







引子
啊~最有个小姐姐要做微信公众号,她需要优质的句子、文章,于是我想到了网易云每首伤感歌曲下面的评论,嗯~很感人,甚至有的时候真的感觉这里就是能触及我心灵最柔软的地方,正好这几天在学习python,于是我开始了我精彩的表演
准备
好像没什么可准备的,我是win10操作系统、python 3.6.4、浏览器用的自带的edge和chrome
开始
分析测试
初探
打开浏览器,网易云音乐>>排行榜>>云音乐热搜榜>>随便打开一首歌>>F12进入开发人员工具,刷新页面

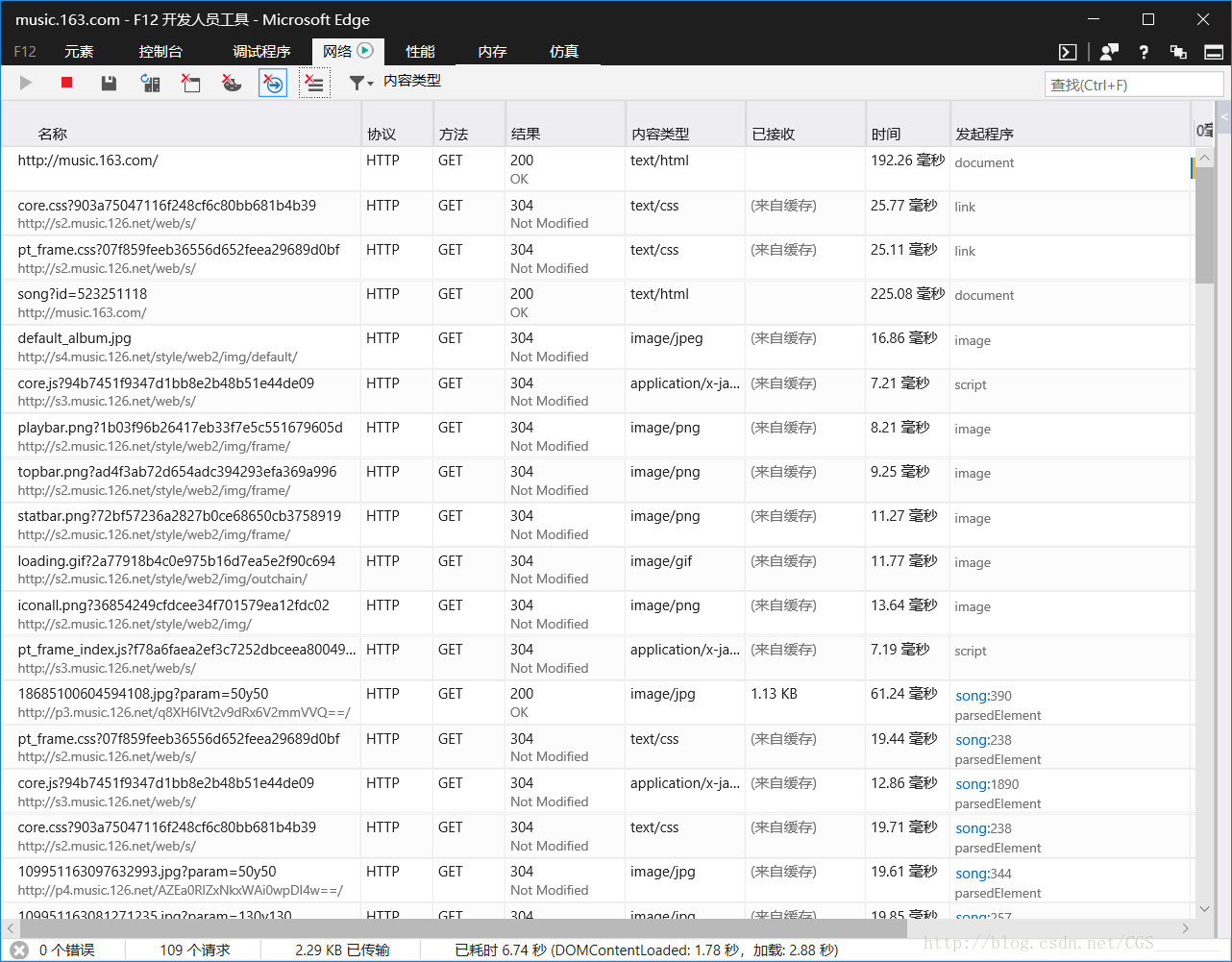
从上图的F12开发人员工具截图中我们可以看到,很多的链接,我们一个一个去找到底是哪个链接的正文响应返回了评论信息,下图中我们在某个链接中找到了包含评论的
响应正文,和请求正文
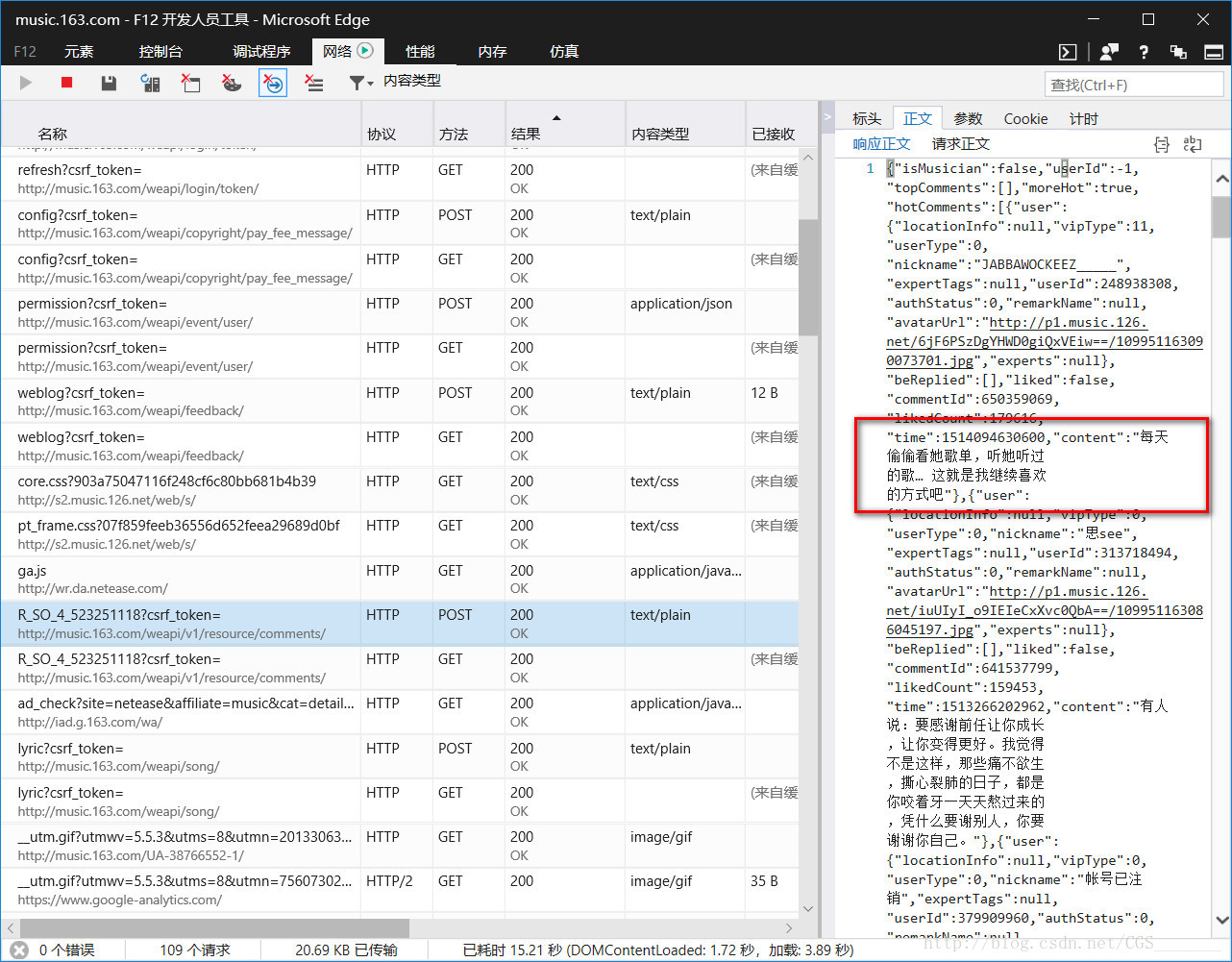

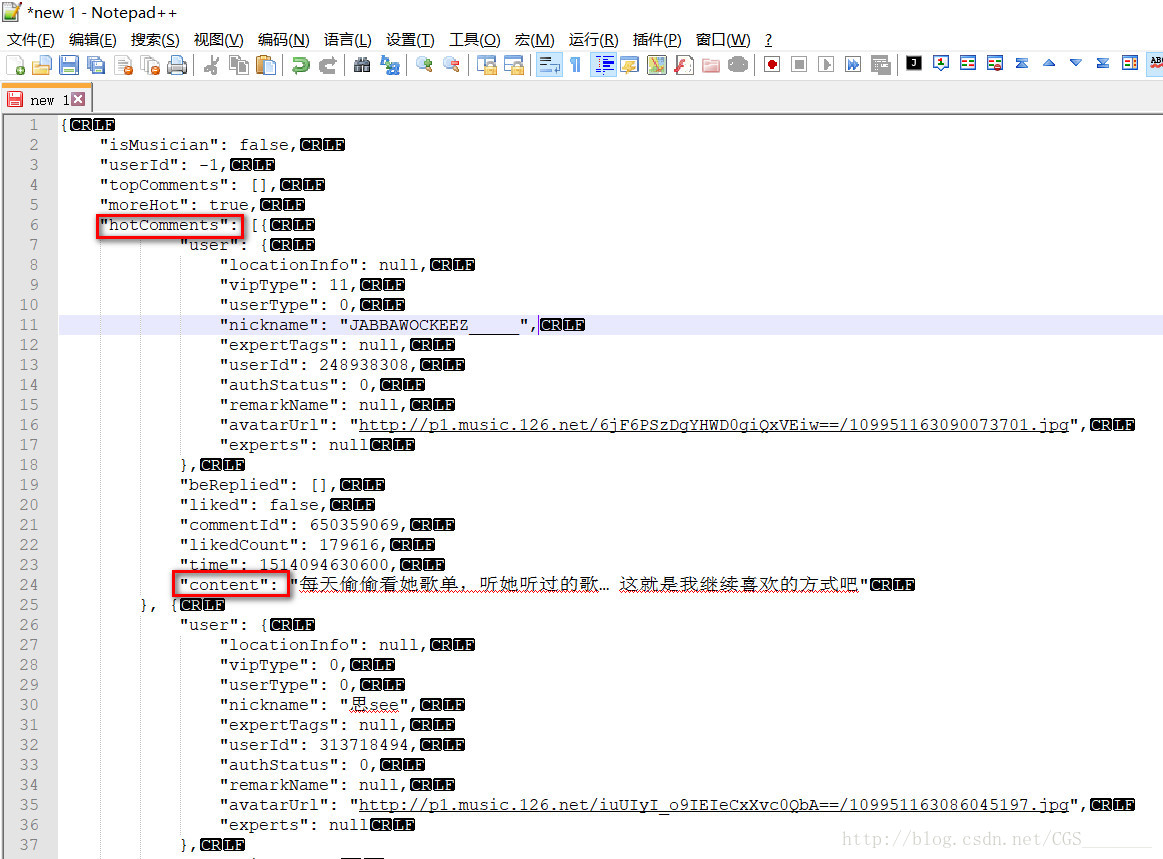
将上图中响应正文的文本拷贝到notepad++中格式化,格式化后我们观察到
评论是在hotComments节点下的content的值
探果
通过上面的查探,我们可以得出以下几个有用的信息:
1.该歌曲的链接http://music.163.com/#/song?id=523251118
后面的id应该表示歌曲的id
2.返回包含评论的响应正文的链接为http://music.163.com/weapi/v1/resource/comments/R_SO_4_523251118?csrf_token= 并且链接中
