列元素位置计数由takeIndex、putIndex、count控制。默认是非公平锁的方式访问队列,可以指定为公平锁。public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } -
LinkedBlockingQueue,是利用链表实现的有界阻塞队列。如果不指定容量的话,默认的最大长度为Integer.MAX_VALUE。其内部对生产和消费使用了不同的锁,ReentrantLock的takeLock和ReentrantLock的putLock。对于put和offer采用同一把锁,take和poll采用另一把锁,从而避免读写时互相竞争锁的情况,分离了读写线程安全。在高并发读写的情况下都比ArrayBlockingQueue效率高。在遍历和删除时会同时锁住两把锁。阻塞由两个Condition(notEmpty和notFull)控制,队列元素位置计数由变量AtomicInteger count控制
put操作时,在putLock锁内,若队列满,则notFull.await(),不满时,notFull.signal()唤醒。
take操作时,在takeLock锁内,若队列空,则notEmpty.await(),不空时,notEmpty.signal()进行唤醒。
offer是无阻塞的enqueue或时间范围内的阻塞enqueue。
poll是无阻塞的dequeue或时间范围内的阻塞dequeue。
static class Node<E> { E item; Node<E> next; Node(E x) { item = x; } } -
DelayQueue,是一个支持延时获取元素的×××阻塞队列。存放数据 的队列是PriorityQueue,优先队列的比较基准值是时间。队列中的元素必须实现Delayed接口,其扩展了Comparable接口,比较的基准为延时的时间。Delayed接口的方法getDelayed的返回值为long。该方法指定元素创建多久才能从队列中获取到该元素。应用场景可以是:
- 缓存系统的设计:存储缓存元素的有效期,当能获取到元素时表示缓存有效期到了
- 定时任务的调度:存储要执行的任务,当能获取到任务时就可以执行一次
-
SynchronousQueue,是一个不存储元素的阻塞队列。每个put操作必须等待一个take操作,否则不能继续添加元素。SynchronousQueue可以看成一个传球手,负责把生产者处理的数据直接传递给消费者。可以认为SynchronousQueue是一个缓存值为1的阻塞队列,它不能调用
peek()来看队列中是否有元素,因为只有你来取的时候才可能存在,不取只偷看是不允许的。遍历队列也是不允许的。isEmpty()永远返回true。remainingCapacity()永远返回0。remove()和removeAll()永远返回false。iterator()永远返回null,peek()也是null。适合传递性场景。其吞吐量高于
LinkedBlockingQueue和ArrayBlockingQueue -
PriorityBlockingQueue,是一个按照优先级排列的阻塞队列,内部维护了一个由数组实现的平衡二叉树,存储的元素必须实现Comparable接口,用于判断元素的优先级。添加新元素时,并不是把全部元素进行顺序排列,而是从某个位置开始与新元素进行比较,一直比较到队列头,保证队头一定是优先级最高的元素。
每取一个头元素,都会对剩下的元素进行调整,保证队头一定是优先级最高的元素
-
ConcurrentLinkedDeque,源自jdk1.7,是一种非阻塞式并发双向×××队列,同时支持FIFO(先进先出)和FILO(先进后出)两种操作方式 -
LinkedBlockingDeque,源自jdk1.6,是一种由链表实现的阻塞式并发双向队列,即可以从队头和队尾同时操作。如果不指定容量,默认为Integer.MAX_VALUE。对于读写操作,采用一个独占锁来实现,所有的操作都枷锁来实现并发。由于是独占锁,不能同时进行两个操作,所以性能大打折扣。性能顺序:
ConcurrentLinkedQueue>LinkedBlockingQueue>LinkedBlockingDeque -
ConcurrentLinkedQueue,是一种非阻塞式并发链表,采用先进先出的规则。使用wait-free算法解决并发问题 -
