







 本文探讨了多元约束背包问题(MCKP)的多种求解算法,包括线性支配过滤、贪心算法、Dyer-Zemel算法、拉格朗日松弛和动态规划。通过实例演示了各算法的实现过程与结果对比。
本文探讨了多元约束背包问题(MCKP)的多种求解算法,包括线性支配过滤、贪心算法、Dyer-Zemel算法、拉格朗日松弛和动态规划。通过实例演示了各算法的实现过程与结果对比。
原文链接:https://link.springer.com/chapter/10.1007/978-3-540-24777-7_11
不同于传统的背包问题,MCKP需要保证每个分组里面至少选一个物品,建模如下
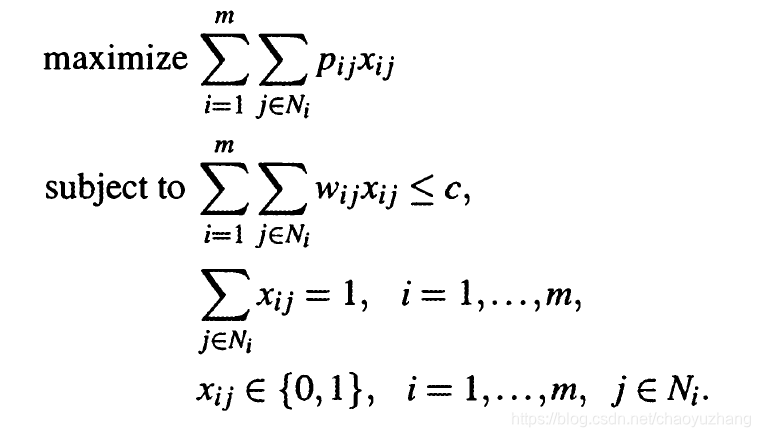
其提出线性支配(LP-dominated)的定义如下

这是个筛选的过程,把处于支配(同一组内存在比你重量小但价值高的物品)的去掉,线性支配的定义会更强,比如3和7,其被线性支配,故被去掉,我个人理解这样在部分情况有可能把最优解去掉了,所以一般采用前者。
纯贪心算法如下

class Good():
def __init__(self, row, col, p, w):
self.row = row
self.col = col
self.p = p
self.w = w
def __repr__(self):
return str((self.w, self.p))
def goods_filter_LP_dominated(goods, exacting=True):
[goods[i].sort(key=lambda n:n.w, reverse=False) for i in range(len(goods))]
goods1 = [[goods[i][0]] for i in range(len(goods))]
for i in range(len(goods)):
p, w = goods1[i][0].p, goods1[i][0].w
for j in range(1, len(goods[i])):
if goods[i][j].w == w and goods[i][j].p > p:
goods1[i][-1] = goods[i][j]
p = goods[i][j].p
elif goods[i][j].w > w and goods[i][j].p > p:
goods1[i].append(goods[i][j])
p, w = goods[i][j].p, goods[i][j].w
# 严格LP_dominated
if exacting:
goods2 = [[goods1[i][0]] for i in range(len(goods1))]
for i in range(len(goods1)):
j = 0
while j < len(goods1[i]) - 1:
slopes = [[k, (goods1[i][k].p - goods1[i][j].p) / (goods1[i][k].w - goods1[i][j].w)] for k in range(j + 1, len(goods1[i]))]
slopes.sort(key=lambda x: x[1], reverse=True)
j = slopes[0][0]
goods2[i].append(goods1[i][j])
goods1 = goods2
return goods1
#每次更新都选择局部提升最大的
def Greedy(goods, c):
goods = goods_filter_LP_dominated(goods, exacting=True)
# 做成链表的形式,利于贪心算法
class Node():
def __init__(self, good):
self.good = good
self.improve = float("-inf")
self.next = None
def __repr__(self):
return str(self.good)
L_Node = []
for i in range(len(goods)):
n = Node(goods[i][0])
temp = n
j = 0
while j+1 < len(goods[i]):
j += 1
temp.next = Node(goods[i][j])
temp.improve = (goods[i][j].p - goods[i][j-1].p) / (goods[i][j].w - goods[i][j-1].w)
temp = temp.next
L_Node.append(n)
# 初始化可行解Y,使用空间d,价值z
d = sum([L_Node[i].good.w for i in range(len(L_Node))])
is_end = False
while not is_end:
is_end = True
L_Node.sort(key=lambda x: x.improve, reverse=True)
for i in range(len(L_Node)):
if L_Node[i].next and L_Node[i].next.good.w - L_Node[i].good.w <= c-d:
d += L_Node[i].next.good.w - L_Node[i].good.w
L_Node[i] = L_Node[i].next
is_end = False
break
obj = sum([n.good.p for n in L_Node])
cost = sum([n.good.w for n in L_Node])
res_choose = [L_Node[i].good for i in range(len(L_Node))]
res_choose.sort(key=lambda x:x.row)
return res_choose, obj, cost
def run_one():
#不一定最优、反例