R_SO_4_后面的数字,可以看出就是这首歌曲的id
3.评论在响应正文
的hotComments节点下的content
4.请求正文中的两个参数
encSecKey和params
通过上面得出的信息,我们可以简单的写个脚本测试一下
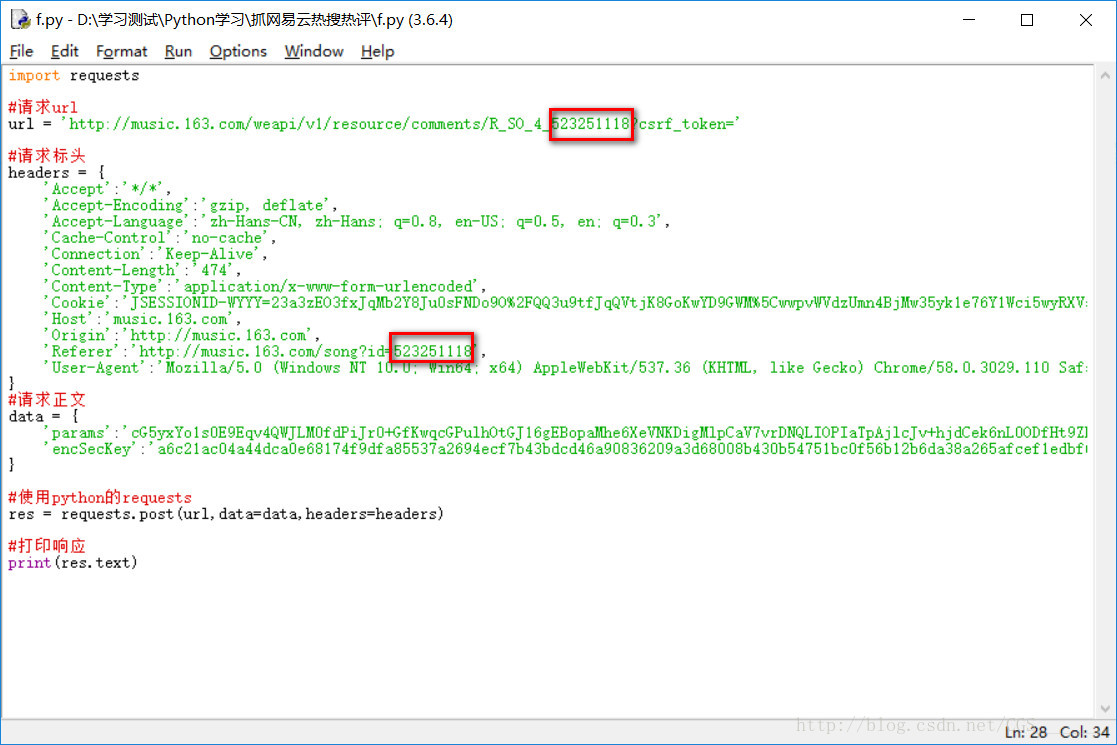
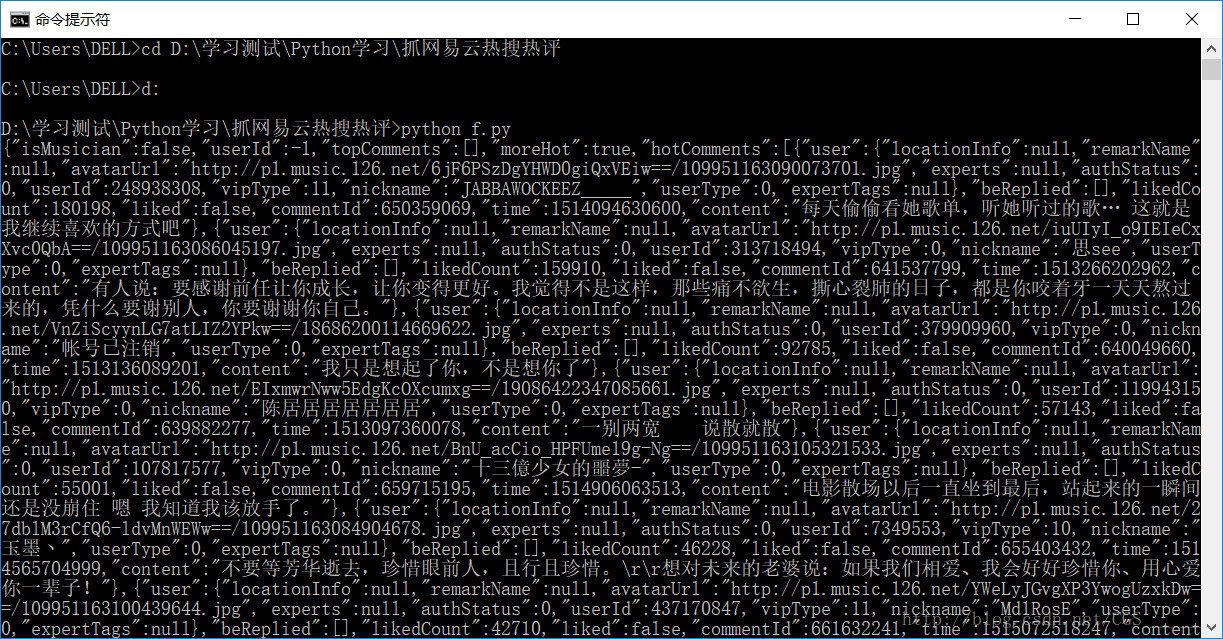
从上图中我们可以看到可以正常接受我们想要的响应正文,用红框圈出来的是这首歌曲的id,那么现在我们只是获取到了一首歌的评论,要想获取热搜榜搜友歌曲的评论,就需要获得
所有歌曲的id,然后执行遍历就好了
接下来我们就去搞所有的歌曲,获取所有热搜榜歌曲的id
再探
打开网易云音乐>>排行榜>>云音乐热搜榜>>F12开发人员工具>>刷新>>找到包含热搜榜歌曲的响应正文的链接
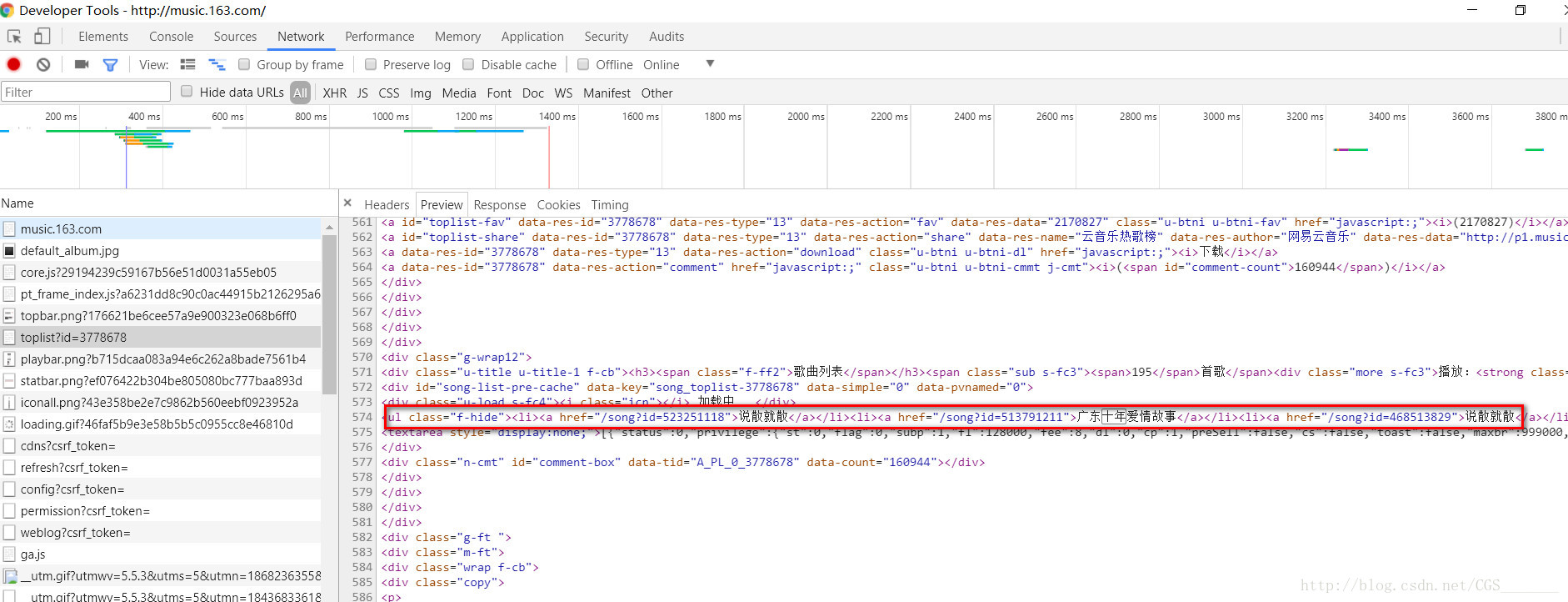
观察上面的<ul>标签,我们发现里面的<a>标签的href属性值就是我们想要获得的歌曲id,现在id有了但是又不是单纯的歌曲id列表,所以我们要用正则表达式匹配所有的歌曲名字和id,像这样
#使用正则表达式匹配正文响应
reg1 = r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>'
result_contain_songs_ul = re.compile(reg1).findall(r.text)
result_contain_songs_ul = result_contain_songs_ul[0]
reg2 = r'<li><a href="/song\?id=\d*?">(.*?)</a></li>'