LinkedTransferQueue,源自jdk1.7,是一种阻塞队列,增加了transfer相关的方法。transfer的语义是,生产者会一直阻塞直到transfer到队列的元素被某个消费者消费(不只是放入队列,还必须等到被消费)。使用put时不需要等待消费。LinkedTransferQueue采用一种预占模式,即当消费者来获取元素时,如果队列为空,那就生成一个节点(节点元素为null)入队,然后消费者被park住。后面的生产者入队时发现有一个元素为null的节点,此时生产者不入队,而是直接将元素填充到该节点,唤醒该节点上park的线程,被唤醒的消费者拿到元素走人。
并发Set
CopyOnWriteArraySet,内部是一个CopyOnWriteArrayList,所有操作都是基于对CopyOnWriteArrayList的。ConcurrentSkipListSet,内部是一个ConcurrentSkipListMap,Set的数据value被封装成<value, Boolean.TRUE>放入ConcurrentSkipListMap。需要注意的是value必须实现Comparable接口。
并发Map
-
ConcurrentHashMap,在jdk1.8之前使用锁分段技术来实现并发,并且提高了并发访问效率。锁分段原理:将数据分成一段一段进行存储,给每段数据配一把锁;当一个线程占有锁来访问一个段数据时,其他段的数据也可以被别的线程访问。ConcurrentHashMap实现时,由Segment数组和HashEntry数组组成。Segment是一种可重入的ReentranLock,HashEntry则用于存储键值对数据。一个ConcurrentHashMap包含一个Segment数组,Segment的数据结构和HashMap类似,是一种数组和链表结构,一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,当对数据进行修改时,必须获得相对应HashEntry的Segment的锁
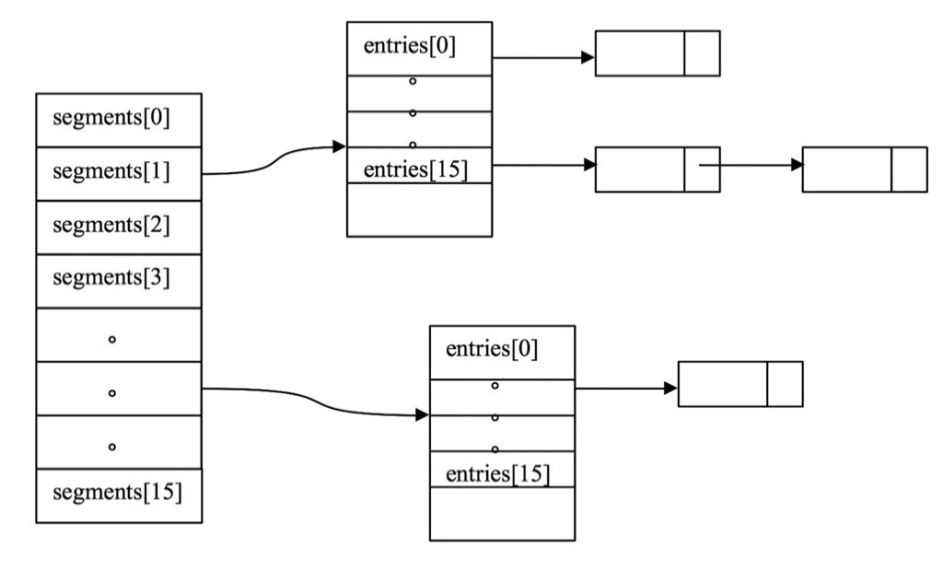
jdk1.8开始,ConcurrentHashMap摒弃了Segment段锁的概念,启用CAS算法实现。其底层数据结构和相对应的HashMap类似,采用“数组 + 链表 + 红黑树”。但是为了做到并发,又增加了很多辅助的类,如TreeBin、Traverser等内部类。
-
ConcurrentSkipListMap,是TreeMap的线程安全版本,使用CAS算法实现线程安全,适用于多线程情况下对Map的键值进行排序。对于键值排序需求,非多线程的情况下,应当尽量使用TreeMap;对于并发性相对较低的情况下,可以使用Collections.synchronizedSortedMap将TreeMap进行包装,也可以提供较好的效率;对于高并发的程序,应当使用ConcurrentSkipListMap,能够提供更高的并发度。它比ConcurrentHashMap有更高的并发度。ConcurrentSkipListMap的存取时间复杂度是logN,和线程数基本无关。所以在数据量一定的情况下,并发线程越多,越能体现它的优势。
ConcurrentSkipListMap是由跳表(Skip List)实现的,默认是按照Key值升序的,内部是由Node和Index组成的
其他的并发容器类
还有Collections工具类中提供的一系列普通容器类的线程安全版本的包装类。
Collections.synchronizedCollection(Collection c) -> SynchronizedCollection
Collections.synchronizedList(List l) -> SynchronziedList
Collections.synchronizedMap(Map m) -> SynchronizedMap
Collectionos.synchronizedSet(Set s) -> SynchronizedSet其效率低于真正的并发容器类















 41万+
41万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









