







我们基本每天都在通过WEB浏览器,去浏览一些新闻,看看视频之类的。
众所周知,这就是所谓的B/S结构(Browser/Server,浏览器/服务器模式),是WEB兴起后的一种网络结构模式,WEB浏览器是客户端最主要的应用软件。
那顺道就来简单的看一下,所谓的Web服务器(例如知名的Tomcat)与浏览器,基本的实现原理是什么样的呢?
首先可以明确的就是,例如我们所做的通过浏览器输入一个地址,访问一个网页的操作。
实际对应的底层操作简单来说就是:客户端(浏览器)面向于WEB服务器的网络通信。
那么,既然是网络通信。对应于Java当中来说,就自然离不开Socket与IO流。其实这也正是Web服务器与浏览器的基础实现原理。
当然,想要开发一套完善的WEB服务器或浏览器,需要做的工作是很复杂的。但这里,我们想要了解的,只是其原理。
我们知道,将开发的web项目部署到tomcat服务器之后,就可以通过浏览器对服务器上的资源进行访问。
但重要的一点是,存在多种不同厂商开发的不同浏览器。但各个类型的WEB浏览器,都可以正常的访问tomcat服务器上的资源。
对此,我们可以这样理解:我开发了一个WEB服务器,并且能够保证其他人开发的客户端都能够与我的服务器正常通信。
能够实现这样的目的的前提自然就是,你要制定一个规范,并让想要与你开发的服务器正常进行通信的客户端都遵循这个规范来实现。
这个规范,也就是所谓的协议。
所以,正如在网络通信中,数据的传输可以遵循TCP/IP或UDP协议一样。
WEB服务器与WEB浏览器之间,也通过一种双方都熟悉的语言进行通信。
这种协议即是:超文本传输协议,也就是HTTP协议。
不同的是,TCP/IP与UDP议是传输层当中的通信协议,而HTTP协议是应用层当中的协议。
所以,当我们想要使用Java语言实现所谓的WEB通信,自然也应当遵循HTTP协议。
Java中已经为我们提供了这样的一种实现规范,也就是广为人知的:Servlet接口。
而我们开发web项目时,最常用到的HttpServlet类,就是基于此接口实现的具体子类。
该类封装和提供了,针对基于Http协议通信的内容进行访问和操作的常用方法。
说了这么多,我们通过一些小的实例,方便进行更形象的理解。
首先,我们通过一段简单的Servlet代码来看一下,基于HTTP协议进行WEB通信的请求信息:
- public class ServletTest extends HttpServlet {
- public void doGet(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
- for (Enumeration e = request.getHeaderNames(); e.hasMoreElements();) {
- String header = (String) e.nextElement();
- if (header != null)
- System.out.println((new StringBuilder(String.valueOf(header)))
- .append(":").append(request.getHeader(header))
- .toString());
- }
- }
- public void doPost(HttpServletRequest request, HttpServletResponse response)
- throws ServletException, IOException {
- }
- }
来打印web浏览器基于http协议发起的请求当中,封装的HTTP请求详情。程序输出的结果如下:

一个HTTP协议的请求中,通常主要包含三个部分:
- 方法/统一资源标示符(URI)/协议/版本
- 请求标头
- 实体主体
其中方法也就是所谓的get/post之类的请求方法,统一资源标示符也就是要访问的目标资源的路径,包括协议及协议版本,这些信息被放在请求的第一行。
随后,紧接着的便是请求标头;请求标头通常包含了与客户端环境及请求实体主体相关的有用信息。
最后,在标头与实体主体之间是一个空行。它对于HTTP请求格式是很重要的,空行告诉HTTP服务器,实体主体从这里开始。
前面已经说过了,我们这里想要研究的,是WEB服务器的基本实现原理。
那么我们自然想要自己来实现一下所谓的WEB服务器,我们已经知道了:
所谓的B/S结构,实际上就是客户端与服务器之间基于HTTP协议的网络通信。
那么,肯定是离不开socket与io的,所以我们可以简单的模拟一个最简易功能的山寨浏览器:
- public class MyTomcat {
- public static void main(String[] args) {
- try {
- ServerSocket tomcat = new ServerSocket(9090);
- System.out.println("服务器启动");
- //
- Socket s = tomcat.accept();
- //
- byte[] buf = new byte[1024];
- InputStream in = s.getInputStream();
- //
- int length = in.read(buf);
- String request = new String(buf,0,length);
- //
- System.out.println(request);
- } catch (IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }

通过成果我们看到,我们已经成功的简单山寨了一下tomcat。
不过这里需要注意的是,我们自己山寨的tomcat服务器当中,之所以也成功的输出了Http协议的请求体,是因为:
我们是通过web浏览器进行访问的,如果通过普通的socket进行对serversocket的连接访问,是没有这些请求信息的。
因为我们前面已经说过了,web浏览器与服务器之间的通信必须遵循Http协议。
所以,我们日常生活中使用的web浏览器,会自动的为我们的请求进行基于http协议的包装。
但是,因为我们已经了解了原理,所以我们也可以自己模拟一下浏览器过过瘾:
- //山寨浏览器
- public class MyBrowser {
- public static void main(String[] args) {
- try {
- Socket browser = new Socket("192.168.1.102", 9090);
- PrintWriter pw = new PrintWriter(browser.getOutputStream(),true);
- // 封装请求第一行
- pw.println("GET/ HTTP/1.1");
- // 封装请求头
- pw.println("User-Agent: Java/1.6.0_13");
- pw.println("Host: 192.168.1.102:9090");
- pw
- .println("Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2");
- pw.println("Connection: keep-alive");
- // 空行
- pw.println();
- // 封装实体主体
- pw.println("UserName=zhangsan&Age=17");
- // 写入完毕
- browser.shutdownOutput();
- // 接受服务器返回信息,
- InputStream in = browser.getInputStream();
- //
- int length = 0;
- StringBuffer request = new StringBuffer();
- byte[] buf = new byte[1024];
- //
- while ((length = in.read(buf)) != -1) {
- String line = new String(buf, 0, length);
- request.append(line);
- }
- System.out.println(request);
- //browser.close();
- } catch (IOException e) {
- System.out.println("异常了,操!");
- }finally{
- }
- }
- }
- //修改后的山寨tomcat服务器
- public class MyTomcat {
- public static void main(String[] args) {
- try {
- ServerSocket tomcat = new ServerSocket(9090);
- System.out.println("服务器启动");
- //
- Socket s = tomcat.accept();
- //
- byte[] buf = new byte[1024];
- InputStream in = s.getInputStream();
- //
- int length = 0;
- StringBuffer request = new StringBuffer();
- while ((length = in.read(buf)) != -1) {
- String line = new String(buf, 0, length);
- request.append(line);
- }
- //
- System.out.println("request:"+request);
- PrintWriter pw = new PrintWriter(s.getOutputStream(),true);
- pw.println("<html>");
- pw.println("<head>");
- pw.println("<title>LiveSession List</title>");
- pw.println("</head>");
- pw.println("<body>");
- pw.println("<p style=\"font-weight: bold;color: red;\">welcome to MyTomcat</p>");
- pw.println("</body>");
- s.close();
- tomcat.close();
- } catch (IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
我们先启动服务器,然后运行浏览器模拟网页浏览的过程,首先看到服务器端收到的请求信息:
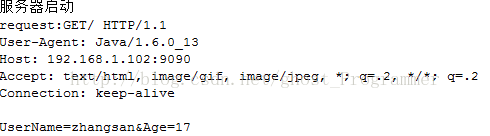
紧接着,服务器收到请求进行处理后,返回资源给浏览器,于是得到输出信息:

可以看到,我们在山寨浏览器当中得到的返回信息,实际上就是一个HTML文件的源码,
之所以我们的山寨浏览器中,这些信息仅仅是以纯文本形式显示,是因为我们的山寨浏览器不具备解析HTML语言的能力。
所以说,浏览器另外一个重要的功能其实就是:可以对超文本标记语言进行解析。而实际上,这也是浏览器开发的难点和重点。
上面这样的输出结果看上去显然不爽,所以说山寨货毕竟还是坑爹!
我们还是通过正规的WEB浏览器,来试着访问一下我们的山寨服务器,结果发现,效果帅多了:

而顺带一提的是,既然当浏览器向WEB服务器发起访问请求时,会封装有对应的HTTP请求体。
那么,对应的,当WEB服务器处理完浏览器请求,返回数据时,也会有对应的封装,就是所谓的HTTP响应体。
举例来说,假如我们将我们的山寨浏览器的代码进行修改,去连接真正的tomcat服务器:
- public class MyBrowser {
- public static void main(String[] args) {
- try {
- Socket browser = new Socket("192.168.1.102", 8080);
- PrintWriter pw = new PrintWriter(browser.getOutputStream(),true);
- // 封装请求第一行
- pw.println("GET / HTTP/1.1");
- // 封装请求头
- pw.println("User-Agent: Java/1.6.0_13");
- pw.println("Host: 192.168.1.102:8080");
- pw
- .println("Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2");
- pw.println("Connection: keep-alive");
- // 空行
- pw.println();
- // 封装实体主体
- //pw.println("UserName=zhangsan&Age=17");
- // 写入完毕
- browser.shutdownOutput();
- // 接受服务器返回信息,
- InputStream in = browser.getInputStream();
- //
- int length = 0;
- StringBuffer request = new StringBuffer();
- byte[] buf = new byte[1024];
- //
- while ((length = in.read(buf)) != -1) {
- String line = new String(buf, 0, length);
- request.append(line);
- }
- System.out.println(request);
- //browser.close();
- } catch (IOException e) {
- System.out.println("异常了,操!");
- }finally{
- }
- }
- }
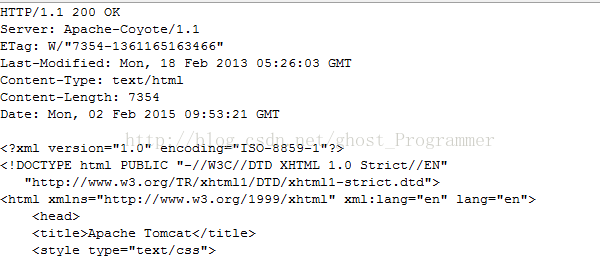
与HTTP请求类似,通常一个HTTP响应也包含三个部分:
- 协议/响应码/状态描述:协议也就是指HTTP协议的信息,响应码是指代表该次请求的处理结果的码(例如常见的200、404、500),其实就是该次请求处理的响应描述
- 响应标头:响应标头也包含与HTTP请求中的标头类似的有用信息。
- 响应实体:通常也就是指响应本身的HTML内容。
与HTTP请求一样,响应表头与响应实体之间,也会使用一个空行进行分割,方便解读。
同时我们也可以发现,其实真正被解析显示在浏览器网页上的内容,其实只是响应实体的部分。
响应行和响应标头当中,实际上是负责将相关的一些有用信息返回给我们,但这部分是不需要在浏览器中所展示的。
也就是说,我们的浏览器除了应当具备获取一个完整的HTTP响应的能力之外,还应该具备解析HTTP协议响应的能力。
事实上,Java也为我们提供了这样的对象,那就是URL及URLConnection对象。
如果我们在我们的山寨浏览器中,植入这样的对象,来进行与服务器之间的HTTP通信,那么:
- public class MyBrowser2 {
- public static void main(String[] args) {
- try {
- URL url = new URL("http://192.168.1.102:8080");
- HttpURLConnection conn = (HttpURLConnection) url.openConnection();
- InputStream in = conn.getInputStream();
- byte[] buf = new byte[1024];
- int length = 0;
- StringBuffer text = new StringBuffer();
- String line = null;
- while ((length = in.read(buf)) != -1) {
- line = new String(buf, 0, length);
- text.append(line);
- }
- System.out.println(text);
- } catch (IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
读取的响应信息,就如我们所愿的,只剩下了需要被解析显示在页面的响应实体的内容。
实际上这也就是Java为我们提供的对象,将对HTTP协议内容的解析功能进行了封装。
而究其根本来说,我们基本可以想象到,URLConnection = Socket + HTTP协议解析器。
也就是说,该对象的底层除了通过Socket连接到WEB服务器之外,还封装了对HTTP协议内容的解析功能。
于是到此,我们已经简单的了解了关于WEB服务器与浏览器的基本实现原理。














 7475
7475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









