







来源:学术头条
自 Sora 发布以来,国内外各大科技公司和研究机构都在竞相推出“文生视频”大模型,比如生数科技的 Vidu、快手的可灵和 Runway 昨天才发布的 Gen-3 Alpha 等。
然而,目前许多系统只能生成无声输出,在视频生成过程中,为视频生成栩栩如生、同步的音频,亦是一个不可忽视的关键环节,它不仅关系到视频内容的质感和真实感,还影响到信息的传递和用户的体验。
同样在昨天,Google DeepMind 分享了他们在“视频生音频”方面的新进展——V2A,使同步视听生成成为可能。
据介绍,V2A 将视频像素与自然语言文本提示相结合,为屏幕上的动作生成丰富的音效。这一技术可与视频生成模型搭配使用,从而创建具有逼真音效或对话的镜头,从而与视频中的角色和基调相匹配。
V2A 还可以为各种传统素材(包括档案资料、无声电影等)生成配乐,从而为创作提供更多机会。
以下是 Google DeepMind 官网上的几个配音 demo:
提示:电影、惊悚片、恐怖片、音乐、紧张、氛围、混凝土上的脚步声
提示:音乐会舞台上的鼓手,周围是闪烁的灯光和欢呼的人群
提示:草原上夕阳西下,口琴声悠扬婉转
增强的创意控制
Google DeepMind 表示,重要的是,V2A 可以为任何视频输入生成数量不限的配乐。此外,V2A 还可以定义“积极提示”,引导生成的输出朝着所需的声音方向发展,或定义“消极提示”,引导输出远离不想要的声音。
这种灵活性使用户可以对 V2A 的音频输出进行更多的控制,从而可以快速尝试不同的音频输出并选择最佳匹配。
提示:宇宙飞船在浩瀚的太空中疾驰,星星从它身边划过,高速,科幻
提示:空灵的大提琴氛围
V2A 技术是如何实现的?
据介绍,为发现最具可扩展性的人工智能架构,研究团队尝试了自回归和扩散方法,他们发现,基于扩散的音频生成方法在同步视频和音频信息方面给出了更真实、更令人信服的结果。
V2A 系统首先将视频输入编码为压缩表示;然后,扩散模型从随机噪声中迭代改进音频。这一过程在视觉输入和自然语言提示的引导下,生成与提示紧密对齐的同步逼真音频;最后,对音频输出进行解码,将其转化为音频波形,并与视频数据相结合。
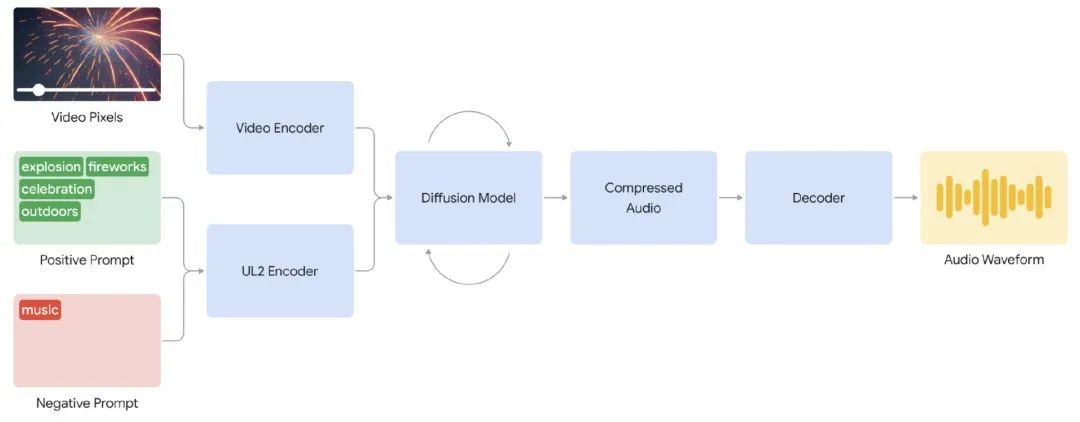
图|V2A 系统示意图,该系统利用视频像素和音频提示输入生成与底层视频同步的音频波形。首先,V2A 对视频和音频提示输入进行编码,并通过扩散模型反复运行。然后生成压缩音频,并解码为音频波形。
为了生成更高质量的音频,并增加引导模型生成特定声音的能力,研究团队在训练过程中添加了更多信息,包括人工智能生成的注释,其中包含声音的详细描述和口语对话记录。
通过对视频、音频和附加注释进行训练,V2A 系统学会了将特定音频事件与各种视觉场景联系起来,同时对注释或文本中提供的信息做出响应。
还需要进一步研究
与现有的“视频生音频”解决方案不同,V2A 系统可以理解原始像素,而且可以选择添加文字提示。
此外,该系统无需手动将生成的声音与视频对齐,因为手动对齐需要繁琐地调整声音、视觉和时间等不同元素。
不过,研究团队表示,他们还在努力解决其他一些限制因素,进一步的研究正在进行中。
例如,由于音频输出的质量取决于视频输入的质量,因此视频中超出模型训练分布范围的伪影或失真会导致音频质量明显下降。
此外,他们还在改进语音视频的唇语同步。V2A 会尝试从输入文本中生成语音,并与人物的唇部动作同步。但是,配对视频生成模型可能并不是基于或受输入的文本所限制或影响的。这就造成了不匹配,往往会导致不可思议的唇部同步,因为视频模型生成的嘴部动作无法与文字相匹配。
提示:音乐,文字“这火鸡看起来太棒了,我好饿。”
相关链接:
https://deepmind.google/discover/blog/generating-audio-for-video/
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









