







一、Lamdba表达式:
1、简介:
本质上,Lamdba表达式是一个匿名内部类,也可以理解为,一段可以传递的代码。使用它可以把代码修饰得更加简洁、灵活。
在Lamdba表达式中,引入了一种新的语法元素。表达式会通过操作符号 -> 连接左右两边,左边放置Lamdba表达式的需接收类型、参数,右边则是函数体,可以放置需要执行的操作内容。
我们先看一个以往普通的内部类函数代码,应该是这样写的:
package lamdba;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class TestLamdba {
private static Logger logger = LoggerFactory.getLogger(TestLamdba.class);
public static void main(String[] args) {
Runnable runnable1 = new Runnable() {
@Override
public void run() {
logger.info("普通内部类,重写必须继承的方法,执行代码。");
}
};
//执行方法
runnable1.run();
}
}
当使用lamdba表达式后,上面的代码,可以优化为如下:
2、语法格式结合用法:
1)格式一:无参数、无返回值 () -> 需执行代码;
//lamdba表达式格式一:
Runnable runnable2 = ()-> logger.info("lamdba表达式需要执行的代码");
runnable2.run();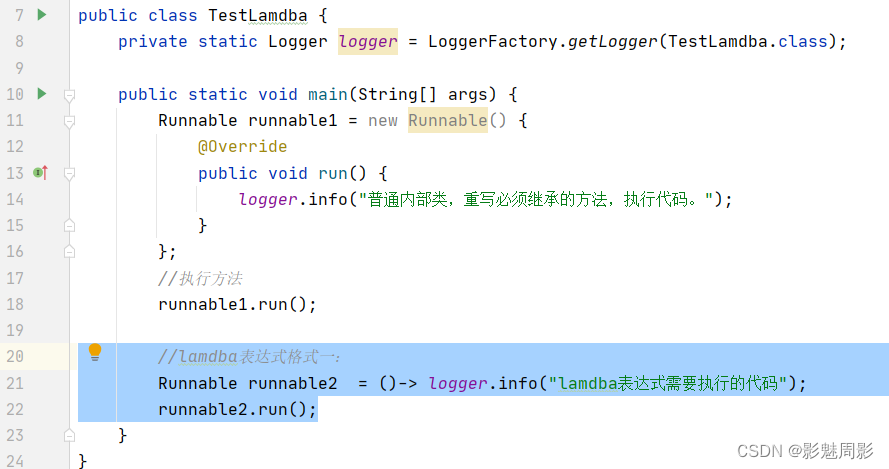

2)格式二:无参数、无返回值 () -> { 执行代码; };
//lamdba表达式格式二:
Runnable runnable2 = ()-> {logger.info("lamdba表达式需要执行的代码2");};
runnable2.run();

3)其他格式:
引用一下某个博主的整理。 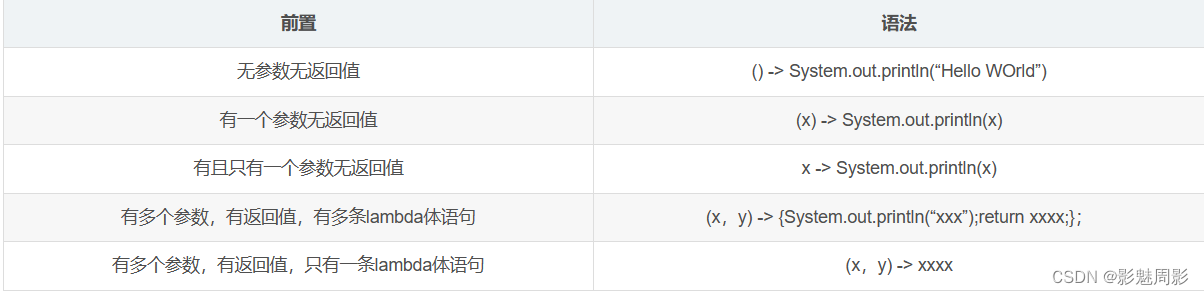
但是实际上,个人使用了一下Lambda表达式后,发现其实可以这样总结下用途:
首先,大多情况下,Lambda表达式通过一个内部类型返回,相当于获得一个类对象,同时改写该类对象所继承或实现的某个必要方法,以->符号作为标志性语法指向重写的方法体;
其次,这个匿名内部类,一般不由自己自行编写运用,大都使用的jar包自带的(比如上面的runnable,还有其他博主举例常用的Consumer之类的,基本上是直接调用提供的接口,自己写的也不是没有,但是可能一般很少这么做,或许生产上,能使用的场景较少;
再次,在格式上,大抵可以理解为是否 --是否具有返回值,表达式右边是否携带{} ,而不必要去强行记下上面的每一个格式,因为最根本格式就是 -- A类型 引用名 = Lambda表达式左边 -> Lambda表达式右边。
最后,使用增强for循环遍历时,其实也会用到,例如
list.forEach( str -> {});
那么这个算不算Lambda表达式呢?其实这个应该也是,但是会跟例子上的有不同的点,由于JDK的特性其实每个版本都有,也比较多,如果一一去揪着来理解清楚并使用,至少在目前国内这种用人赚钱多于技术研究的情况下,不适用,当你久了不用的知识,很快就忘记的,所以了解一下有这么个点就行了,大部分伙伴都基本是用来过面试的,实际用的,实在是很少。
二、函数式接口
1、简介:
函数式接口的出现是为了方便Lambda表达式的使用。所有的函数式接口都是可以适用于Lambda表达式的。
同时,可以通过注解@FunctionalInterface来判断是否为规范的函数式接口,如果自定义接口加该注解编译通过则为规范。
2、格式:
有且只有一个抽象方法的接口。例如:
package lamdba.service;
import copy.entity.Student;
@FunctionalInterface
public interface StudentService {
Student getName();
}
3、常用函数式接口:
上面例子称为我们自定义的函数式接口。
那么理所当然,新特性出来,在jdk中自然是会被使用上的才会有,所以,记录下几个常用的函数式接口,可以直接在自定义的代码中直接使用,同时直接结合Lambda表达式,而无需自行创建一个函数式接口,然后再通过Lambda表达式使用(实际上我们应该也很少这么用,因为当你建立一个接口时,基本上就需要考虑扩展性,而不能只考虑新特性,所以Lambda表达式也很少用)。
java中内置有四个大类的函数式接口,其他的应该都是基于此四类的延申(其他博主说的)。
1)Supplier接口 - 生产型接口
· Supplier接口包含一个无参的方法;
· T get() :获得结果
该方法不需要参数,它会按某种实现逻辑(由Lambda表达式实现)返回一个数据。
Supplier接口也称为生产型接口,使用者所指定的泛型,即为get()方法所生产出的类型数据,而后供我们使用。
package lamdba;
import copy.entity.Student;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.function.Supplier;
public class TestLamdba {