reg3 = r'<li><a href="/song\?id=(\d*?)">.*?</a></li>'
hot_songs_name = re.compile(reg2).findall(result_contain_songs_ul)
hot_songs_id = re.compile(reg3).findall(result_contain_songs_ul)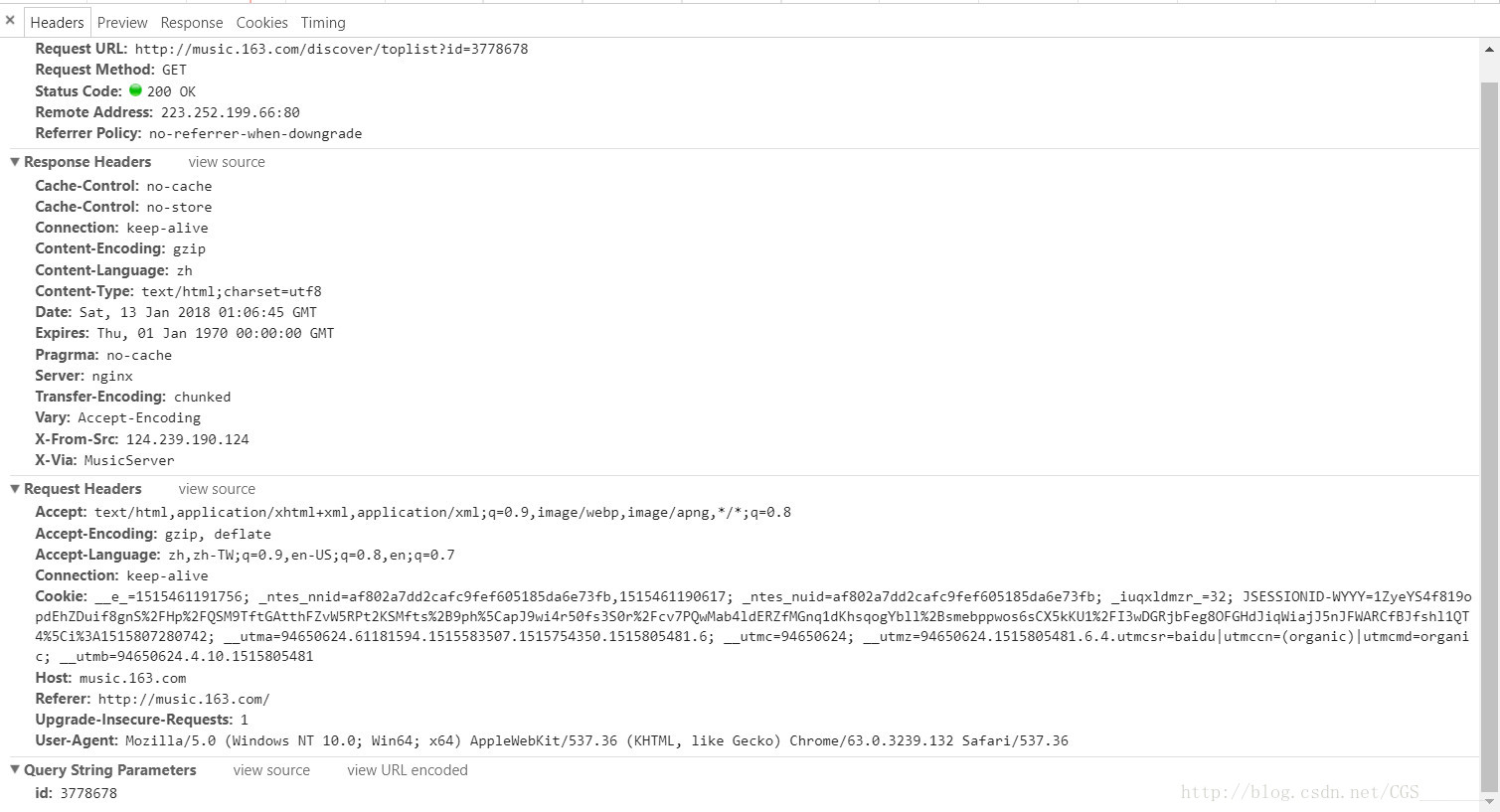
探果
通过第二次观察我们得出以下信息:
1.网易云音乐热搜榜链接 http://music.163.com/discover/toplist?id=3778678
2.请求标头没有额外的信息
3.歌曲名和id需要用正则表达式匹配
好了,通过两次的观察和分析我们可以开始写脚本了,再来简单测试一下(算了直接贴代码了)
代码
import re
import requests
import json
def get_all_hotsongs():
"""抓热搜榜所有歌曲"""
url = 'http://music.163.com/discover/toplist?id=3778678'
headers = {
'Cookie':'__e_=1515461191756; _ntes_nnid=af802a7dd2cafc9fef605185da6e73fb,1515461190617; _ntes_nuid=af802a7dd2cafc9fef605185da6e73fb; JSESSIONID-WYYY=HMyeRdf98eDm%2Bi%5