







来源:DeepMind官网
纵观整个历史,成功的沟通和合作在促进社会进步方面发挥着重要作用。棋盘兵棋,具有封闭的环境,恰好能够充当建模和交流互动研究的沙盒,推演这类兵棋,可以让我们学习很多东西。
我们在《自然通讯》上发表的文章,展示了人工代理如何在棋盘兵棋“外交”中通过交流更好地实现合作,这是人工智能(AI)研究中一个充满生机的领域,其以聚焦联盟建设而闻名。
“外交”兵棋的规则非常简单,但对阵员之间存在强大的依存关系而且行动空间非常大,因此该兵棋高度复杂,推演充满挑战性。为应对这些挑战,我们设计了能够让代理沟通并商议共同计划的协商算法,以解决代理不具备该能力的不足。
如果合作伙伴无法兑现承诺,那么合作将更具挑战性。我们将“外交”兵棋充当沙盒,来研究代理违背之前的协议时会发生什么情况。研究表明,当复杂的代理能够歪曲他们的意图或对他人的未来计划产生误导时,则存在风险,这也引出了另一个大问题:促进值得信赖的沟通和团队合作的条件是什么?
我们的研究也表明,对违背协议的同伴采取制裁措施的策略,极大地削弱了他们通过放弃承诺所能获得的好处,这进而促进了更诚实的沟通。
“外交”兵棋及其重要性概述
外交兵棋是聚焦交流、合作、协商的七对阵员兵棋,使用划分为七个地区的旧欧洲地图(其中的一些地区比较特殊,被标记为补给中心)。兵棋推演中,每个对阵员控制多个单位。该兵棋标准版每回合都包含一个协商阶段,该阶段结束后所有对阵员在行动阶段同时表明所选择的行动。