private static Logger logger = LoggerFactory.getLogger(TestLamdba.class);
public static void main(String[] args) {
testSupplier();
}
public static void testSupplier(){
//Student是一个自定义实体类
Supplier<Student> student = () -> {
logger.info("生产型接口");
return new Student();
};
logger.info(String.valueOf(student.get()));
}
}

如果是需要返回自定义类,个人感觉应该会比较少,毕竟如果你要获得一个自定义的类引用,然后又要在获得之前做些什么,我们可能一般也不会这么写吧,如下,引用某个博主的自行用法:
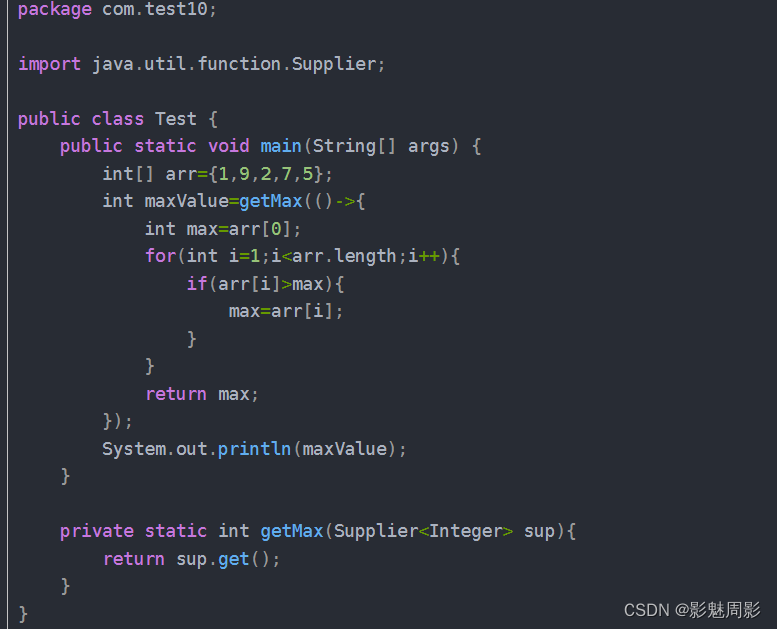
对于生产中,我个人认为,这个写法不便于维护以及理解的,特别是接收别人的项目时。
2)Consumer接口 - 消费型接口
· Consumer接口包含2个方法
· void accept(T t):对给定的参数执行此操作;
· default Consumer andThen(Consumer after):返回一个组合的Consumer,依次执行操作,然后执行after操作。
Consumer接口也称为消费型接口,其所消费的数据类型由泛型指定。
private static Logger logger = LoggerFactory.getLogger(TestLamdba.class);
public static void main(String[] args) {
//消费型接口
Consumer<String> str = s -> {
logger.info(s);
};
str.accept("消费型接口");
}
3)Function接口 - 函数式接口
Function包含多个方法,下面记录2个常用的。
· R apply(T t):将此函数应用于特定的参数;
· default<V> Function andThen(Function after):返回一个组合函数,先将该函数应用于输入,然后将after函数应用于结果。
· Function<T, R>:接口通常用于对参数进行处理,转换(处理逻辑由Lambda实现),然后返回一个新值。
Function function = s -> s;
logger.info("函数型接口:{}",function.apply("Function接口"));
4)Predicate接口 - 判定型接口
Predicate常用方法有4个:
· boolean test(T t):对给定参数进行判断(判断逻辑由Lambda实现),返回一个布尔值;
· default Predicate<T> negate():返回一个逻辑的否定,对应逻辑非(否);
· default Predicate<T> and(Predicate other):返回一个组合判断,对应逻辑与;
· default Predicate<T> or(Predicate other):返回一个组合判断,对应逻辑或;
Predicate 接口常用于判断参数是否满足指定条件
Predicate<String> predicate = s -> s.equals("Predicate 接口");
logger.info("判断型接口:{}",predicate.test("Predicate 接口"));
三、方法引用、构造器引用、数组引用
此特性基于Lambda表达式延申。
1、方法引用:
方法引用是Lamdba表达式的另一种表现形式,当Lambda表达式体的实现部分已经被书写实现了,就可以使用【方法引用】。
方法引用的表现形式大致分三种:
1)对象::实例方法名
2)类::静态方法名
3)类::实例方法名(Lambda参数列表中,第一个参数是实例方法名的调用者,第二个参数是实例方法的参数的时候,可以被使用)
示例:
package lamdba;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.function.BiFunction;
import java.util.function.Consumer;
public class TestLamdba {
private static Logger logger = LoggerFactory.getLogger(TestLamdba.class);
public static void main(String[] args) {
//原有Lambda表达式
Consumer<Integer> con1 = c -> System.out.println(c);
con1.accept(10);
//方法引用 -- 对象(System.out是对象)::实例方法(println是方法)
Consumer<Integer> con2 = System.out::println;
con2.accept(50);
//方法引用 -- 类名::静态方法名
BiFunction<Integer, Integer, Integer> biFun2 = Integer::compare;
Integer result = biFun2.apply(100, 200);