# P = [
# [25, 55, 65, 76, 40, 20, 80, 50, 89, 30, 82],
# [47, 20, 50, 95, 70, 40, 75, 30],
# [35, 10, 59, 20, 71, 15, 45, 40, 80]
# ]
#
# W = [
# [7, 12, 24, 26, 35, 45, 51, 58, 65, 85, 90],
# [12, 20, 24, 36, 50, 60, 80, 84],
# [8, 10, 24, 30, 40, 55, 60, 80, 85]
# ]
P = [
[76, 49, 79, 41, 25, 78, 31, 55, 63, 19, 89],
[95, 17, 36, 47, 29, 51, 84, 73],
[35, 39, 20, 51, 24, 71, 59, 80, 14]
]
W = [
[26, 62, 84, 35, 7, 54, 82, 12, 23, 50, 65],
[36, 25, 62, 12, 91, 28, 73, 54],
[8, 85, 61, 62, 30, 40, 24, 85, 11]
]
c = 100
goods = [[Good(i, j, P[i][j], W[i][j]) for j in range(len(W[i]))] for i in range(len(W)) if len(W[i]) > 0]
res_choose_greedy, obj_greedy, cost_greedy = Greedy(goods, c)
print("\nres_choose_greedy:", res_choose_greedy)
print("obj_greedy:", obj_greedy)
print("cost_greedy:", cost_greedy)
if __name__ == '__main__':
run_one()Dyer-Zemel算法如下

import numpy as np
from MCKP.method.MCKP_Greedy import *
#用中位数去筛选边,有点lagrangian的意思
def Dyer_Zemel(goods, c):
goods = goods_filter_LP_dominated(goods, exacting=False)
while True:
slopes = [(goods[i][j+1].p - goods[i][j].p) / (goods[i][j+1].w - goods[i][j].w) for i in range(len(goods)) for j in range(len(goods[i])-1)]
alpha = np.median(slopes)
values_alpha = [[goods[i][j].p - alpha*goods[i][j].w for j in range(len(goods[i]))] for i in range(len(goods))]
L_a = [values_alpha[i].index(max(values_alpha[i])) for i in range(len(values_alpha))]
L_b = [L_a[i]+1 if L_a[i] < len(values_alpha[i])-1 and values_alpha[i][L_a[i]] == values_alpha[i][L_a[i]+1] else L_a[i] for i in range(len(values_alpha))]
w_a_sum = sum([goods[i][L_a[i]].w for i in range(len(goods))])
w_b_sum = sum([goods[i][L_b[i]].w for i in range(len(goods))])
if w_a_sum > c:
goods = [[goods[i][j] for j in range(len(goods[i])) if j == 0 or (j > 1 and (goods[i][j].p - goods[i][j-1].p) / (goods[i][j].w - goods[i][j-1].w)) >= alpha] for i in range(len(goods))]
elif w_b_sum < c:
goods = [[goods[i][j] for j in range(len(goods[i])) if j == len(goods[i])-1 or (j < len(goods[i])-1 and (goods[i][j+1].p - goods[i][j].p) / (goods[i][j+1].w - goods[i][j].w)) <= alpha] for i in range(len(goods))]
else:
break
goods1 = [[goods[i][L_a[i]], goods[i][L_b[i]]] if L_a[i] < L_b[i] else [goods[i][L_a[i]]] for i in range(len(goods))]
return Greedy(goods1, c)
def run_one():
P = [
[76, 49, 79, 41, 25, 78, 31, 55, 63, 19, 89],
[95, 17, 36, 47, 29, 51, 84, 73],
[35, 39, 20, 51, 24, 71, 59, 80, 14]
]
W = [
[26, 62, 84, 35, 7, 54, 82, 12, 23, 50, 65],
[36, 25, 62, 12, 91, 28, 73, 54],
[8, 85, 61, 62, 30, 40, 24, 85, 11]
]
c = 100
goods = [[Good(i, j, P[i][j], W[i][j]) for j in range(len(W[i]))] for i in range(len(W)) if len(W[i]) > 0]
res_choose_Dyer_Zemel, obj_Dyer_Zemel, cost_Dyer_Zemel = Dyer_Zemel(goods, c)
print("\nres_choose_Dyer_Zemel:", res_choose_Dyer_Zemel)
print("obj_Dyer_Zemel:", obj_Dyer_Zemel)
