






Cell产品背景:
Cell组件、插件是中国第一个商业控件,采用ActiveX技术,能够快速制作出专业的各种复杂的中国报表,拥有600多个编程接口,实现报表自定义,报表显示、打印预览、打印,图表,公式,自定义函数、资源本地化等强大功能,能够完全读写Excel档。Cell完全解决了excel在使用的过程中出现的制表不稳定、程序运行慢且效率低、经常出现莫名其妙的错误以及要求客户机器上必须安装excel等等问题。
典型功能
¨制作中国式的复杂报表
¨丰富的单元格式与设计
¨强大的打印及打印预览
¨别具一格的选择接口
¨强大的图表功能
¨强大的单元公式
¨自定义函数
¨与Excel文件格式的兼容
¨名称管理(单元格命名, 数字、字符串、公式、区域命名),
¨资源本地化
¨转换PDF、CSV格式文件
Cell公式:
公式的解析运算, 对一个表格控件来说, 是必不可少的一个部分. 在数据汇总, 周报年报总结等多种应用环境. 但是, 表格控件有其特殊的地方, 表格是以一个一个的格式构成的, 没有公式都是有自己的一个位置的. 每个单元格公式都是跟其他单元格有相互引用, 跨表页引用等多种情况.
Cell根据表格控件的各种特性, 自主研发了适合表格控件的一套公式解析计算引擎. 如图:
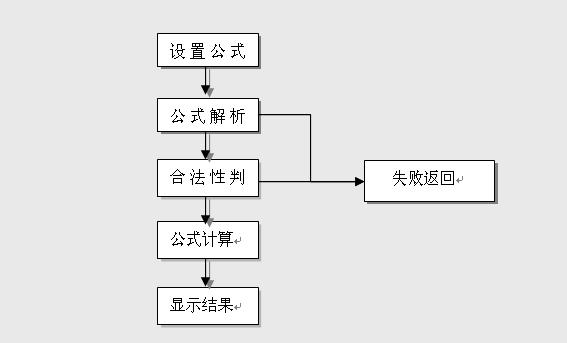
这里, 我将分几篇文章, 详细介绍一下Cell是如何实现上图中的各个部分.
Cell公式解析:
如何对单元格设置一个公式, 相信每个人都很熟悉Excel的应用, Cell本身的模板设计器, 跟Excel有很多的共同之处, 你只需要在Cell单元格上按一下 “=” 号, Cell 的公式编辑器就会显示在Cell 的顶端(类似Excel的公式栏), 选中 “B2” 单元格, 按”=”号, 其中输入”A1”, 引用单元格A1的内容. 这样, B2 就有一个公式了, 在修改A1单元格内容的时候, B2 的值就会改变.
我们也可以通过接口的方式来设置公式, 可以调用Cell接口SetFormula, 详细用法请参考http://www.cellsoft.cc/cell/index.asp
Cell对公式是如何解析的呢??
在输入公式的时候, 经过词法分析, Cell将输入的公式字符串解析为中间代码, 存储在SG_Formula, SG_EXPR, SG_POLISH_UNIT 结构中.
struct SG_Formula
{
long col;
long row;
long page;
CString text; //公式字符串
long state;
SG_EXPR expr;
};
struct SG_EXPR
{
SG_ENUM_VALUE valtype;
USHORT polishnum;
SG_POLISH_UNIT *polishs;
};
struct SG_POLISH_UNIT
{
SG_ENUM_POLITYPE etype;
short startpos;
short endpos;
union
{
double f; // value for a numerical constant
LPTSTR s; // a string , may occur is logic expr
SG_ENUM_OPERATOR opr; // inner code for an operator */
SG_AREA area; // an area
SG_3DCell cell; // a cell
SG_FUNCCALL *funcCall; // a function call
};
};
SG_POLISH_UNIT: 存储一个基本的语法单位. SG_ENUM_POLITYPE标示此语法单位的类型
SG_EXPR: 存储一个解析后的公式, 由多个SG_POLISH_UNIT组成
SG_Formula: 存储公式整个公式的信息, 包括位置, 公式解析后的 SG_EXPR
解析后的公式在cell中的都是存储在一个SG_Formula结构中.
我通过一个例子, 来看看Cell如何解析一个公式的.