System.out.println(result);
//方法引用 -- 类名::实例方法名
String str1 = "hello";
String str2 = "hello";
BiFunction<String, String, Boolean> fun = String::equals;
fun.apply(str1,str2);
}
}
2、构造器引用:
构造器引用与上面方法引用的格式类似,用途也是类似:
格式:ClassName::new
示例:
// 构造方法引用 类名::new
Supplier<Student> sup = () -> new Student();
System.out.println(sup.get());
Supplier<Student> sup2 = Student::new;
System.out.println(sup2.get());
// 构造方法引用 类名::new (带一个参数)
Function<Integer, Student> fun = (x) -> new Student(x);
Function<Integer, Student> fun2 = Student::new;
System.out.println(fun2.apply(100));3、数组引用:
格式:Type[]::new
Function<Integer, String[]> fun = (x) -> new String[x];
Function<Integer, String[]> fun2 = String[]::new;
String[] strArray = fun2.apply(10);
Arrays.stream(strArray).forEach(System.out::println);四、Stream API
1、简介:
Stream是指流。流式编程是java8比较大的亮点之一,是继java5之后对集合的再一次升级。有了Stream API之后,可以一行代码完成集合类操作。
Stream的工作过程,可以比喻为一个多过滤阀门的管道工作,当水(源头)每经过一个阀门,就回被操作一次,经过多次的操作,最终得到结果:

如图,首先通过source产生stream流,而后通过中间操作(filter过滤、map转换、limit限制等等),最后得到结果。
Stream流等同于高级的迭代器,主要作用是遍历每一个元素。
2、简单示例:
package streamapi;
import copy.entity.Student;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class TestStream {
public static void main(String[] args) {
//假如我需要对一个Student集合进行筛选遍历,选出age>15的成员
List<Student> list = new ArrayList<>();
list.add(new Student("老子",20));
list.add(new Student("墨子",13));
list.add(new Student("韩非子",11));
//空集合用于存放结果
List<Student> resList = new ArrayList<>();
//以往的操作:for循环然后加入新集合返回
for (Student student : list) {
if(student.getAge()>15){
resList.add(student);
}
}
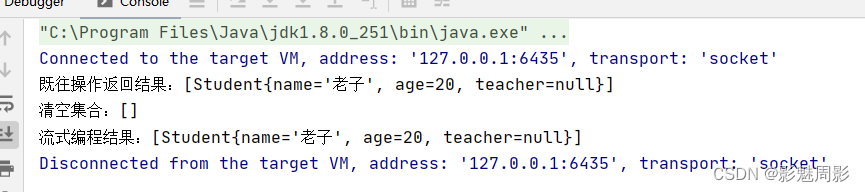
System.out.println("既往操作返回结果:"+resList);
resList.clear();
System.out.println("清空集合:"+resList);
//流操作
resList.addAll(list.stream().filter(student -> student.getAge()>15).collect(Collectors.toList()));
System.out.println("流式编程结果:"+resList);
}
}
3、主要操作步骤详解:
1)流创建(获取流)
stream流获取方式有多种,java中可以获取stream的对象也是多种。
常见容器(Colleaction)可以通过 .stream()方法直接取得流对象;
例如 --
Collection.stream();
Collection.parallelStream();
Arrays.stream(T array) or Stream().of();
。。。
对于IO,可以通过.lines()方法获取流;
例如 --
java.io.BuffferedReader.lines();
。。。
也可以通过无限大的数据源中产生流:
Random.ints();
同时,JDK针对基本数据类型的装箱、拆箱操作,也提供了基本数据类型的流:
IntStream;
LongStream;
DoubleStream;
。。。
2)流中间操作(操作流对象)
流的操作类型,可以分为两种:
一是中间操作,中间操作的方法记录此处;二是终结操作,记录在下面第3)点。
流中间操作的返回值基本上是Stream<T>,如果遇到不熟悉的API也可以通过流返回类型判断所属。
a、map/flatMap转换
