







 本文深入解析YouTube推荐系统架构,涵盖候选生成与排序两大核心阶段。介绍如何利用协同过滤及神经网络进行用户偏好建模,并通过加权逻辑回归预测观看时长以优化推荐效果。
本文深入解析YouTube推荐系统架构,涵盖候选生成与排序两大核心阶段。介绍如何利用协同过滤及神经网络进行用户偏好建模,并通过加权逻辑回归预测观看时长以优化推荐效果。
Introduction
主要包含两个阶段:
candidate generation(或称召回模块)
ranking
如下图所示
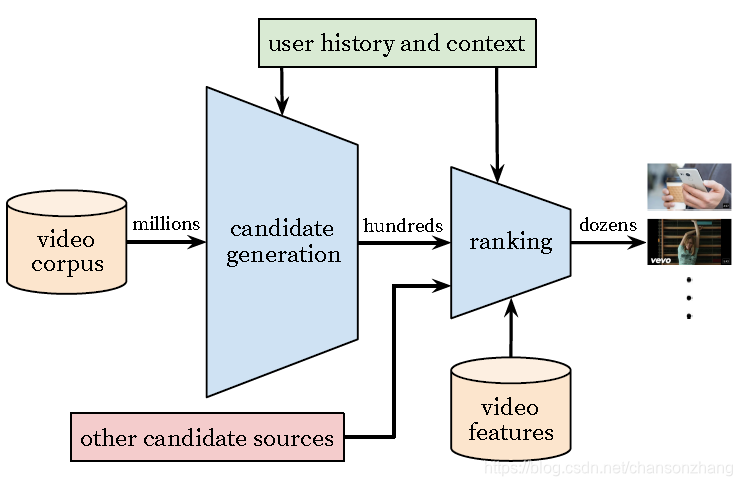
candidata generation 使用协同过滤,用户之间的相似度衡量是基于粗粒度的特征,例如:
看过的视频ID列表、search query tokens、人口统计学特征
ranking 使用细粒度的特特征对召回结果进
行打分
模型开发过程中:离线指标
精度、召回、ranking loss(?definition)
模型上线后效果评估
依赖A/B系统进行在线实验
关于实验系统的介绍,可以参见我的分享资料
在线实验主要关注指标: click through rate、watch time、 other user engagement measure.
Candidate Generation
召回模型实际是一个多分类模型,模型主要是学习用户和视频的embedding,然后使用softmax计算用户和视频的相似度。
模型基于视频完播这一隐形用户反馈来训练模型,却不采用点赞/点踩、应用内问卷等显式的用户反馈来训练模型,其原因主要是后者的稀疏性,对于大量长尾用户来说,前者更容易获取。
观看历史嵌入:变长的video id列表 -> 定长的稠密向量
why embedding?因为神经网络只能接收固定长度的向量
embedding strategies: averaging/sum/component-wise/max/etc.
averaging is best!
imporant:embeddings are learned jointly with other parameters with gradient descent back-propagation.
第一层: 各个特征被拼接起来组成一个"wide first layer"
其他层:多个全连接层,激活函数为ReLU
网络结构如下图所示

