






大家好,本文将围绕python数据爬取有哪些库和框架展开说明,python爬取数据保存到数据库是一个很多人都想弄明白的事情,想搞清楚python爬取数据存入数据库需要先了解以下几个事情。
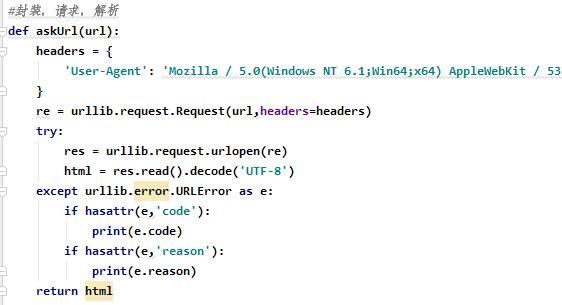

在大家学习Python爬虫的过程中,必然少不了将爬取的数据进行存储,现在最常存储的方式有存储TXT文本、CSV文件、Excel文件、数据仓库这三种,今天我们就来一一介绍一下如何存储。
1、TXT文本存储
f=open(path+’filename.txt’,’a+’)f.write(info+’\n’)f.close()《斗破苍穹》文本存储代码如下:
import requestsimport reimport timeheaders={"User-Agent": "请求头"}f=open('doupo.txt','a+')def get_info(url): res=requests.get(url,headers=headers) if res.status_code==200: contents = re.findall('(.*?)
'
,res.content.decode('utf-8'),re.S) for content in contents: f.write(content+'\n') print(content) else: passif __name__=='__main__': urls=['http://www.doupoxs.com/doupocangqiong/{}.html'.format(i) for i in range(2,4)] for url in urls: get_info(url) time.sleep(1) f.close()
运行结果如下:

2、CSV文件存储
import csvfp=open(path+’/filename.csv’,’wt’,newline=’’,encoding=’utf-8’)writer=csv.writer(fp)writer.writerow((‘name’,’url’))fp.close()《豆瓣网图书TOP1》CSV存储代码如下:
from lxml import etreeimport requestsimport csvfp=open('doubanbooktop.csv','wt',newline='',encoding='utf-8')writer=csv.writer(fp)writer.writerow(('name','book_infos'))urls=['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,25,25)]headers={"User-Agent": "请求头"}for url in urls: html = requests.get(url,headers=headers) selector = etree.HTML(html.text) infos=selector.xpath('//tr[@]') print(infos) for info in infos: name=info.xpath('td/div[1]/a/text()')[0] book_infos=info.xpath('td/p/text()')[0] rate=info.xpath('td/div/span[2]/text()')[0] print(name,book_infos) writer.writerow((name)) fp.close()运行结果如下
(1)乱码格式的csv

(2)转换文本存储后

3、Excel文件存储
import xlwtbook=xlwt.Workbook(encoding=’utf-8’)sheet=book.add_sheet(‘sheet1’)sheet.write(0,0,’python’)sheet.write(1,1,’love’)book.save(‘text.xls’)《起点中文网》Excel存储代码如下:
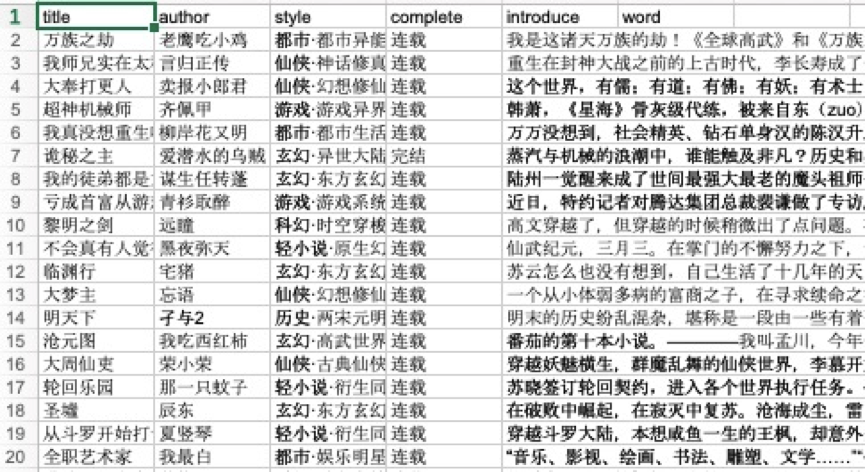
import xlwtfrom lxml import etreeimport requestsimport time# 初始化列表,存入爬虫数据headers={"User-Agent": "请求头"}all_info_list = [] # 初始化列表,存入爬虫数据def get_info(url): html = requests.get(url, headers=headers) selector = etree.HTML(html.text) infos=selector.xpath('//ul[@]/li') #定位大标签,以此循环 for info in infos: title=info.xpath('div[2]/h4/a/text()')[0] author=info.xpath('div[2]/p[1]/a[1]/text()')[0] style_1 = info. xpath('div[2]/p[1]/a[2]/text()')[0] style_2 = info. xpath('div[2]/p[1]/a[3]/text()')[0] style = style_1+'·'+ style_2 complete = info.xpath('div[2]/p[1]/span/text()')[0] introduce = info.xpath('div[2]/p[2]/text()')[0].strip() word = info.xpath('div[2]/p[3]/span/text()')[0].strip('万字') print(title, author,style,complete,introduce,word) info_list = [title, author, style, complete, introduce, word] all_info_list.append(info_list) time.sleep( 1)if __name__ == '__main__': # 程序 主 入口 urls = ['http://a.qidian.com/?page={}'.format(str(i)) for i in range(1, 2)] for url in urls: get_info(url) header = ['title','author','style','complete','introduce','word'] book =xlwt.Workbook(encoding='utf-8') #创建工作簿 sheet = book.add_sheet('sheet1') for h in range(len(header)): sheet.write(0,h,header[h]) i = 1 for list in all_info_list: j = 0 for data in list: sheet.write(i,j,data) j +=1 i +=1 book.save('qidianxiaoshuo.xls') #保存文件运行结果如下:
4、数据库存储
import pymysqlconn=pymysql.connect(host=’localhost’,user=’root’,passwd=’123456’,db=’pymysql_name’,port=3306,charset=’utf8’)cursor=conn.cursor()cursor.execute(‘insert into table(name,info1)values(%s,%s)’,(name,info1))conn.commit()《豆瓣电影TOP》数据库存储代码如下:
import requestsfrom lxml import etreeimport reimport pymysqlimport timedb = pymysql.connect(host='localhost', user='root', passwd=密码, db='库名称, port=3306, charset='utf8')cursor = db.cursor()headers={"User-Agent": "请求头"}def get_movie_url(url): html=requests.get(url,headers=headers) selector=etree.HTML(html.text) movie_infos=selector.xpath('//div[@]/a/@href') for movie_url in movie_infos: get_movie_info(movie_url)def get_movie_info(url): html = requests.get(url, headers=headers) selector = etree.HTML(html.text) try: name=selector.xpath('//*[@id="content"]/h1/span[1]/text()')[0] director=selector.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0] cursor.execute("insert into doubanmovie (name,director) values(%s,%s)",(str(name),str(director))) except IndexError: passif __name__=='__main__': urls=['https://movie.douban.com/top250?start={}&filter='.format(i) for i in range(0,25,25)] for url in urls: get_movie_url(url) time.sleep(2) db.commit()运行结果如下:

以上就是python爬取后数据存储的各种方法,大家可以根据学习过程中的需要随时切换使用来不断完善技能用python画雪人。
--每天一小步、未来一大步!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