协商阶段是“外交”兵棋的核心,在该阶段对阵员尝试就下一步行动达成一致。例如,一个单位可能为(同一或者其他对阵员的)另一单位提供支持,使其克服其他单位带来的阻力。如下图所示:
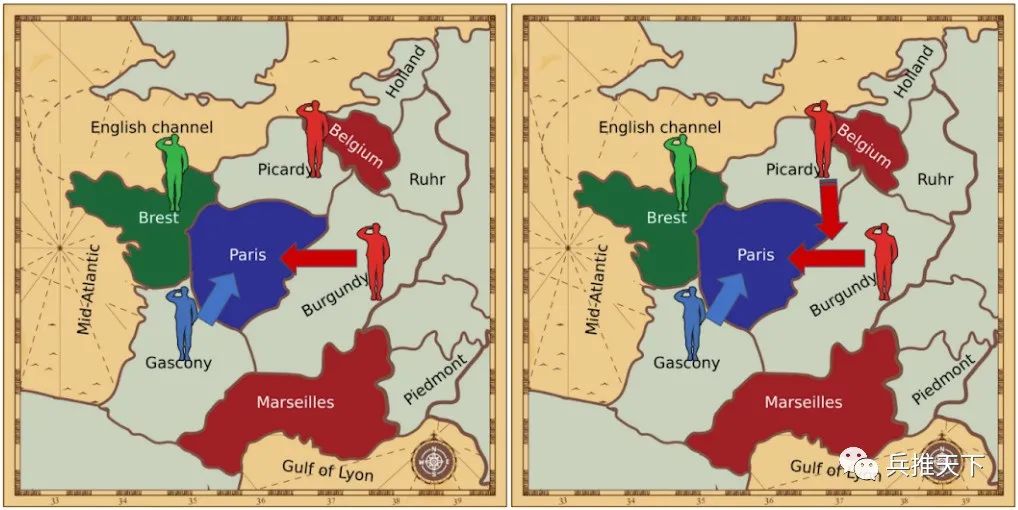
两个行动想定(左图:两个单位(位于勃艮第的红方单位以及位于加斯科尼的蓝方单位)试图进入巴黎,因为这两个单位实力相当,因此均未成功。右图:皮卡迪的红方单位为勃艮第的红方单位提供支持,蓝方单位被击败,红方单位进入勃艮第。)
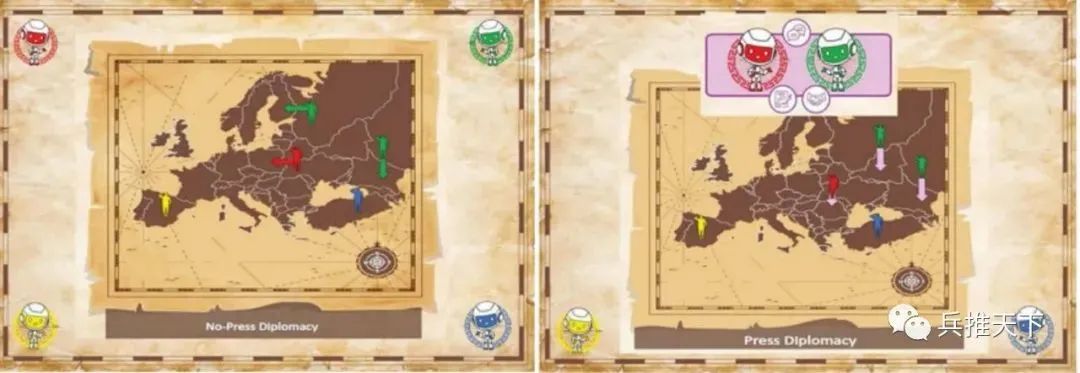
自20世纪80年代以来,人们一直在研究“外交”兵棋的人工智能方法,其中许多方法都是通过该兵棋的简化版 "无压力外交 "来探索的。在该版本中,对阵员之间不允许进行战略交流。研究人员还提出了计算机友好型谈判协议--有时被称为 "限制性压力"。
我们的研究
我们使用“外交”兵棋模拟现实谈判,为人工智能代理协调行动提供方法。我们使用无沟通外交代理,然后为它们提供了一个针对联合行动计划进行协商的协议,以增强其推演有交流外交的能力。我们将这些增强型代理称作基线谈判者,它们受协议的约束。
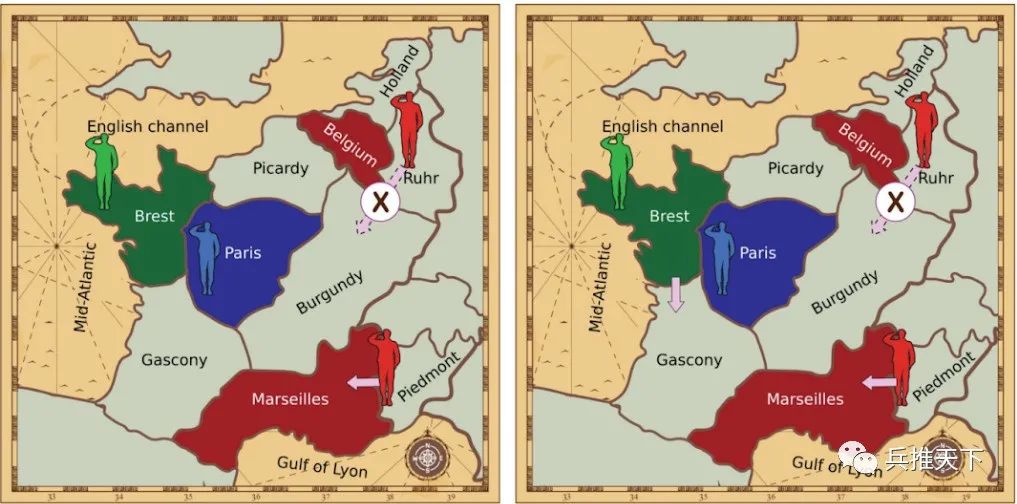
外交协议:(左图:仅允许红方对阵员采取某些行动的限制条件(红方对阵员不能从鲁尔进入勃艮第,必须从皮德蒙进入马赛)右图:红方与绿方对阵员之间的协议,双方都受到限制。)
