







1、朴素字符串匹配
首先,先说一下最简单的字符串匹配算法。
如果主串是S=”abcdefgab”,我们要匹配T=”abcdex”.
那么最简单的匹配是:
abcdefgab
abcdex
|
abcdefgab
abcdex
|
abcdefgab
abcdex
|
abcdefgab
abcdex这里我们可以看到,这样一步一步的匹配,时间复杂度太高。
这个例子中,字符串T中第一个字符’a’和T中除第一个字符之外的字符都不相等。从第一步比较中:
abcdefgab
abcdex
我们可以看到红色的在第一次比较的时候已经比较过,且和T串对应位置相等,那么’a’和T串中的”bcde”不相等,也就是和S串中的”bcde”不相等。这样我们经过第一比较之后,下一次就可以直接跳到如下步:
abcdefgab
abcdex2、KMP算法
现在我们来看另一个例子:主串是S=”abcabcabc”,我们要匹配T=”abcabx”.
根据上面的方法,我们得到下面的步骤:
i=123456789
abcabcabc
|||||
abcabx
j= 6
i=123456789
abcabcabc
||
abcabx
j= 3 这里我们可以发现,因为T字符串的“abcab”这个字符串中前缀”ab”和后缀“ab”相等,又第一次比较的时候,T字符串的“abcab”这个字符串中后缀”ab”和S字符串中“abcab”的后缀“ab”已经比较过,且相等,那么T字符串中前两个字符”ab”也不再需要和S串中后两个”ab”进行比较,直接从字符’c’开始比较即可。
第一次比较,主串比较到了第6个字符(i=6)’c’时,和T串对应位置(j=6)不相等。第二次我们继续从i=6处开始比较,此时对应的T串是第三个字符,即j=3。这里我们保证了i值是不回溯的,即i值不可以变小在比较过程中。
这就是KMP算法,我们这里一直提到的字符串T的前缀后缀,都是针对字符串T和主串S没有关系,所以这里的j值变化与主串也没有什么关系,而是取决于T串的结构中是否有重复的字符串。如上”abcab”,有前缀和后缀”ab”,因此j=6–>j=3。所以KMP算法就是先对T字符串做一次预处理,即求出下面的next数组,然后根据next数组来进行匹配,加快的匹配的速度。
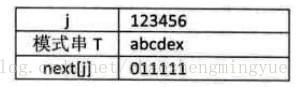
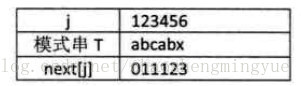
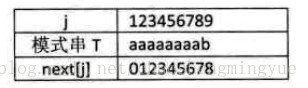
我们把T串的各个位置的j值变化定义为一个数组next,next的长度就是串的长度。下面是函数的定义。(这里数组第一个元素是,next[1])

next[j]就是表示为,当被匹配字符串前j-1个字符和主串匹配,第j个字符和主串不同时,下一次比较,直接从被匹配子串的第next[j]和主串的第i个字符开始比较。当没有前后缀时,每次下移一位。
next数组的推导
例子:

前面写的比较乱,下面小结一下前面的内容。
我们首先用一个图来描述kmp算法的思想。在字符串O中寻找f,当匹配到位置i时两个字符串不相等,这时我们需要将字符串f向前移动。常规方法是每次向前移动一位,但是它没有考虑前i-1位已经比较过这个事实,所以效率不高。事实上,如果我们提前计算某些信息,就有可能一次前移多位。假设我们根据已经获得的信息知道可以前移k位,我们分析移位前后的f有什么特点。我们可以得到如下的结论:
- A段字符串是f的一个前缀。
- B段字符串是f的一个后缀。
- A段字符串和B段字符串相等。
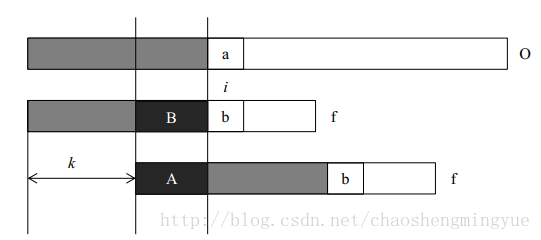
所以前移k位之后,可以继续比较位置i的前提是f的前i-1个位置满足:长度为i-k-1的前缀A和后缀B相同。只有这样,我们才可以前移k位后从新的位置继续比较。
所以kmp算法的核心即是计算字符串f每一个位置之前的字符串的前缀和后缀公共部分的最大长度(不包括字符串本身,否则最大长度始终是字符串本身)。获得f每一个位置的最大公共长度之后,就可以利用该最大公共长度快速和字符串O比较。当每次比较到两个字符串的字符不同时,我们就可以根据最大公共长度将字符串f向前移动(已匹配长度-最大公共长度)位,接着继续比较下一个位置。事实上,字符串f的前移只是概念上的前移,只要我们在比较的时候从最大公共长度之后比较f和O即可达到字符串f前移的目的。
借用一下别人的图:
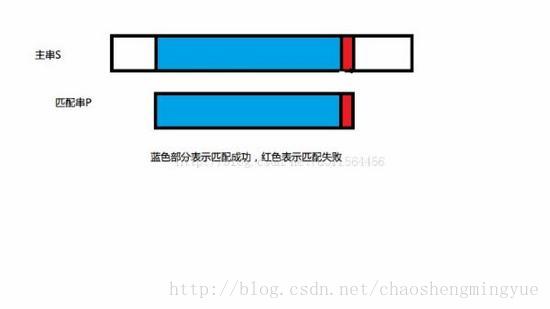
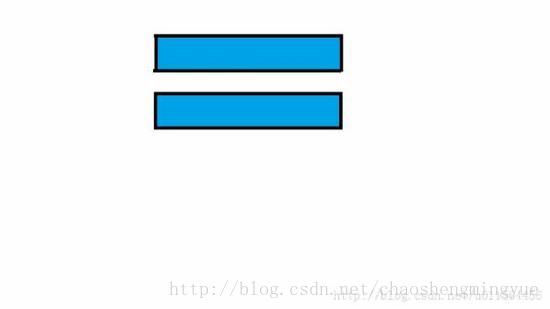
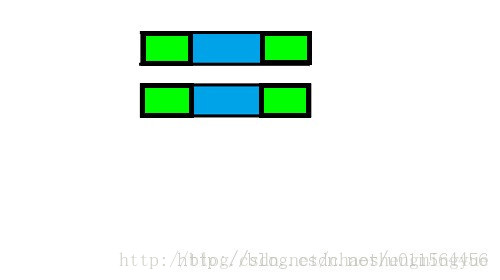
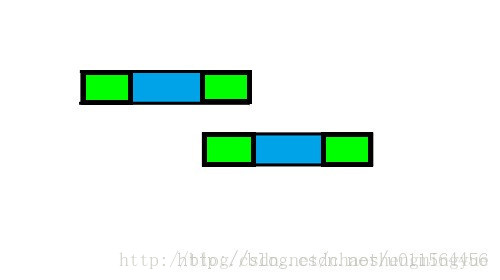
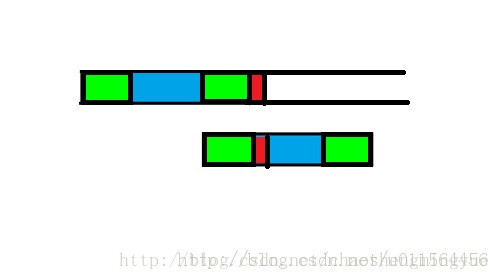
这里会有点疑问是:为什么找到前后缀,下次直接就将前缀移动到后缀的位置,然后从前缀下一个字符开始匹配,蓝色的部分如果也出现和前缀一样的字符怎么办?这里我们可以举一个例子:
假设前缀是A,后缀是A,那么
主串:A[蓝色部分]A[主串剩下部分]
匹配串:A[蓝色部分]A[匹配串剩下部分]。
为解决上面的疑问,假设蓝色部分也有A,假设蓝色部分是:XAY
AXAYA[主串剩下部分]
AXAYA[匹配串剩下部分]可以看到,有两种情况X=Y,X!=Y。
X!=Y: 所以我们不用在和蓝色部分比较,直接和后缀部分比较,即:
AXAYA[主串剩下部分]
AXAYA[匹配串剩下部分]X=Y:这时AXAYA=AXAXA,此时前缀是AXA,后缀是AXA,因此
AXAXA[主串剩下部分]
AXAXA[匹配串剩下部分]还是前缀和后缀部分比较。此时蓝色部分不存在了。
因此蓝色部分不用比较。
代码实现:
理解了kmp算法的基本原理,下一步就是要获得字符串f每一个位置的最大公共长度。这个最大公共长度在算法导论里面被记为next数组。在这里要注意一点,next数组表示的是长度,下标从1开始;但是在遍历原字符串时,下标还是从0开始。假设我们现在已经求得next[1]、next[2]、……next[i],分别表示长度为1到i的字符串的前缀和后缀最大公共长度,现在要求next[i+1]。由下图我们可以看到,如果位置i和位置next[i]处的两个字符相同(下标从零开始),则next[i+1]等于next[i]加1。如果两个位置的字符不相同,我们可以将长度为next[i]的字符串继续分割,获得其最大公共长度next[next[i]],然后再和位置i的字符比较。这是因为长度为next[i]前缀和后缀都可以分割成上部的构造,如果位置next[next[i]]和位置i的字符相同,则next[i+1]就等于next[next[i]]加1。如果不相等,就可以继续分割长度为next[next[i]]的字符串,直到字符串长度为0为止。
这里我们可以举个例子:T=“A1xA2yz”,A1,A2是字符串,A1=A2,此时比较到y!=x,因为Ai也是一个字符串因此也可以分割为前缀和后缀,设A1=A2=BHB,那么
123456789
A1xA2yz=BHBxBHByz
检测到S[i]!=S[j]时,j=4,i=8.但是因为x,y前面的A是相等的,故A1的前缀和A2的后缀也相等,故可以直接用之前的next数组的值另j=next[j],即为A1中H的第一个字符的位置。

#include <iostream>
#include <string>
#include <vector>
using namespace std;
//计算next数组
vector<int> get_next(string S)
{
int i = 0, j = -1;
//这里我假设next[0]=-1
vector<int> vec(S.size(),-1);
while (i < S.size()-1)
{
//S[i]表示后缀中单个字符,S[j]表示前缀中单个字符
//j==-1时,表示要从头比较,即vec[i]=0
if (j == -1|| S[i] == S[j])
{
++i;
++j;
vec[i] = j;
}
else
//若字符不相同,则j的值回溯。
j = vec[j];
}
return vec;
}
int kmp(string T, string S, int pos)
{
int i = pos;
int j = 0;
vector<int> vec;
vec = get_next(S);
while (i < T.size() && j < S.size())
{
if (j == -1 || T[i] == S[j])
{
i++;
j++;
}
else
j = vec[j];
}
if (j >= S.size())
{
return i - S.size();
}
else
return 0;
}
int main()
{
string T = "abcabcabx", S = "abcabx";
int p = kmp(T, S, 0);
cout << p << endl;
}













 2250
2250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