print("cost_Dyer_Zemel:", cost_Dyer_Zemel)
if __name__ == '__main__':
run_one()
其对偶问题如下

class Good():
def __init__(self, row, col, p, w):
self.row = row
self.col = col
self.p = p
self.w = w
def __repr__(self):
return str((self.w, self.p))
def goods_filter_LP_dominated(goods, exacting=True):
[goods[i].sort(key=lambda n:n.w, reverse=False) for i in range(len(goods))]
goods1 = [[goods[i][0]] for i in range(len(goods))]
for i in range(len(goods)):
p, w = goods1[i][0].p, goods1[i][0].w
for j in range(1, len(goods[i])):
if goods[i][j].w == w and goods[i][j].p > p:
goods1[i][-1] = goods[i][j]
p = goods[i][j].p
elif goods[i][j].w > w and goods[i][j].p > p:
goods1[i].append(goods[i][j])
p, w = goods[i][j].p, goods[i][j].w
# 严格LP_dominated
if exacting:
goods2 = [[goods1[i][0]] for i in range(len(goods1))]
for i in range(len(goods1)):
j = 0
while j < len(goods1[i]) - 1:
slopes = [[k, (goods1[i][k].p - goods1[i][j].p) / (goods1[i][k].w - goods1[i][j].w)] for k in range(j + 1, len(goods1[i]))]
slopes.sort(key=lambda x: x[1], reverse=True)
j = slopes[0][0]
goods2[i].append(goods1[i][j])
goods1 = goods2
return goods1
def L(goods, u, c):
return u*c + sum([max([g.p-u*g.w for g in goods[i]]) for i in range(len(goods))])
def U2_generate(goods, r, c, step_min):
left = 0
right = 1
# 先采用放缩法确定寻优区间
while L(goods, right * (2 - r), c) < L(goods, right, c):
right = right * (2 - r)
right = right * (2 - r)
# 采用三分法确定步长
mid1 = left * 2 / 3 + right / 3
mid2 = left / 3 + right * 2 / 3
while abs(right - left) > step_min:
if L(goods, mid1, c) < L(goods, mid2, c):
right = mid2
else:
left = mid1
mid1 = left * 2 / 3 + right / 3
mid2 = left / 3 + right * 2 / 3
return L(goods, left, c)
#每次更新都选择局部提升最大的
def Lagrangian(goods, c, r=0.8, step_min=0.00001):
goods = goods_filter_LP_dominated(goods, exacting=False)
return U2_generate(goods, r, c, step_min)
def run_one():
#不一定最优、反例
# P = [
# [25, 55, 65, 76, 40, 20, 80, 50, 89, 30, 82],
# [47, 20, 50, 95, 70, 40, 75, 30],
# [35, 10, 59, 20, 71, 15, 45, 40, 80]
# ]
#
# W = [
# [7, 12, 24, 26, 35, 45, 51, 58, 65, 85, 90],
# [12, 20, 24, 36, 50, 60, 80, 84],
# [8, 10, 24, 30, 40, 55, 60, 80, 85]
# ]
P = [
[76, 49, 79, 41, 25, 78, 31, 55, 63, 19, 89],
[95, 17, 36, 47, 29, 51, 84, 73],
[35, 39, 20, 51, 24, 71, 59, 80, 14]
]
W = [
[26, 62, 84, 35, 7, 54, 82, 12, 23, 50, 65],
[36, 25, 62, 12, 91, 28, 73, 54],
[8, 85, 61, 62, 30, 40, 24, 85, 11]
]
c = 100
goods = [[Good(i, j, P[i][j], W[i][j]) for j in range(len(W[i]))] for i in range(len(W)) if len(W[i]) > 0]
U2 = Lagrangian(goods, c)
print("\nU2:", U2)
if __name__ == '__main__':
run_one()
动态规划
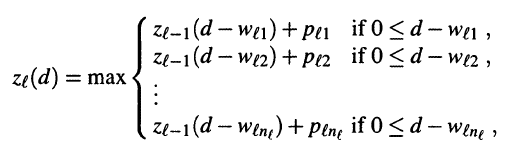
class Good():
def __init__(self, row, col, p, w):
self.row = row
self.col = col
self.p = p
self.w = w