map映射操作格式:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
示例:
//假如我需要对一个Student集合进行筛选遍历,选出age>15的成员
List<Student> list = new ArrayList<>();
list.add(new Student("老子",20));
list.add(new Student("墨子",13));
list.add(new Student("韩非子",11));
//map提取list的名字
List<String> nameList = list.stream().map(Student::getName).collect(Collectors.toList());
System.out.println("stream的map操作提取name:"+nameList);
//flatMap顾名思义就是扁平化映射,它具体的操作是将多个stream连接成一个stream,这个操作是针对类似多维数组的,比如容器里面包含容器等
List<List<Integer>> ints=new ArrayList<>(Arrays.asList(Arrays.asList(1,2),
Arrays.asList(3,4,5)));
//通过flatMap,将上述多维数组list直接转化为普通list
List<Integer> flatInts=ints.stream().flatMap(Collection::stream).
collect(Collectors.toList());
System.out.println("stream的flatMap操作转化多维list:"+flatInts);
b、filter过滤
filter是等同于一个过滤器,通过筛选后的元素被留下,生成一个新stream。格式:
Stream<T> filter(Predicate<? super T> predicate);
示例:如上2、简单示例
resList.addAll(list.stream().filter(student -> student.getAge()>15).collect(Collectors.toList()));c、distinct去重
//distinct去重
List<String> list = new ArrayList<>(Arrays.asList("abc","abc"));
System.out.println(list);
List<String> disList = list.stream().distinct().collect(Collectors.toList());
System.out.println(disList);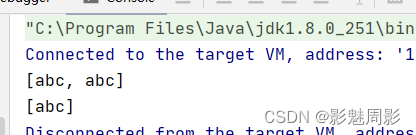
d、sorted排序
//sorted排序
List<Integer> list = new ArrayList<>(Arrays.asList(1,3,2));
list = list.stream().sorted().collect(Collectors.toList());
System.out.println(list);
e、peek遍历,类似于forEach
//peek遍历
List<String> list = new ArrayList<>(Arrays.asList("abc","abc","cde"));
list.stream().peek(System.out::println).collect(Collectors.toList());f、limit裁剪返回头部
limit(long L)方法可以为对象保留前L位元素,并返回一个新stream对象。
//peek遍历
List<String> list = new ArrayList<>(Arrays.asList("abc","abc","cde"));
list.stream().peek(System.out::println).collect(Collectors.toList());
//limit裁剪操作
list = list.stream().limit(2).collect(Collectors.toList());
System.out.println(list);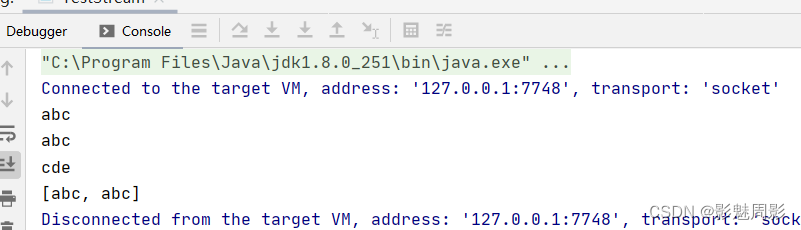
g、skip裁剪返回尾部
skip(long L)方法为对象保留后L位元素,并返回一个新stream对象。
//peek遍历
List<String> list = new ArrayList<>(Arrays.asList("abc","abc","cde"));
list.stream().peek(System.out::println).collect(Collectors.toList());
//skip裁剪操作
list = list.stream().skip(2).collect(Collectors.toList());
System.out.println(list);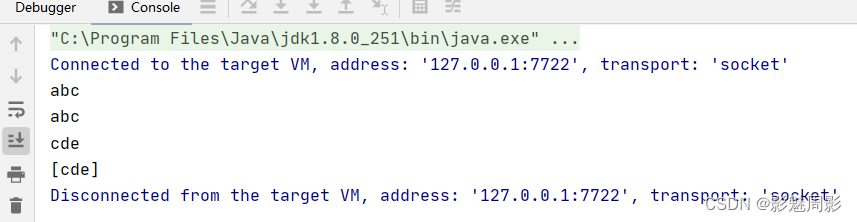
3)流结束(终结)操作返回结果
List<String> list = new ArrayList<>(Arrays.asList("abc","abc","cde"));
//终结操作:forEach