CRnK9iB%5ChcSODhA%2Bh4jx5t3z20hhwTRsOCWhBS5Cpn%2B5j%5CVfMIu0i4bQY9sky%5CsvMmHhuwud2cDNbFRD%2FHhWHE61VhovnFrKWXfDAp%5CqO%2B6cEc%2B%2BIXGz83mwrGS78Goo%2BWgsyJb37Oaqr0IehSp288xn5DhgC3Cobe%3A1515585307035; _iuqxldmzr_=32; __utma=94650624.61181594.1515583507.1515583507.1515583507.1; __utmc=94650624; __utmz=94650624.1515583507.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmb=94650624.4.10.1515583507',
'Host':'music.163.com',
'Refere':'http://music.163.com/',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
r = requests.get(url,headers=headers)
#使用正则表达式匹配正文响应
reg1 = r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>'
result_contain_songs_ul = re.compile(reg1).findall(r.text)
result_contain_songs_ul = result_contain_songs_ul[0]
reg2 = r'<li><a href="/song\?id=\d*?">(.*?)</a></li>'
reg3 = r'<li><a href="/song\?id=(\d*?)">.*?</a></li>'
hot_songs_name = re.compile(reg2).findall(result_contain_songs_ul)
hot_songs_id = re.compile(reg3).findall(result_contain_songs_ul)
#返回歌曲名 歌曲id
return hot_songs_name,hot_songs_id
def get_hotcommnets(hot_songs_name,hot_songs_id):
"""抓热搜榜歌曲热评"""
url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_'+hot_songs_id+'?csrf_token='
headers = {
'Host':'music.163.com',
'Proxy-Connection':'keep-alive',
'Origin':'http://music.163.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)',
'Content-Type':'application/x-www-form-urlencoded',
'Accept':'*/*',