例如 输入这样的一个公式 B2=A1+1+2
词法分析:
词法分析就是从左到右逐个字符的对公式进行扫描, 分析出其中单词符号.Cell中的单词符号的种类分为 6 种, 对应于SG_POLISH_UNIT中的 6 中类型, 即:
Double: 数值类型
String : 字符串类型
SG_ENUM_OPERATOR : 操作运算符类型 ( 如: “+”, “-“, “and” “:”, “>” 等)
SG_AREA: 单元格区域类型 (如: A1:B2, B3:B4)
SG_3DCell: 单个单元格类型 (如: A1)
SG_FUNCCALL: 函数类型
对于我们例子输入的公式来说, 我们可以将公式分解为下面5个单词符号
“A1” -> SG_3DCel类型
“+” -> SG_ENUM_OPERATOR 操作符
“1” , ”2” -> Double 数值类型
Cell对公式扫描过程中, 最终也是生成这样的一个单词符号组合. 解析过程中,
按照 以字符开头的符号 à 数字符号 à 字符串 à 其他符号 的过程解析的,
下面是Cell获得单词符号的代码.
SG_ENUM_TOKEN GetToken( )
{
USES_CONVERSION;
LPCTSTR curstr = sourcecode + curpos;
long realstartpos;
if( curtoken == TOKEN_CODE_END ){
return TOKEN_CODE_END;
}
//去掉空格
while ( ( unsigned ) *curstr <= 32 && *curstr != _T('/n') && *curstr != 0 )
++curstr;
//去掉双斜杠注释
if( *curstr == _T('/') && *(curstr+1) == _T('/') )
{
curstr += 2;
while( TRUE )
{
if( *curstr == 0x0d && *(curstr+1) == 0x0a)
{
curstr += 2;
break;
}
else if( *curstr == 0 )break;
else curstr++;
}
}
realstartpos = curstr - sourcecode;
lastpos = realstartpos;
//========================= any token begin with alpha or chinese
if ( (*curstr&0x80) || _istalpha( *curstr ) || *curstr == _T('$')) {
while( _istalnum( *curstr ) || *curstr == '_' || *curstr & 0x80 || *curstr == _T('$')){
//*curstr = tolower( *curstr );
++curstr;
}
CopyTokenString( realstartpos, curstr-sourcecode);
if( (curstr-sourcecode) - realstartpos+1 > SG_MAX_TOKEN_LEN)
throw ERR_TOKEN_TOOLONG;
if ( m_Func->IsFunction( curtokenstr ) )
curtoken = TOKEN_FUNC;
else if( _tcsicmp( curtokenstr, _T("and") ) == 0 )
curtoken = TOKEN_AND;
else if( _tcsicmp( curtokenstr, _T("or") ) == 0 )
curtoken = TOKEN_OR;
else if( _tcsicmp( curtokenstr, _T("not") ) == 0 )
curtoken = TOKEN_NOT;
else
curtoken = TOKEN_ID;
}
//========================= = digit token: include integer and float number
else if ( _istdigit( *curstr ) || *curstr == _T('.') ) {
if( _istdigit( *curstr )){
curtoken = TOKEN_INTEGER;
while( _istdigit( *++curstr ) );
}
if( *curstr == '.' ){
while( _istdigit( *++curstr ) );
curtoken = TOKEN_FLOAT_NUM;
}
if ( *curstr == 'e' || *curstr == 'E' ){
if ( curstr[1] == '+' || curstr[1] == '-' ){
if ( !_istdigit( curstr[2] ) )
throw ERR_EXPNT_EXPECTED;
++curstr;
}
if ( _istdigit( curstr[1] ) ){
while ( _istdigit( *++curstr ) );
curtoken = TOKEN_FLOAT_NUM;
}
}
//要求其后面不是!