我们考虑了两个协议:相互提议协议和提议-选择协议。代理通过模拟推演在各种约定下可能出现的情况,利用算法确定互利的交易。我们将博弈论中的纳什谈判方案作为识别高质量协议的原则基础。根据对阵员采取的行动,推演可能以多种方式展开,因此代理使用蒙特卡洛模拟法来观察下一回合可能发生的情况。
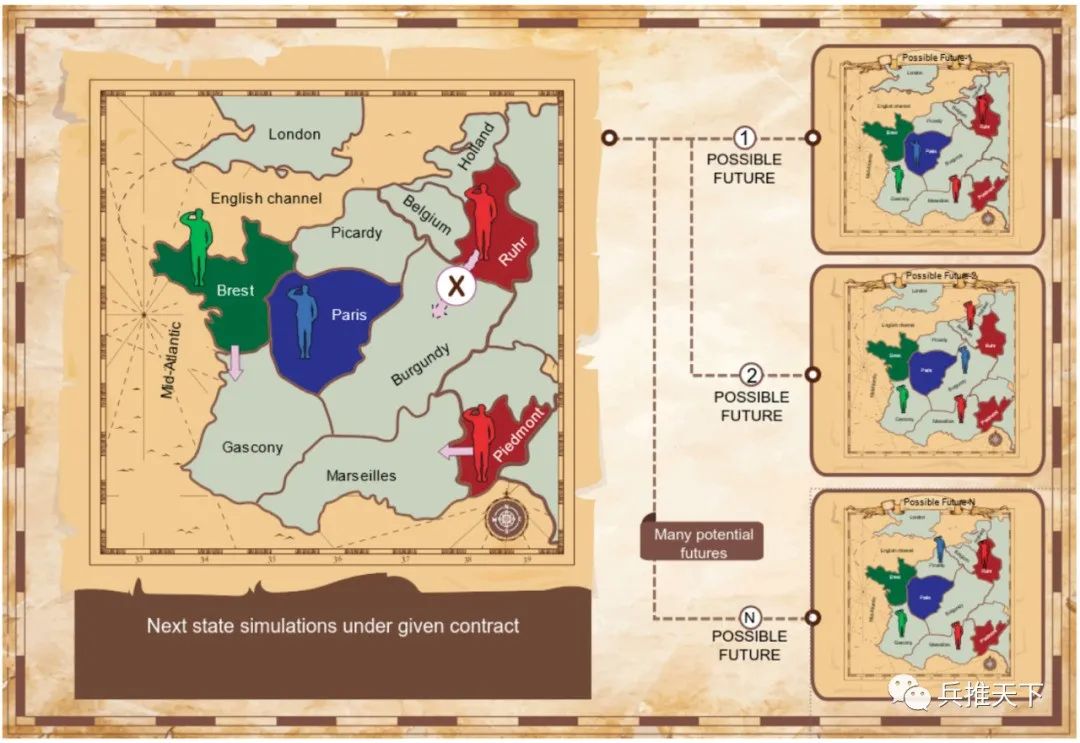
根据既定协议,模拟未来状态。(左图:棋盘一部分显示当前状态,包括红方和绿方对阵员达成的协议。右图:多种未来可能状态。)
实验表明,在我们设定的谈判机制下,基线谈判者的表现明显优于无沟通基线代理。
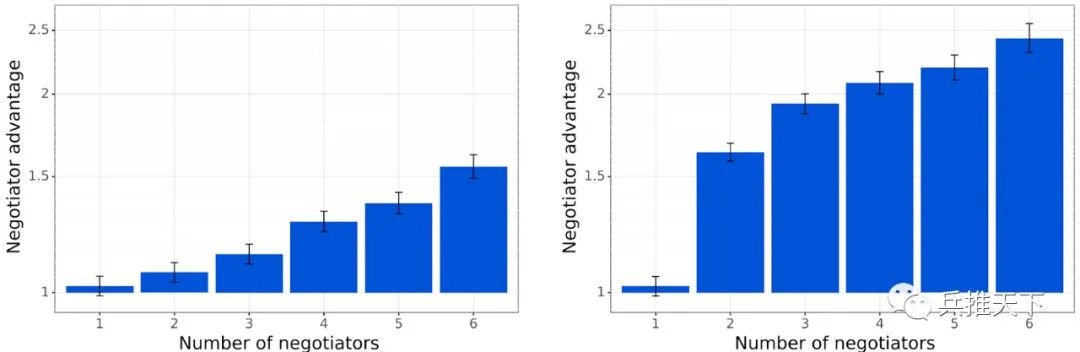
基线谈判者明显优于无沟通代理。(左图:相互提议协议,右图:提议-选择协议。“谈判者优势”指沟通代理和无沟通代理之间的胜率比。)
代理打破协议
在“外交”兵棋中,协商达成的协议不具有约束力(沟通是 "廉价的谈话")。但是,如果代理在某一回合同意了协议,在下一个回合中却并没有履行协议,会发生什么?在许多现实场景中,人们同意以某种方式行事,但后来却没有履行他们的承诺。
为了使人工智能代理之间或代理与人类之间的合作成为可能,我们必须研究代理战略性破坏协议的潜在隐患,以及补救方法。我们使用“外交”兵棋来研究放弃承诺的能力如何削弱信任和合作,并确定促进诚实合作的条件。