'Referer':'http://music.163.com/song?id='+hot_songs_id+'',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh,zh-TW;q=0.9,en-US;q=0.8,en;q=0.7',
'Cookie':'__e_=1515461191756; _ntes_nnid=af802a7dd2cafc9fef605185da6e73fb,1515461190617; _ntes_nuid=af802a7dd2cafc9fef605185da6e73fb; _iuqxldmzr_=32; __utmc=94650624; __utmz=94650624.1515628584.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; JSESSIONID-WYYY=TO%2BtUvrTWONNwB%2BgzDpfjFDiggKiS%2FfpMYNam%2BWGooHNka%2BwMhdsT%5CY%2Fn%2FpSMJwo4skFIK1T%2FNjd95lbGHWMQr5d5qcMRPB9SVKWK8UuBs1OGugZ4lFwipwjwWbCepSw%5CjWv31i1Qt%5CWWwtrFzzktj8CdCzniAw%5CgFCElUJnsQygY0MA%3A1515635604215; __utma=94650624.61181594.1515583507.1515630648.1515633862.4; __utmb=94650624.2.10.1515633862'
}
data = {
'params':'cG5yxYo1s0E9Eqv4QWJLM0fdPiJr0+GfKwqcGPulhOtGJ16gEBopaMhe6XeVNKDigMlpCaV7vrDNQLIOPIaTpAjlcJv+hjdCek6nL0ODfHt9ZEmtkTmU4r/+SA6Vno+o+c4EaPvhghNUXRMdVM/LltKvVanwOSvVhcqUPw9qij1d1akcxweLOWf1hKh2/q/m',
'encSecKey':'a6c21ac04a44dca0e68174f9dfa85537a2694ecf7b43bdcd46a90836209a3d68008b430b54751bc0f56b12b6da38a265afcef1edbf687d70d1eb853144e920fea28e19a8c6145b7bad33e40d077e8a689b4bf67b367db815278af4ef227b02d85e609007106b7fc4a547bf96a1b90b0eda85bca6cc79ca6fc6559d00060d4184'
}
#postdata = data.encode('utf-8')
response = requests.post(url,data=data,headers=headers)
#print(response.text)
#格式化响应正文hotComments热评节点
hotcomments = json.loads(response.text)['hotComments']
#print(hotcomments)
#遍历热评内容 保存到当前目录文本
num = 0
with open('./song_comments.txt','a',encoding='utf-8') as f:
f.write('《'+hot_songs_name+'》:'+'\n')
for i in hotcomments:
num+=1
#print(str(num))
f.write(str(num)+'.'+i['content']+'\n')
#f.write(i['content']+'\n')
f.write('\n====================================================\n\n')
#调用方法 获得歌曲名 歌曲id
hot_songs_name,hot_songs_id = get_all_hotsongs()
#print(len(hot_songs_name))
#循环遍历抓取所有热搜热评
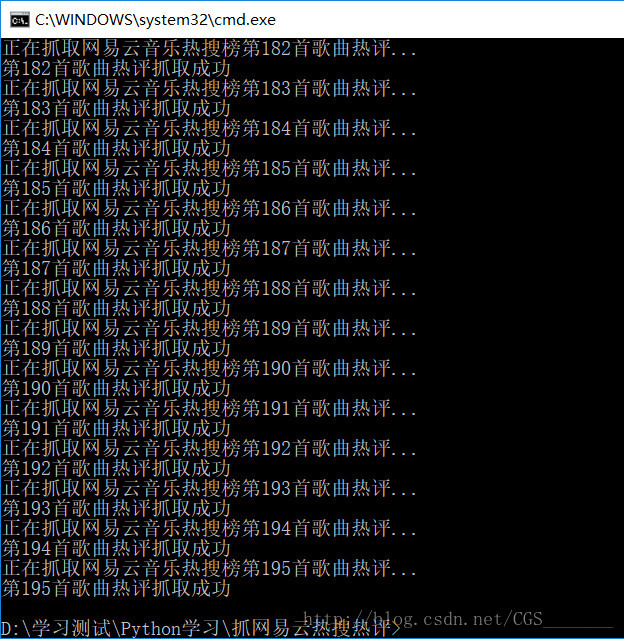
num = 0
while num < len(hot_songs_name):
print('正在抓取网易云音乐热搜榜第%d首歌曲热评...'%(num+1))
get_hotcommnets(hot_songs_name[num],hot_songs_id[num])
print('第%d首歌曲热评抓取成功'%(num+1))
num+=1
#print(hot_songs_name[0],hot_songs_id[0])
#get_hotcommnets(hot_songs_name[0],hot_songs_id[0])















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









