




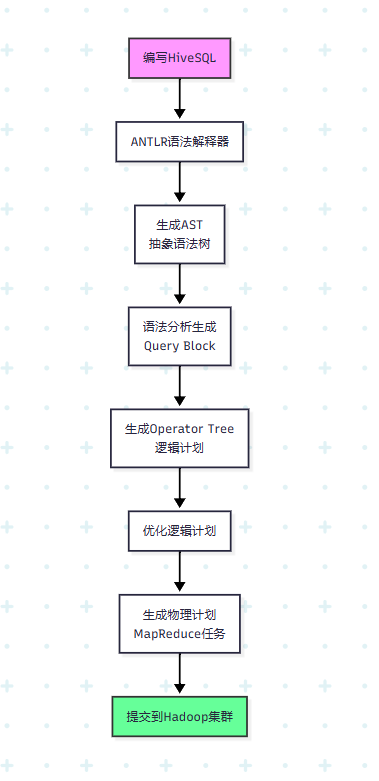
标题hive的执行流程
1.我们写hivesql,语法解释器antlr将sql解释称AST(抽象语法树)
2.语法分析生成query block
3.逻辑计划生成operator tree
4.优化逻辑计划
5.生成物理计划,也就是mr任务
6.提交到Hadoop
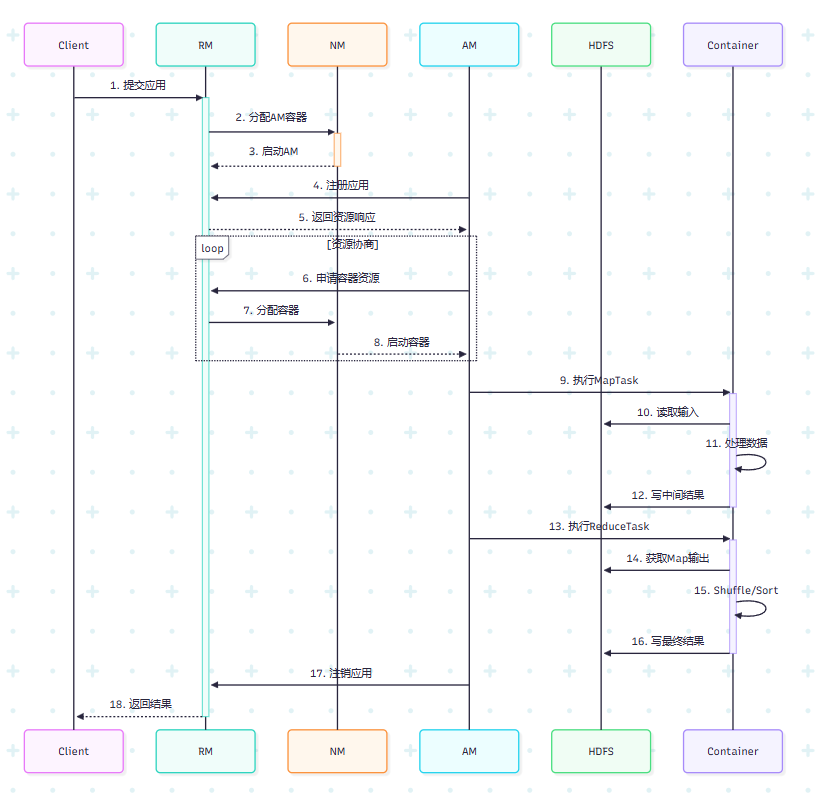
标题mapreduce的执行流程
1.客户端与RM建立连接,提交应用
2.rm在nm分配am容器
3.nm启动am
4.am向rm注册
5.rm向am返回资源响应
6.am申请资源
7.rm在nm上分配容器
8.nm向am报告启动容器
9.执行maptask
10.执行reducetask
11.am向rm注销
12.rm向client返回结果
标题spark的执行流程
1.客户端与RM建立连接,提交应用
2.RM给NM分配容器
3.NM启动AM,AM也担任Driver
4.AM向RM注册
5.RM向AM返回资源响应
6.AM向RM申请资源
7.RM在NM上分配容器
8.NM启动Executor
9.Executor向AM注册
10.AM发送任务代码和配置给Executor
11.Executor从hdfs获取jar
12.Executor执行任务,报告给Driver
13.写结果到HDFS
14.AM向RM注销
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