BOOL numvalid = TRUE;
LPCTSTR tstr = curstr;
while( *tstr != 0 ){
if( *tstr == 32 ){ tstr++; continue; }
else if( *tstr == '!' ){
numvalid = FALSE;
break;
}
else break;
}
if( numvalid ){
CopyTokenString( realstartpos, curstr-sourcecode );
if ( curtoken == TOKEN_INTEGER ){
if ( _tcslen( curtokenstr ) > 10 || ( _tcslen( curtokenstr ) == 10 ){
curtoken = TOKEN_FLOAT_NUM;
floattokenval = ttof( curtokenstr );
}
else
inttokenval = _ttol ( curtokenstr );
}
else
{
floattokenval = ttof( curtokenstr );
}
}
else{ //这是一个页签
CopyTokenString( realstartpos, curstr-sourcecode);
curtoken = TOKEN_ID;
}
}
//============================== string token: like "Avsd"
else if ( *curstr == '"' ) {
do {
++curstr;
}while( !(*curstr == '"' && *(curstr-1) != '//' ) && *curstr );
if ( *curstr == 0 )
throw ERR_YIN_HAO_UNMATCH;
//CopyTokenString( realstartpos+1, curstr-sourcecode );
strtokenval = sourcecode+realstartpos+1;
strtokenlen = (curstr-sourcecode)-realstartpos-1;
++curstr;
curtoken = TOKEN_STRING;
}
//================================= any other token
else {
switch( *curstr ){
case ':':
curtoken = TOKEN_MAO_HAO;
break;
case '/n':
curtokenstr[0] = 0;
curtoken = TOKEN_LINE_END;
break;
case '/0':
curtokenstr[0] = 0;
curtoken = TOKEN_CODE_END;
break;
case ',':
curtoken = TOKEN_DOU_HAO;
break;
case '!':
curtoken = TOKEN_TANG_HAO;
break;
case '/' :
curtoken = TOKEN_DIV_OP;
break;
case '-':
curtoken = TOKEN_MINUS_OP;
break;
case '+':
curtoken = TOKEN_ADD_OP;
break;
case '*':
curtoken = TOKEN_MULTI_OP;
break;
case '(':
curtoken = TOKEN_L_KUO_HAO;
break;
case ')':
curtoken = TOKEN_R_KUO_HAO;
break;
case '=':
curtoken = TOKEN_EQUAL_HAO;
break;
case '>':
if ( *(curstr+1) == '=' ){
curstr++;
curtoken = TOKEN_EQGREAT_HAO;
}
else
curtoken = TOKEN_GREAT_HAO;
break;
case '<':
if ( *(curstr+1) == '=' ){
curstr++;
curtoken = TOKEN_EQSMALL_HAO;
}
else if ( *(curstr+1) == '>' ){
curstr++;
curtoken = TOKEN_NOTEQ_HAO;
}
else
curtoken = TOKEN_SMALL_HAO;
break;
case '^':
curtoken = TOKEN_POWER;
break;
default :
curtoken = TOKEN_UNKNOWN;
}
curtokenstr[0] = *curstr++;
curtokenstr[1] = '/0';
}
curpos = curstr - sourcecode;
tokenstartpos = realstartpos;
return curtoken;
}
中间代码:
Cell通过词法分析, 会将公式 A1+1+2 分解为 5 个基本的语法单位. 每一个语法单位存储在SG_POLISH_UNIT. 5个语法单位构成一个公式SG_EXPR.
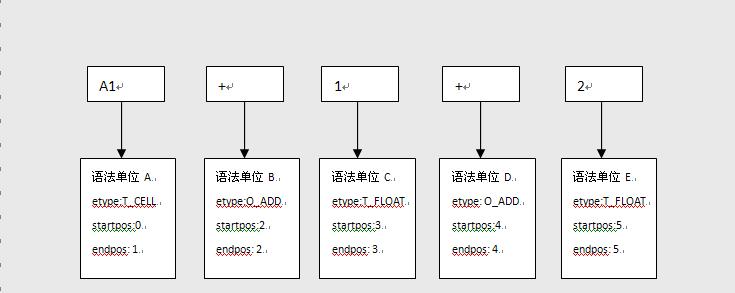 | |||||||||
| A1+1+2 分解后, 每一单位都会分配一个Cell可以识别的单词符号, 如 “A1” 识别为一个T_CELL类型的符号, “+” 识别为一个 O_ADD 操作运算符号等
每一个语法单位通过 startpos endpos 对应到你输入的源公式字符串. 方便以后对公式做调整.
分解后的5个语法单位以数组的形式存储在公式SG_EXPR 中的 polishs 成员中.
这样, 输入的公式经过词法分析后, 我们得到了 语法单位的 类型, 单词符号, 还有每个语法单位对应的一个Cell内部类型对象. 为随后的合法性验证, 公式计算的打下基础. |















 1866
1866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