training:使用梯度下降最小化cross-entropy损失
servering:approximate nearest neighbor search(hash-based or tree-based or graph-based)
阿里2017年发表的论文中显示graph-based的nsg相比tree-base的annoy性能会有数十倍的提升,详见我的博客NSG介绍
我们团队的一位同事曾在2020年用阿里的nsg替代annoy做FAQ召回,结果证明阿里论文确实所言不虚。
深度神经网络是matrix factorization的泛化,优点是任意continuous and categorical 特征可以容易地加入模型中。
每个search query会被tokenized into unigrams and bigrams, 每个token都会被embedding,然后用平均值来表示搜索历史。
watch history、search history、人口统计特征、地理位置、设备信息都是进行嵌入后拼接在一起。简单的二值或者连续特征,比如性别、登录状态、年龄等不用嵌入,可以直接标准化到[0,1]区间内然后拼接到输入特征上。
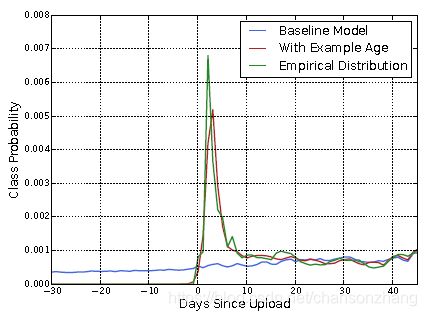
bias问题:因为模型是基于历史数据训练的,所以结果是对历史数据平均值的一个反映。但实际情况是,在不损害相关性的前提下,用户对新视频更感兴趣。因此他们在训练时加入样本年龄特征(example age, days since upload),然后在预测时,将这个特征设置为0或者负值,以反映最新的情况。
下图展示了这种方法在随机选择的一个视频上的效果
Label and Context Selection
推荐问题的本质其实是解决一个“surrogate problem”,然后将其迁移到具体的上下文中。比如准确的评分预测可以带来很好的电影推荐效果。其中评分预测就是电影推荐对应的surrogate problem.
为什么要去解决surrogate problem,而不直接去解决原始问题本身呢? 因为解决原始问题代价太高!
扩展阅读:surrogate modeling在工业设计中的应用
选择不同的surrogate problem对A/B test的结果影响很大,但是却很难在离线实验中评估。
论文中提出了以下注意点:
1、训练数据使用所有YouTube视频的播放记录,而不仅仅是推荐视频的播放情况,否则新内容很难曝光,而模型会overly biased towards exploitation.
2、如果用户通过推荐之外的途径发现了感兴趣的视频,系统会通过协同过滤将这样的新视频传播给别的相似用户。
3、对每个用户构建固定数量的训练样本,使每个用户都能在loss function中起到同等的作用,避免结果被一小撮highly active users主导。
4、给模型提供过多的信息可能会让模型“overfitting the surrogate problem”,比如模型可能会发现预测下一个观看的视频是出现在搜索结果页中的视频,这会让模型在训练集上表现良好,但一旦到了线上,用上一次搜索结果作为首页推荐显然是难以接受。为此,论文在处理search query时抛弃了序列信息并将其表示为无序的bag of tokens, 这样可以防止分类器学习到数据的原始标签。
5、论文发现选择预测next watch作为surrogate problem比预测randomly held-out watch效果要好,原因是后者泄露了未来的信息。这有点类似于transformer中限制decoder中的self-attention sub layer只能基于当前位置之前的输出来预测当前位置。
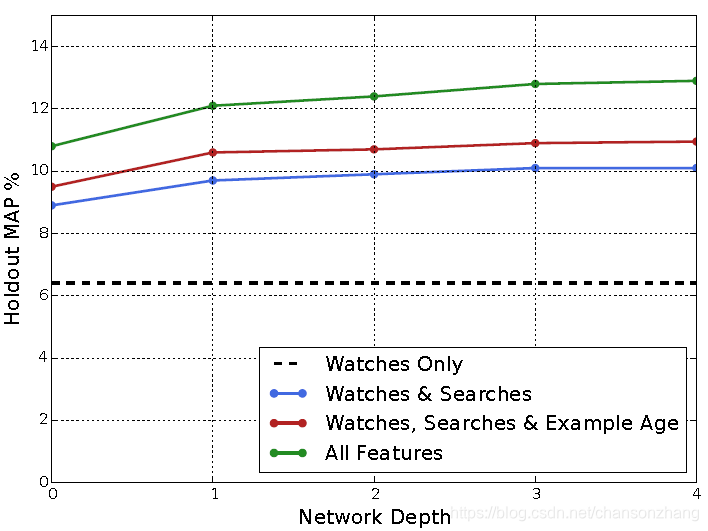
实验
Depth 0: A linear layer simply transforms the concatenation
layer to match the softmax dimension of 256
Depth 1: 256 ReLU
Depth 2: 512 ReLU ! 256 ReLU
Depth 3: 1024 ReLU ! 512 ReLU ! 256 ReLU
Depth 4: 2048 ReLU ! 1024 ReLU ! 512 ReLU !
256 ReLU
Ranking
由于召回阶段将候选数据规模从数百万缩小到几百,因此排序阶段可以使用更多的特征(在海量数据集上使用大量特征会造成无法接受的性能)。
另外排序阶段可以对不同召回源的数据进行混排,他们之间的分数往往不具有直接可比性。
排序阶段使用的模型与召回阶段的模型结构基本类似,主要区别在于排序阶段使用逻辑回归为每一个视频分配一个分数
注意在训练阶段使用逻辑回归,在serving阶段只用到
e
W
x
+
b
e^{Wx+b}
eWx+b作为分数。
最终的排序效果是是用A/B实验来衡量的, 其目标是提升视频的平均观察时长。不适用CTR是为了抑制标题党,对于这类视频用户被诱骗进去但很快就会退出。在YouTube的应用场景下,观看时长用于衡量用户的参与度更加合适。
Modeling Expected Watch Time
正样本: 视频被点击
负样本: 视频未被点击
正样本上标记了用户的观看时长
使用加权逻辑回归预测观看时长(weighted logistic regression)
实验

Referenced by


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









