










文章目录
前言
本文主要是使用Java语言来进行单链表的编写的。
一、简述单链表
1、单链表是什么
1.从数据结构的层面来叙述
- 在物理结构上来看,单链表地址不连续,是以乱序的方式在我们的计算机存储的。
- 在逻辑结构上来看,单链表又有着一一关联的特点。就像一串牛肉丸一样,正常来讲你需要吃掉第一课牛肉丸才能吃下一颗牛肉丸,而站在牛肉丸视角上来讲。它只能看到前一颗牛肉丸和后一颗牛肉丸一样。这个基础建立在牛肉丸大小相同的情况下,而在单链表也确实如此,因为无论是那个节点都需要去存储相同类型的数据。但牛肉丸串的例子更适合顺序表来讲。
2.从时间复杂度和空间复杂度的角度来叙述
- 从所占用的内存空间上来讲,单链表比顺序表更用天高独厚的优势,为什么呢?我们知道顺序表的底层是利用动态数组来实现的,动态数组的实现总是需要进行一个copy操作,对于顺序表的动态数组可以看看我这篇文章[(https://blog.csdn.net/chechehuibujiano/article/details/124318459?spm=1001.2014.3001.5501)]当在copy操作时候,在堆中其实是两个数组,这就会造成存储空间的浪费。而单链表需要的只是一个存储下一个元素的地址,这个相较于多余数组空间浪费的位置不值一提。
- 然后就是从时间复杂度来讲,单链表实现的插入和删除和清空操作时间复杂度都是为O(1),而顺序表的插入和时间复杂度为O(n)。但在查找指定下标元素的操作上
来讲顺序表的时间复杂度就是常熟级别了,对于单链表来讲查找的时间复杂度就是
O(n)。对于按值查找的操作,两者时间复杂度都是O(n)。
二.单链表的API设计,实现
1,单链表的API原型
这里我还是引用黑马程序员的对单链表的API设计的图
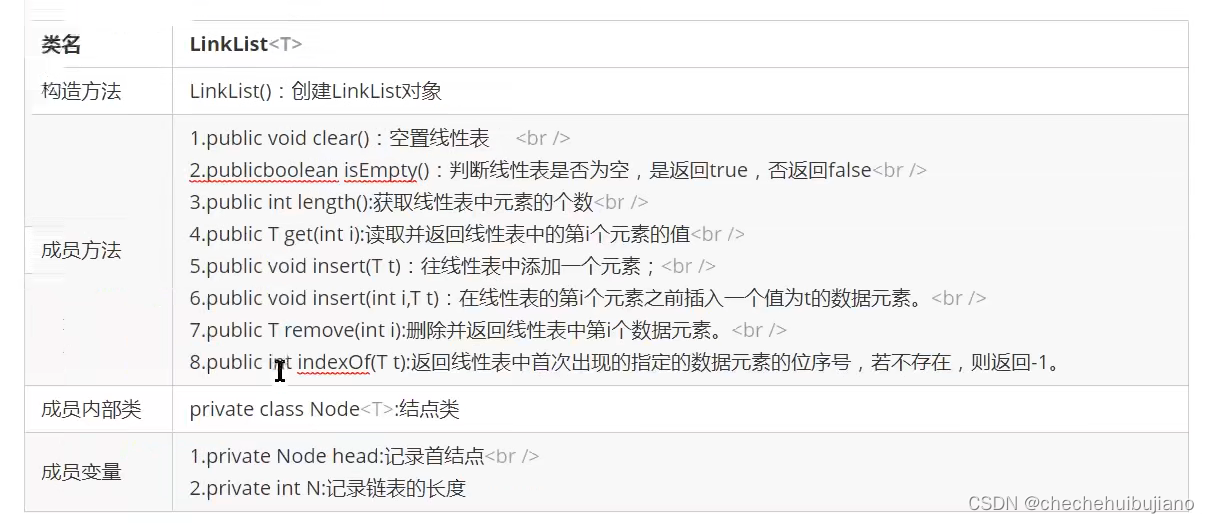
public class LinkList<T> {
//成员变量
private Node head;//记录头节点
private int N;//记录链表长度
//重构LinkList的无参构造器
