






并发:多个进程或线程同时(或者说在同一段时间内)访问同一资源会产生并发问题。
高并发(High Concurrency)是一种系统运行过程中遇到的一种“短时间内遇到大量操作请求”的情况,主要发生在web系统集中大量访问收到大量请求(例如:12306的抢票情况;天猫双十一活动)。该情况的发生会导致系统在这段时间内执行大量操作,例如对资源的请求,数据库的操作等。
在这些情形下,服务器端将面临极大的请求压力,通常出现响应时间增加,甚至于服务器因处理压力过大造成宕机的局面。如果要想系统能够适应高并发状态,则需要从各个方面进行系统优化,包括,硬件、网络、系统架构、开发语言的选取、数据结构的运用、算法优化、数据库优化等……
硬件角度
通过增加内存、 CPU核数、存储容量、或者将磁盘 升级成SSD 等堆硬件的方式提升单机的硬件性能。这种解决方式很直接,但最主要的缺点是随着业务的不断增加,服务器性能很快又到达瓶颈,所以从架构或者算法的角度出发可以在相同成本下更好的解决高并发的问题。
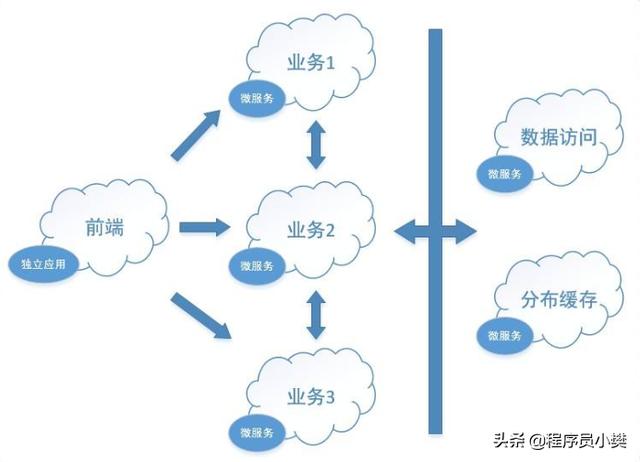
系统拆分
将一个系统进行功能拆分,如现在流行的微服务,每个服务连接的数据库分开,分开部署。这样可以将压力进行拆分,缓解因为网络和数据库导致的高并发
使用基于内存的缓存
在日常对数据库的访问中,读操作的次数远超写操作,比例大概在 1:9 到 3:7,所以需要读的可能性是比写的可能大得多的。当我们使用SQL语句去数据库进行读写操作时,数据库就会去磁盘把对应的数据索引取回来,这是一个相对较慢的过程。
如果我们把数据放在 Redis 中,也就是直接放在内存之中,让服务端直接去读取内存中的数据,那么这样速度明显就会快上不少,并且会极大减小数据库的压力,但是使用内存进行数据存储开销也是比较大的,限于成本的原因,一般我们只是使用 Redis 存储一些常用和主要的数据,比如用户登录的信息等。
使用 Redis 作为缓存的读取逻辑如下:
- 当第一次读取数据的时候,此时缓存中并没有需要的数据,读取 Redis 的数据就会失败,此时就会触发程序读取数据库,把数据读取出来,并且写入 Redis 中。
- 当第二次以及以后需要读取数据时,就会直接读取 Redis,读到数据后就结束了流程,这样速度就大大提高了。
Redis 来应对这样的高并发需求的场合,我们先来看看一次请求操作的流程图:
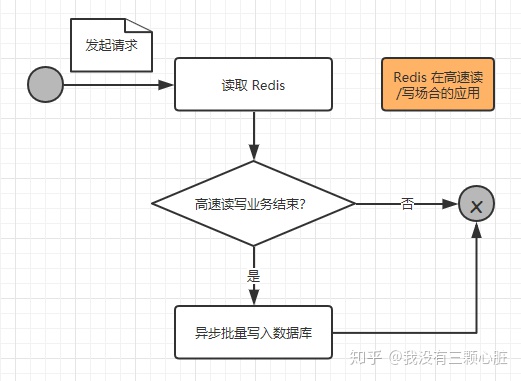
- 当一个请求到达服务器时,只是把业务数据在 Redis 上进行读写,而没有对数据库进行任何的操作,这样就能大大提高读写的速度,从而满足高速响应的需求;
- 但是这些缓存的数据仍然需要持久化,也就是存入数据库之中,所以在一个请求操作完 Redis 的读/写之后,会去判断该高速读/写的业务是否结束,这个判断通常会在秒杀商品为0,红包金额为0时成立,如果不成立,则不会操作数据库;如果成立,则触发事件将 Redis 的缓存的数据以批量的形式一次性写入数据库,从而完成持久化的工作。
使用消息中间件
消息队列(Message Queue,简称MQ),指保存消息的一个容器,本质是个队列。
首先介绍一个高并发的场景。在我们秒杀抢购商品的时候,同时也有很多用户卡点发出请求,这时系统会提醒我们稍等排队中,而不是像几年前一样页面卡死或报错给用户。
像这种排队结算就用到了消息队列机制,放入通道里面一个一个结算处理,而不是某个时间段突然涌入大批量的查询新增把数据库给搞宕机
当数据库面临大量请求时,可以将大量的写请求灌入 MQ 里,进行排队,后边系统慢慢写,控制在数据库承载范围之内。
目前常用的中间件有Kafka、ActiveMQ、RabbitMQ、RocketMQ 等。
关于这些中间件的特点与应用,请移步:
消息中间件(一)MQ详解及四大MQ比较_jcpp9527的博客-CSDN博客
MQ选型:ActiveMQ、RocketMQ、RabbitMQ、Kafka对比_哪个mq用的最多_老树临风_的博客-CSDN博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