list.stream().forEach(System.out::println);一个流处理过程中,终结操作只能有一个,通过终结操作后,流视为被真正处理,流终结操作返回的类型一般为我们自己需要的类型,一般不会再返回stream流。
a、forEach
forEacn是终结操作的遍历,作用与peek一样,但是结果不再返回流。
List<String> list = new ArrayList<>(Arrays.asList("abc","abc","cde"));
//终结操作:forEach
list.stream().forEach(System.out::println);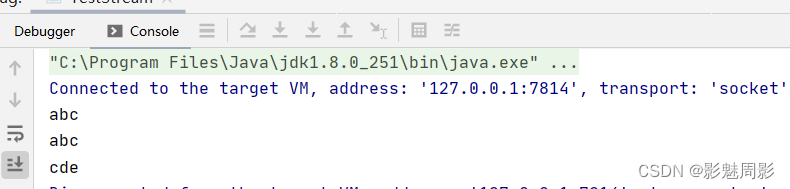
b、toArray
返回一个数组,可以指定数据类型
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);
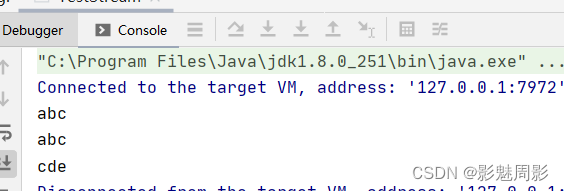
List<String> list = new ArrayList<>(Arrays.asList("abc","abc","cde"));
//终结操作:toArray
String[] array = list.stream().toArray(String[]::new);
for (String s : array) {
System.out.println(s);
}
c、max/min
找出最大或最小值。使用max/min需要传入一个Comparator。
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);
d、count
返回流对象的元素个数
//流终结操作:count()
List<Integer> list = new ArrayList<>(Arrays.asList(1,3,5));
long count = list.stream().count();
System.out.println(count);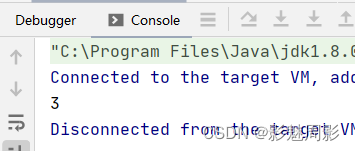
e、reduce
reduce为归纳操作,主要是将流中各个元素结合起来,它需要提供一个起始值,然后按一定规则进行运算,比如相加等,它接收一个二元操作 BinaryOperator函数式接口。从某种意义上来说,sum,min,max,average都是特殊的reduce。
reduce包含三个重载:
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
例如:
//流终结操作:reduce
List<Integer> integers = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
long count = integers.stream().reduce(0,(x,y)->x+y);
//等同于:
long count = integers.stream().reduce(Integer::sum).get();reduce两个参数和一个参数的区别在于有没有提供一个起始值,
如果提供了起始值,则可以返回一个确定的值,如果没有提供起始值,则返回Opeational防止流中没有足够的元素。
f、anyMatch\ allMatch\ noneMatch
测试是否有任意元素\所有元素\没有元素匹配表达式
他们都接收一个推断类型的函数式接口:Predicate
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate)
boolean test = integers.stream().anyMatch(x->x>3);g、findFirst、 findAny
获取元素,这两个API都不接受任何参数,findFirt返回流中第一个元素,findAny返回流中任意一个元素。
Optional<T> findFirst();
Optional<T> findAny();
h、collect
collect收集操作,这个API放在后面将是因为它太重要了,基本上所有的流操作最后都会使用它。
我们先看collect的定义:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
可以看到,collect包含两个重载:
一个参数和三个参数,
三个参数我们很少使用,因为JDK提供了足够我们使用的Collector供我们直接使用,我们可以简单了解下这三个参数什么意思:
Supplier:用于产生最后存放元素的容器的生产者
accumulator:将元素添加到容器中的方法
combiner:将分段元素全部添加到容器中的方法
前两个元素我们都很好理解,第三个元素是干嘛的呢?因为流提供了并行操作,因此有可能一个流被多个线程分别添加,然后再将各个子列表依次添加到最终的容器中。
↓ - - - - - - - - -
↓ --- --- ---
↓ ---------
如上图,分而治之。
例如:
List<String> result = stream.collect(ArrayList::new, List::add, List::addAll);
接下来看只有一个参数的collect
一般来说,只有一个参数的collect,我们都直接传入Collectors中的方法引用即可:
