







Kafa是一个分布式,分区和重复提交的日志服务,提供消息系统的功能。
相关术语:
相关术语:
主题(topic):Kafka维护订阅消息的类别生产者(producers):发消息给Kafka主题的进程消费者(consumers):订阅消息和处理发布的消息的进程中介者(broker):Kafka通过一个或多个服务组成的集群来运行,每一个服务称作中介者(broker)

客户端和服务端通信使用简单,高性能和语言无关的tcp协议,目前支持Java,pthon,C等多种语言的客户端
主题和日志(Topics and Logs)
Kafka集群维护每个主题的分区日志,每个分区是一个有序不变的消息队列,分区中的消息被指派唯一有序的ID编号成为偏移量(offset )。Kafka根据server.properties的配置log.retention.hours=168来决定发布消息的保留时间,而不管消息是否已经被消费,一旦消息保留时间超过了期限,那么消息将会被丢弃以释放磁盘空间。Kafka的性能与数据量的大小无关,所以存放大量数据是没有问题的。
(Kafka主题(topic)解剖图)
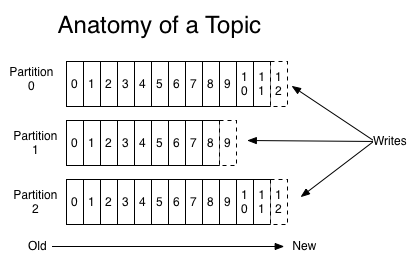
分配(Distribution)
日志的分区分布在Kafka集群的每台服务器上,每个服务器处理数据和共享分区的请求。每个分区可以通过配置配一定数据量的分区副本而进行容错。每个分区有一台服务器作为leader,一台或者多台服务器作为
followers,leader处理所有分区的读写请求。如果leader挂了,
followers中将自动产生新的leader。每台服务器都充一个分区的leader和其他分区的followers以达到负载均衡。
生产者(Producers )
生产者发布数据到选择的主题,并负责将消息分配到主题的分区上。为了负载均衡,生产者使用轮询的方式进行分配。或者根据分区函数进行分配。
消费者(consumers )
消息传递通常有两种模式:排队和发布订阅。Kafka采用单一的消费者抽象(消费者组
consumer group)统一这两者,消费者使用组名标注自己,每个主题的消息会传递给每个订阅消费者组的消费者实例。消费者实例可以存在于多进程或者多台机里。如果所有消费者实例有同样的组,这种方式和传统的队列很类似。如果所有的实例的组都不同,这种方式等同于发布订阅模式,所有的消息将广播到每个消费者。
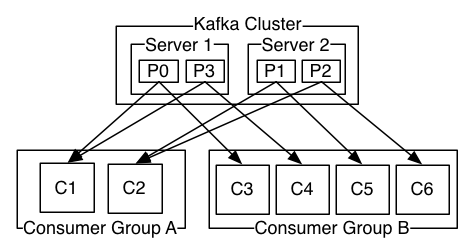
Kafka比传统的消息系统有更好的消息顺序保证。传统的消息队列能保证服务端发送是有序,但不能保证消息并行情况下有序的到达接收端。















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









