






来源:生物探索
随着世界疫情的发展,多个国家进入公共卫生紧急状态,全球科学家都在抓紧研究更好的检测、治疗、防控手段。从最初未知β属冠状病毒的快速鉴定到病毒序列的完整破译,再到病毒序列的变异监测,高通量测序技术在疫情防控工作中发挥了非常重要的作用。
测序技术在新冠病毒检测中的意义和价值
在科学研究方向,采用高通量测序技术,可在第一时间获取新发未知病毒的基因组序列信息,为突发疫情的防控和后续研究提供了帮助,例如通过构建进化树揭示其病原相关特性、分析新冠病毒的进化来源、研究新冠病毒的致病病理机制等。
在临床诊断方向,采用高通量测序技术,可一次性完成细菌、真菌、病毒和寄生虫等多种病原体检测[1]。针对在新冠疫情中RT-PCR核酸检测阴性,但临床表型高度疑似的患者,可利用高通量测序技术进行进一步确认,同时检测包括新冠病毒在内的所有可能感染的病原微生物基因序列,为多重感染或继发感染的相关病原信息提供参考依据。
测序技术在新冠病毒检测中的原理和方法
具体到新冠病毒的检测原理,是指针对疑似样本中所有核酸或来自特定靶标的核酸进行高通量测序,通过生物信息学分析检测样本中的所有病原微生物或其靶标序列。因此,采用高通量测序技术,能够检测包括新型冠状病毒在内的所有可能感染的病原微生物基因序列。
目前,基于高通量测序技术在新冠病毒的检测和研究中可展开的技术路线或方法有3种[2]:宏基因组测序(Meta)、探针捕获测序(Capture)和多重PCR扩增子测序(Amplicon)。
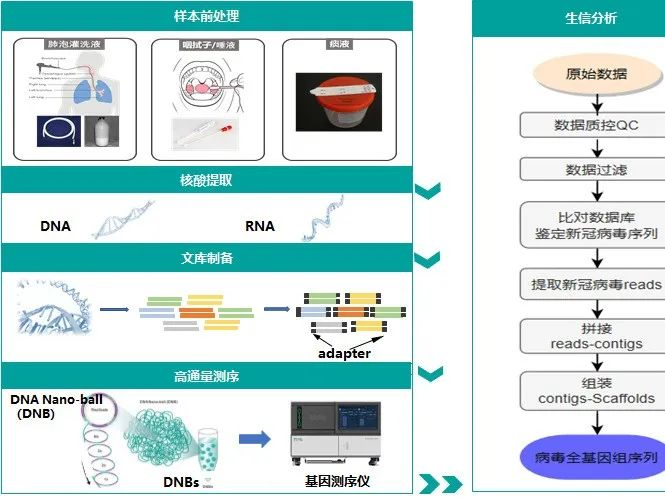
图1 新冠病毒高通量测序方法
测序技术在新冠病毒检测中的应用方案
结合测序技术在新冠病毒检测中的多种应用方法,华大智造DNBSEQ平台均已推出配套的整体解决方案,包括一站式核酸提取、自动化样本制备和高通量基因测序。在今年1月初,华大与中国科学院微生物研究所、山东第一医科大学通力合作,基于华大智造超高通量测序仪DNBSEQ-T7完成新冠病毒全基因组序列组装[3],正是采用了高通量宏基因组测序方法。

图2 新冠病毒高通量测序整体解决方案
与此同时,艾吉泰康、伯科生物等先后推出了基于华大智造DNBSEQ平台的探针捕获试剂盒,支持新冠病毒的探针捕获测序。
特别地,针对多重PCR扩增子测序方法,华大智造自主开发的新冠多重PCR 扩增子测序Panel(SARS-CoV-2 Full Length Genome Panel),不仅能够应用于新冠病毒的全基因组组装、病毒变异检测、进化研究,还能够应用于病毒载量极低的极端样本检测,最低仅需1M Reads就可获取病毒全基因组信息,比常规RT-PCR灵敏度更高。此外,相较于高通量宏基因测序而言,该方法的检测成本更低,更能满足将高通量测序技术应用于大规模筛查的需求,包括对RT-PCR假阴性样本进行二次检测和复核确诊等。
测序技术在新冠病毒检测中的科研攻关
在全球科学家的共同努力之下,基于华大智造DNBSEQ测序平台的相关科研工作陆续获得突破性进展。