List<Integer> = integers.stream().collect(Collectors.toList());
Collectors中包含很多常用的转换器。toList(),toSet()等。
Collectors中还包括一个groupBy(),他和Sql中的groupBy一样都是分组,返回一个Map
例如:
//按学生年龄分组
Map<Integer,List<Student>> map= students.stream().
collect(Collectors.groupingBy(Student::getAge));
groupingBy可以接受3个参数,分别是
第一个参数:分组按照什么分类
第二个参数:分组最后用什么容器保存返回(当只有两个参数是,此参数默认为HashMap)
第三个参数:按照第一个参数分类后,对应的分类的结果如何收集
有时候单参数的groupingBy不满足我们需求的时候,我们可以使用多个参数的groupingBy:
例如 --
//将学生以年龄分组,每组中只存学生的名字而不是对象
Map<Integer,List<String>> map = students.stream().
collect(Collectors.groupingBy(Student::getAge,Collectors.mapping(Student::getName,Collectors.toList())));五、并行流、串行流
1、并行流(parallelStream)与串行流(Stream)
串行流 Stream 与并行流 parallelStream_java stream 并行串行流-CSDN博客
并行流与串行流是基于第四点的stream流衍生的。也就是stream与parallelStream的使用。具体可以参考上述文章,需要记住并行流是线程不安全的,其他的这里不描述。
2、ForkJoin框架(JDK1.7特性)
说到并行流,就需要说一下frok join框架。因为fork join框架就是类似于并行流parallel Stream,用于并行执行任务的。而java8的并行流parallelStream是使用的forkjoin底层框架进行并行操作的。所以可以知道一下。
六、Optional容器
1、简介:
Optional<T>类(java.util.Optional)是一个容器类。代表一个值存在或不存在。原来是使用一个null表示一个值不存在,现在Optional可以更好的表达这个概念,并且可以避免空指针异常。
2、常用方法:
1)Optional.of(T t):创建一个Optional实例
//Optional.of:创建一个Optional实例
Optional<Student> oStu = Optional.of(new Student("刘亦菲",18));
System.out.println(oStu.get());Optional.of创建的实例不能传入null值,否则会报空指针异常,可以借助这个特性快速定位错误。
2)Optional.empty():创建一个空的 Optional 实例
//Optional.empty:创建一个空的Optional实例
Optional<Object> empty = Optional.empty();
System.out.println(empty.get());//报错java.util.NoSuchElementException: No value present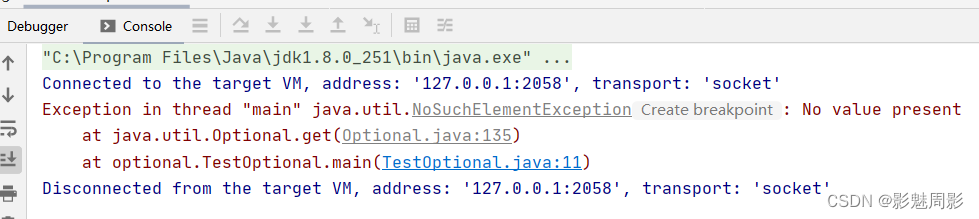
3)Optional.ofNullable(T t):若 t 不为 null,创建 Optional 实例,否则创建空实例,该方法是of()和empty()的组合,如果为empty时调用get()会报异常NoSuchElementException
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}4)isPresent():判断容器中是否包含值,用此方法可避免NoSuchElementException异常
Optional<Object> ofNullable = Optional.ofNullable(null);
if (ofNullable.isPresent())//若有值则执行if逻辑
System.out.println(ofNullable.get());5)orElse(T t):如果调用对象包含值,返回该值,否则返回t,此方法也可以避免出现空指针异常
Optional<Employee> op = Optional.ofNullable(null);
Employee orElse = op.orElse(new Employee("zhangsan"));
System.out.println(orElse);6)orElseGet(Supplier s):如果调用对象包含值,返回该值,否则返回 s 获取的值,与orElse不同的是,这里返回的值是在函数中返回的,可以有更多的逻辑判断具体返回哪个值
Optional<Employee> op = Optional.ofNullable(null);
Employee orElseGet = op.orElseGet(Employee::new);//可以通过Supplier写各种逻辑
