






HANA内存数据库简介
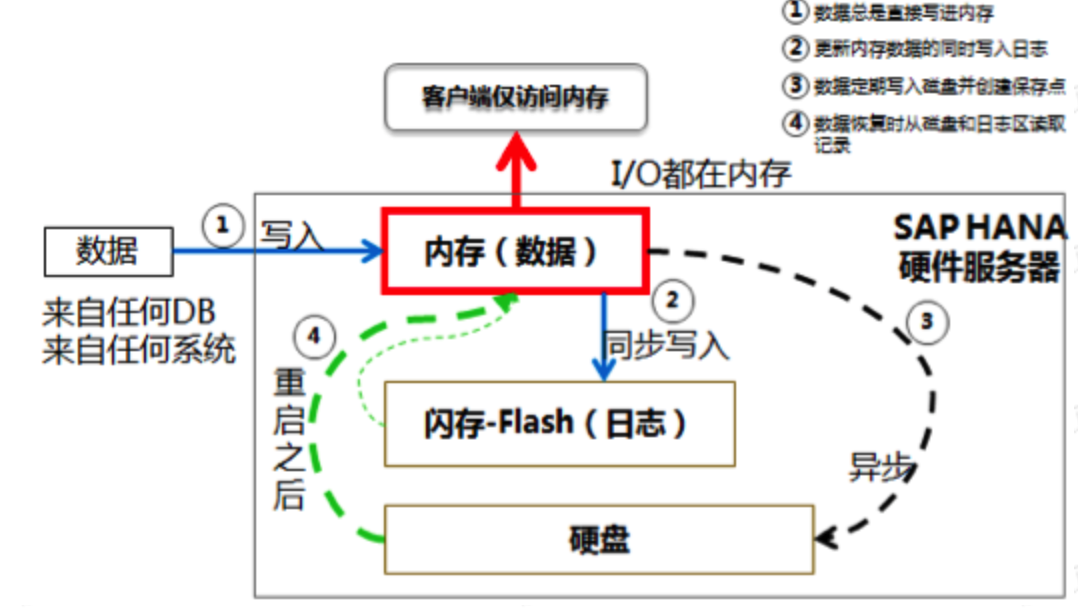
SAP HANA是一个软硬件结合体,提供高性能的数据操作功能。HANA 的精髓就是把所有的数据放到内存里——离处理数据最近的地方,也是计算机全身除了CPU 速度最快的地方。而不像传统数据库,数据放在硬盘里,走过复杂的读操作,走过系统总线,在内存里被短暂的处理,然后再走过同样的路回去,躺在硬盘里。HANA的基本原理如下图所示:

HANA内存数据库简介
SAP HANA是一个软硬件结合体,提供高性能的数据操作功能。HANA 的精髓就是把所有的数据放到内存里——离处理数据最近的地方,也是计算机全身除了CPU 速度最快的地方。而不像传统数据库,数据放在硬盘里,走过复杂的读操作,走过系统总线,在内存里被短暂的处理,然后再走过同样的路回去,躺在硬盘里。HANA的基本原理如下图所示:
 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