图3 基于DNBSEQ平台的新冠病毒高通量测序科研攻关
在柳叶刀获发的一项研究中[4],研究采集了武汉地区至少3家医院的9例住院患者的支气管肺泡灌洗液和培养分离物,基于华大智造DNBSEQ-T7平台进行高通量测序,对病毒起源展开探讨。
另外一项研究在Nature获发[5]。该研究采用7例重症新冠肺炎患者的样本,基于华大智造MGISEQ-2000平台进行高通量测序并展开相关的对比分析,对病毒进入细胞的路径展开探讨。
3月15日,韩国基础科学研究所 (IBS, Institute of Basic Science) RNA 研究中心联合国立首尔大学(Seoul National University)和韩国疾病预防控制中心(Korea Centers for Disease Control & Prevention)利用华大智造DNBSEQ 技术联合 Nanopore 单分子测序技术,对新冠病毒感染的Vero细胞总RNA进行了分析,并结合以往研究给出了新冠病毒转录组和表观转录组的高清图谱[6]。测序数据显示,华大智造 MGISEQ-200 平台的测序深度更高,相比单分子测序技术,可以对病毒基因组进行更高深度覆盖,能够在更精细水平上研究基因组。
测序技术在新冠病毒检测中的应用案例
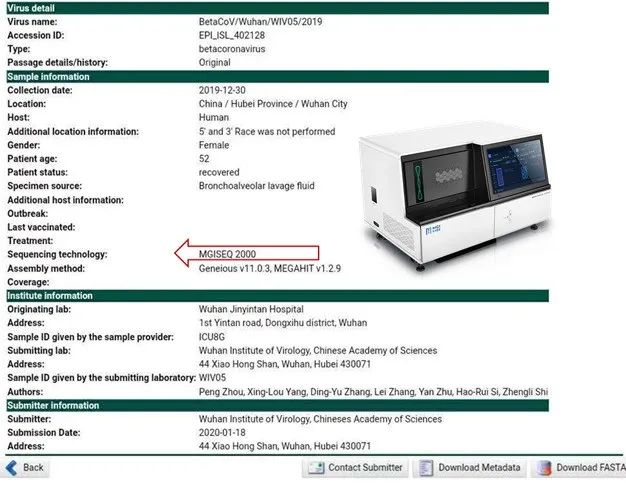
图4 基于DNBSEQ平台的首批新冠病毒基因组序列数据
疫情爆发之初,在最早一批提交至全球共享流感病毒数据库GISAID发布的新冠病毒基因组序列数据中,来自武汉金银潭医院的5例数据,是基于华大智造高通量测序仪MGISEQ-2000在第一时间产出,为后续工作提供了第一手资料。

图5 基于DNBSEQ平台的新冠病毒基因组序列组装
1月底,基于MGISEQ-200平台,某地疾控中心对该地发现的首例新冠肺炎病例样本进行了高深度测序(300M Reads),成功完成新型冠状病毒的序列组装,获得基因组序列全长29.9kb。而在此前,基于其他测序平台的下机数据对新冠病毒序列的组装和拼接效果并不理想。这是因为,在样本病毒载量较低时,宏基因组测序对数据量的要求比较高,如果测序平台产出的数据量不足,会导致病毒序列信息获取不完整,影响后续研究和分析。

图6 基于DNBSEQ平台的新冠病毒样本上机检测
2月底,全国首例报道的新冠肺炎并脑炎患者成功治愈。在诊治过程中,北京地坛医院重症医学科、检验科及中国疾控中心传染病所联合工作组利用华大智造MGISEQ-2000对该病例采集的脑脊液样本进行了高通量宏基因组测序,排除了其他病原体,获得了新冠病毒基因组序列,证实了脑脊液中存在新冠病毒,临床诊断为病毒性脑炎。此病例报道在全球尚属首例,提醒临床一线工作人员需要警惕新冠病毒感染可累及中枢神经系统,需要及时进行脑脊液等相关检查,并完善脑脊液SARS-CoV-2核酸及基因测序等工作,为更全面了解COVID-19做出探索,并积极处理相关神经系统并发症,从而进一步降低危重病人的病死率。
综上,作为新冠病毒的确诊方法之一,基于华大智造DNBSEQ平台的高通量测序技术在全球疫情的防控中发挥了重要作用和积极影响。目前,由华大智造提供的新冠病毒自动化检测方案和高通量测序方案已在全球多地展开应用。
FAQ
1.如果病毒核酸序列在疑似样本中的占比很低,做高通量测序的话,会不会有影响?
样本病毒载量对高通量宏基因组测序的影响比较大,如果测序平台产出的数据量不足,会导致病毒序列信息获取不完整,影响后续研究和分析。在这种情况下,可以采用多重PCR方法进行建库和高通量测序,能够直接对极低载量病毒进行百万倍富集,适用于各种极端样本(病毒载量<102copies/ml或Ct值>35);也可以先进行去rRNA处理,然后再进行高通量宏基因组测序,但需要注意的是,去rRNA方法可能会导致的偏向性。
2.建库是如何操作的?
由华大智造提供的自动化文库制备方案,包括自动化文库制备系统MGISP-100、MGISP-960和MGIEasy RNA文库制备试剂套装、MGIEasy RNA文库快速制备试剂套装、MGIEasy rRNA去除试剂盒等。其中,MGISP-960自动化样本制备系统,可在8小时内完成96个样本的自动化测序文库制备;MGISP-100自动化样本制备系统则可在8小时内完成16个样本的文库制备工作。目前,两款设备皆可兼容第三方文库制备试剂盒,均已获得CB认证、CE认证、cTUVus认证、NMPA认证。
3.请问RNA和DNA需要分开建库吗?
如果仅检测新冠病毒,只需检测RNA即可,不需要分开建库,因为新冠病毒是RNA病毒;但如果是针对复合感染病例的检测,则建议分开建库,可以同时对DNA和RNA分别进行检测。
End
参考资料:
[1] DOI:10.3760/cma.j.issn.1009-9158.2020.0008
[2] DOI: https://doi.org/10.1101/2020.03.16.993584
[3] https://db.cngb.org/datamart/disease/DATAdis19/
[4] Genomic characterisation and epidemiology of 2019 novel coronavirus implications for virus origins and receptor binding. Lancet. 2020 Jan 30.
[5] A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature. 2020 Feb 3.
[6] DOI: https://doi.org/10.1101/2020.03.12.988865
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