System.out.println(orElseGet);7)map(Function f):如果有值对其处理,并返回处理后的Optional,否则返回Optional.empty(),通过map将原容器中的类型映射为新容器中的类型
Optional<Employee> op = Optional.of(new Employee("张三"));
Optional<String> map = op.map(e -> e.getName());//通过map将原容器中的类型映射为新容器中的类型
System.out.println(map.get());
8)flatMap(Function mapper):与 map 类似,但要求Function 的返回值必须是Optional类型,可实现流数据的扁平化等
Optional<Employee> op = Optional.of(new Employee("张三"));
Optional<String> flatMap = op.flatMap((e) -> Optional.of(e.getName()));
System.out.println(flatMap.get());七、新的日期API
在java8之前,通常使用Date时需要结合SimpleDateFormat、Calender来处理时间喝日期的相关需求(例如格式化存入等),但是这些相关类通常存在以下问题:
1、可读性差、易用性差,使用时冗余繁琐;
2、java.util.Date是非线程安全的,也不支持国际化和时区;
3、java.util与Java.sql都包含有Date类,容易混淆等。
而java8中,在java.time包下,重新实现了日期相关的实用类,其主要有以下的优点:
1、解决了线程安全问题,原有的Date类是非线程安全的;这些新的类使用final修饰,使得不可变,一旦实例化就固定了类似String类,不会导致线程问题;
2、解决了时区处理的复杂度;类中可选时区操作,可指定时区;
3、解决了原有格式化日期、计算日期时间的复杂度;默认情况下直接获取实例时以本地时间格式返回,无需再转换。
下面我只记录一部分简单内容,如果需要详细去了解使用,可以直接参考这个博主的文章,非常详细:
Java8日期类LocalDate、LocalTime、LocalDateTime使用详解-CSDN博客
新增的类主要有以下三个:
1、LocalDate类:表示日期(年月日)
常用API:
| 方法 | 描述 |
| static LocalDate now() | 获取默认时区的当前日期对象 |
| static LocalDate now(Clock clock) | 从指定时钟获取当前日期对象 |
| static LocalDate now(ZoneId zone) | 获取指定时区的当前日期对象 |
| of | 根据指定年月日创建LocalDate对象 |
| getYear | 获得年份 |
| getMonthValue | 获得月份(1-12) |
| getMonth | 获得月份枚举值 |
| getDayOfMonth | 获得月份中的第几天(1-31) |
| getDayOfWeek | 获得星期几 |
| getDayOfYear | 获得年份中的第几天(1-366) |
| lengthOfYear | 获得当年总天数 |
| lengthOfMonth | 获得当月总天数 |
| toEpochDay | 与时间纪元(1970年1月1日)相差的天数 |
| plusDays | 加天 |
| plusWeeks | 加周 |
| plusMonths | 加月 |
| plusYears | 加年 |
| minusDays | 减年 |
| minusWeeks | 减周 |
| minusMonths | 减月 |
| minusYears | 减年 |
| withYear | 替换年份 |
| withMonth | 替换月份 |
| withDayOfMonth | 替换月份中的第几天(1-31) |
| withDayOfYear | 替换年份中的第几天(1-366) |
| isBefore | 是否日期在之前 |
| isAfter | 是否日期在之后 |
| isEqual | 是否是当前日期 |
| isleapYear | 是否是闰年 |
//LocalDate,默认会使用本地日期表达格式
LocalDate localDate = LocalDate.now();
System.out.println(localDate);
//原有Date类格式化时需要进行转换
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date date = new Date();
System.out.println(sdf.format(date));
2、LocalTime类:表示时间(时分秒)
常用API:
| 方法 | 描述 |
| static LocalTime now() | 获取默认时区的当前时间 |
| static LocalTime now(ZoneId zone) | 获取指定时区的当前时间 |
| static LocalTime now(Clock clock) | 从指定时钟获取当前时间 |
| of | 根据指定的时、分、秒获取LocalTime 实例 |
| getHour | 获取小时 |
| getMinute | 获取分钟 |
| getSecond | 获取秒 |