因此,我们考虑了背离代理人(Deviator Agents),他们通过违背商定好的协议来战胜诚实的基线谈判者。普通的背离者只是 "忘记了 "他们同意的协议,并随心所欲地采取行动。有条件的背离者则更为复杂,他们在假设其他接受协议的对阵员会按照协议行事的前提下,优化自己的行动。
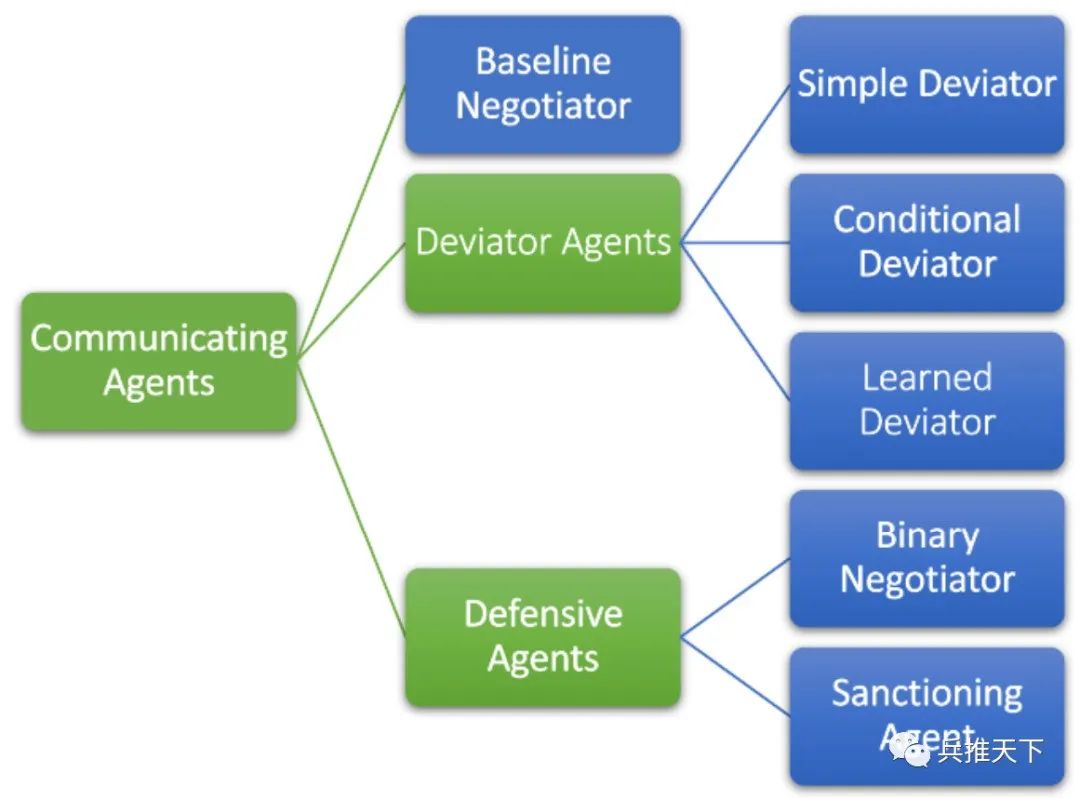
所有类型的沟通代理,位于绿色方框中,蓝色方框代表具体代理算法。
研究表明,普通和有条件背离者的表现优于基线协商者。而且有条件背离者的表现是压倒性的。
鼓励代理诚实守信
接下来,我们通过防御性代理解决了违背协议的问题,他们会就背离行为采取不利于背离者的应对方式。我们研究了二元谈判者,他们的做法很简单,即切断与违反协议的代理人的沟通。
但回避是一种温和的反应,所以我们也开发了制裁代理,他们不会对背叛掉以轻心,而是会修改自己的目标,积极尝试各种降低背离者价值的方法--一个记仇的对手!研究表明,这两类防御性代理作出的反应,都会对背离者产生不利影响!而且这两种类型的防御性代理都会削弱不履行承诺行为带来的优势,特别是制裁性代理。
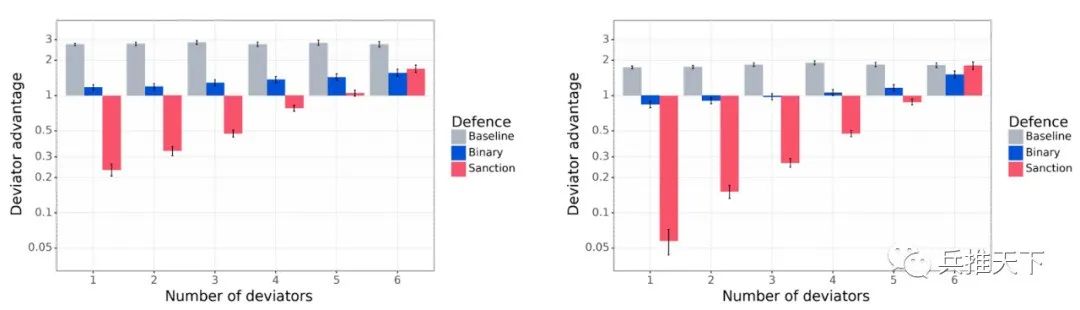
非背离代理(基线谈判者、二元谈判者和制裁代理)与有条件偏离者进行博弈。左图:相互提议协议。右图: 提议-选择协议。"背离者优势 "值低于1,表明防御性代理的表现优于背离代理。与基线谈判者(灰色)相比,二元谈判者(蓝色)群体削弱了偏离者的优势。