def __repr__(self):
return str((self.w, self.p))
def goods_filter_LP_dominated(goods, exacting=True):
[goods[i].sort(key=lambda n:n.w, reverse=False) for i in range(len(goods))]
goods1 = [[goods[i][0]] for i in range(len(goods))]
for i in range(len(goods)):
p, w = goods1[i][0].p, goods1[i][0].w
for j in range(1, len(goods[i])):
if goods[i][j].w == w and goods[i][j].p > p:
goods1[i][-1] = goods[i][j]
p = goods[i][j].p
elif goods[i][j].w > w and goods[i][j].p > p:
goods1[i].append(goods[i][j])
p, w = goods[i][j].p, goods[i][j].w
# 严格LP_dominated
if exacting:
goods2 = [[goods1[i][0]] for i in range(len(goods1))]
for i in range(len(goods1)):
j = 0
while j < len(goods1[i]) - 1:
slopes = [[k, (goods1[i][k].p - goods1[i][j].p) / (goods1[i][k].w - goods1[i][j].w)] for k in range(j + 1, len(goods1[i]))]
slopes.sort(key=lambda x: x[1], reverse=True)
j = slopes[0][0]
goods2[i].append(goods1[i][j])
goods1 = goods2
return goods1
#每次更新都选择局部提升最大的
def Dynamic(goods, c):
goods = goods_filter_LP_dominated(goods, exacting=False)
class Combination():
def __init__(self, P, W, L):
self.P = P
self.W = W
self.L = L
def __repr__(self):
return str((self.W, self.P))
C = {goods[0][j].w: Combination(goods[0][j].p, goods[0][j].w, [goods[0][j]]) for j in range(len(goods[0]))}
for i in range(1, len(goods)):
C_next = {}
for j in range(len(goods[i])):
for k,v in C.items():
if goods[i][j].w + k > c:
continue
#不在或价值更高则更新
if (goods[i][j].w + k not in C_next) or (goods[i][j].w + k in C_next and goods[i][j].p + v.P > C_next[goods[i][j].w + k].P):
C_next[goods[i][j].w + k] = Combination(goods[i][j].p + v.P, goods[i][j].w + k, v.L+[goods[i][j]])
C = C_next
res = list(C.values())
res.sort(key=lambda x:x.P, reverse=True)
res_choose = res[0].L
obj = res[0].P
cost = res[0].W
return res_choose, obj, cost
def run_one():
#不一定最优、反例
# P = [
# [25, 55, 65, 76, 40, 20, 80, 50, 89, 30, 82],
# [47, 20, 50, 95, 70, 40, 75, 30],
# [35, 10, 59, 20, 71, 15, 45, 40, 80]
# ]
#
# W = [
# [7, 12, 24, 26, 35, 45, 51, 58, 65, 85, 90],
# [12, 20, 24, 36, 50, 60, 80, 84],
# [8, 10, 24, 30, 40, 55, 60, 80, 85]
# ]
P = [
[76, 49, 79, 41, 25, 78, 31, 55, 63, 19, 89],
[95, 17, 36, 47, 29, 51, 84, 73],
[35, 39, 20, 51, 24, 71, 59, 80, 14]
]
W = [
[26, 62, 84, 35, 7, 54, 82, 12, 23, 50, 65],
[36, 25, 62, 12, 91, 28, 73, 54],
[8, 85, 61, 62, 30, 40, 24, 85, 11]
]
c = 100
goods = [[Good(i, j, P[i][j], W[i][j]) for j in range(len(W[i]))] for i in range(len(W)) if len(W[i]) > 0]
res_choose_Dynamic, obj_Dynamic, cost_Dynamic = Dynamic(goods, c)
print("\nres_choose_Dynamic:", res_choose_Dynamic)
print("obj_Dynamic:", obj_Dynamic)
print("cost_Dynamic:", cost_Dynamic)
if __name__ == '__main__':
run_one()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