| getNano | 获取纳秒 |
| plusHours | 增加小时数 |
| plusMinutes | 增加分钟数 |
| plusSeconds | 增加秒数 |
| plusNanos | 增加纳秒数 |
| minusHours | 减少小时数 |
| minusMinutes | 减少分钟数 |
| minusSeconds | 减少秒数 |
| minusNanos | 减少纳秒数 |
| withHour | 替换小时 |
| withMinute | 替换分钟 |
| withSecond | 替换秒钟 |
| withNano | 替换纳秒 |
| compareTo | 时间与另一个时间比较 |
| isAfter | 检查时间是否在指定时间之后 |
| isBefore | 检查时间是否在指定时间之前 |
LocalTime time = LocalTime.now();
System.out.println(time);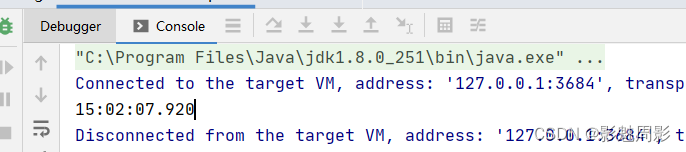
3、LocalDateTime类:日期结合时间,最常用
常用API:
| 方法 | 描述 |
| static LocalDateTime now() | 获取默认时区的当前日期时间 |
| static LocalDateTime now(Clock clock) | 从指定时钟获取当前日期时间 |
| static LocalDateTime now(ZoneId zone) | 获取指定时区的当前日期时间 |
| static LocalDateTime of(LocalDate date, LocalTime time) | 根据日期和时间对象获取LocalDateTime 对象 |
| static LocalDateTime of(int year, Month month, int dayOfMonth, int hour, int minute, int second) | 根据指定的年、月、日、时、分、秒获取LocalDateTime 实例 |
| getYear | 获取年份 |
| getMonth | 使用月份枚举类获取月份 |
| getDayOfMonth | 获取日期在该月是第几天 |
| getDayOfWeek | 获取日期是星期几 |
| getDayOfYear | 获取日期在该年是第几天 |
| getHour | 获取小时 |
| getMinute | 获取分钟 |
| getSecond | 获取秒 |
| getNano | 获取纳秒 |
| plusYears | 增加年 |
| plusMonths | 增加月 |
| plusWeeks | 增加周 |
| plusDays | 增加天 |
| plusHours | 增加小时 |
| plusMinutes | 增加分 |
| plusSeconds | 增加秒 |
| plusNanos | 增加纳秒 |
| minusYears | 减少年 |
| minusMonths | 减少月 |
| meminusWeeks | 减少周 |
| minusDays | 减少天 |
| minusHours | 减少小时 |
| minusMinutes | 减少分 |
| minusSeconds | 减少秒 |
| minusNanos | 减少纳秒 |
| withYear | 替换年份 |
| withMonth | 替换月份 |
| withDayOfMonth | 替换月份中的第几天(1-31) |
| withDayOfYear | 替换年份中的第几天(1-366) |
| withHour | 替换小时 |
| withMinute | 替换分钟 |
| withSecond | 替换秒钟 |
| withNano | 替换纳秒 |
| isEqual | 判断日期时间是否相等 |
| isBefore | 检查是否在指定日期时间之前 |
| isAfter | 检查是否在指定日期时间之后 |
package datetimeApi;
import java.time.*;
import java.time.format.DateTimeFormatter;
public class TestDateTimeApi {
public static void main(String[] args) {
LocalDateTime dateTime = LocalDateTime.now();
//格式转换
String dateTimeStr = "yyyy-MM-dd HH:mm:ss";
DateTimeFormatter dtf = DateTimeFormatter.ofPattern(dateTimeStr);
System.out.println(dateTime.format(dtf));
}
}
八、其他
jdk的每个版本,其实都具备很多的特性,有时候并非一个两个,这个需要个人自行去关注,而目前本篇文章主要记录一些常用的特性(比如项目中必定会使用的集合而会用到Stream流,时间日期的API既然有优化的,肯定可以有限考虑使用等)。
也建议大家可以在IDEA中去引入sonarLint工具,尽可能按最新的格式规范去编码,它也会提示你使用一些新特性编码,并告诉你不规范点在哪里。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