最后,我们引入了学习型背离者,他们在多次推演中为对抗制裁代理适应并优化了自己的行为,试图使上述防御措施失去效力。学习型背离者只有当背离的直接收益足够高,而其他代理人的报复能力足够低的情况下才会违背协议。
在实践中,学习型背离者有时会在推演后期破坏协议,并在此过程中取得对制裁代理的轻微优势。尽管如此,这种制裁促使学习型背离者会履行99.7%以上的协议内容。
我们还研究了制裁和背离的可能学习动态:当制裁代理也可能违背协议时会发生什么,以及当制裁代价高昂时停止这种行为的潜在激励措施是什么。这些问题会逐渐削弱合作,因此可能需要额外的机制,如在多次推演中重复互动或使用信任和声誉系统。
我们还留下许多未解决的问题待未来研究:是否有可能设计更复杂的协议来鼓励更诚实行为?如何处理通信技术和不完善信息的结合?最后,还有什么机制可以阻止违反协议的行为?建立公平、透明和可信赖的人工智能系统是一个极其重要的话题,这也是DeepMind的重要使命。
在“外交”兵棋这样的沙盒中研究这些问题有助于我们更好地理解现实世界中可能存在的合作与竞争之间的紧张关系。最终,我们相信解决这些挑战可以让我们更好地理解如何根据社会价值观和优先事项来开发人工智能系统。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