public LinkList() {
}
}
//创建内部类
private class Node{
}
//空置链表
public void clear(){
}
//判断链表是否为空,是返回true,否的返回false
public boolean isEmpty(){
}
//获取链表中元素个数
public int length(){
}
//往链表中添加一个数据为T的元素
public void insert(T t){
}
//读取并返回链表中第i个元素的值
public T get(int i){
}
//在链表第i个元素之前插入一个值为t的数据元素
public void insert(T t,int i){
}
//删除并返回链表中第i个元素
public void remove(int i){
}
//返回链表中首次出现的指定数据元素的位序号,若不存在,则返回-1
public int indexOf(T t){
}
}
2.内部类的实现
我们的内部类是节点接下来我们来看看这副图
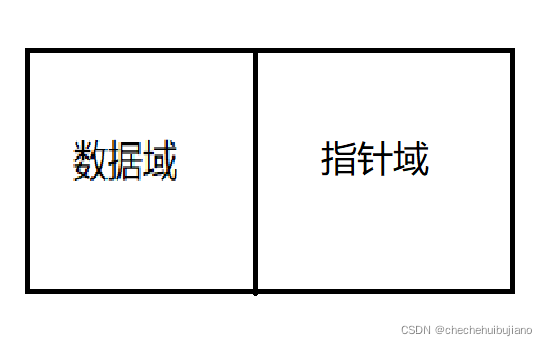
我们可以知道这个Node需要存放数据还需要存放指向下一个数据域的地址。所以我们我们可以这样来设置我们的Node
private class Node{
//需要记录当前节点数据
T item;
//需要记录下一个节点的位置
Node next;
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
然后我们还给Node类重新写了一个构造器,这个构造器就是我们下面要对节点进行赋值的指向的关键步骤
3.LinkList类的无参构造器
我们首先要确定LinkList类的无参构造器应该干点什么呢?
我们首先要想一个单链表,从宏观上需要点什么?首先一定需要存储数据元素,次之应该存储一个表的表头,为什么需要存储表头呢?
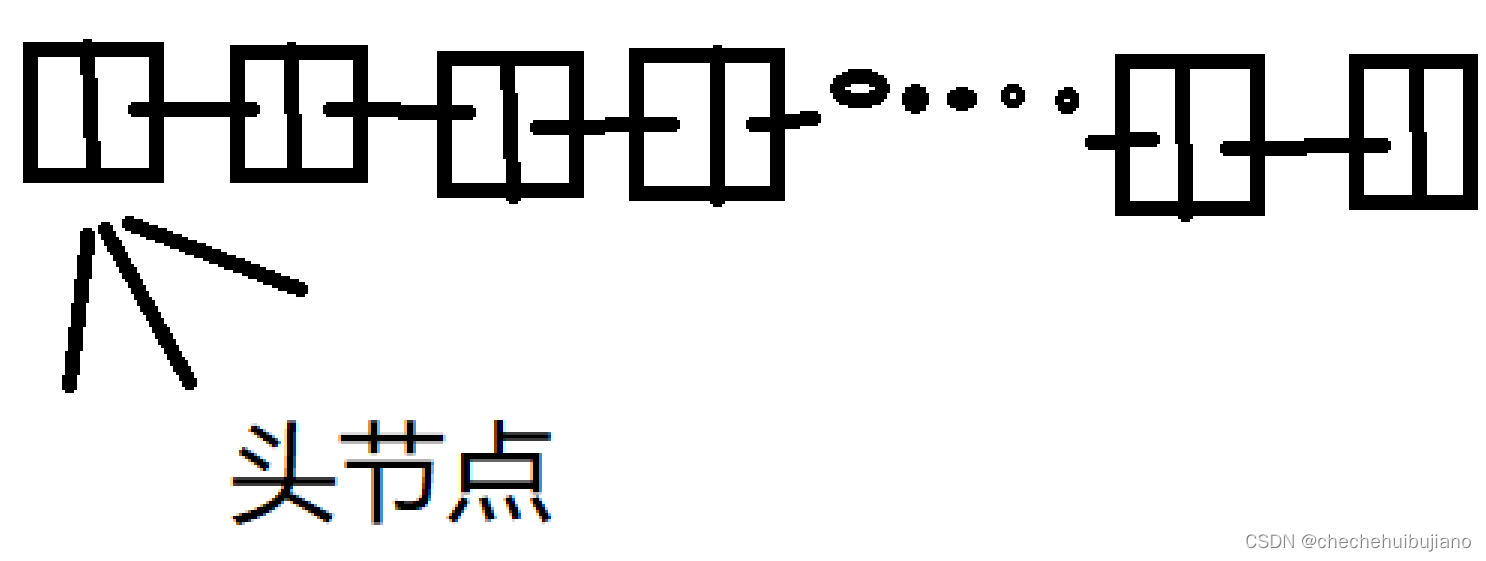
这里我给大家画了幅图,我们可以看出头节点是链接整个单链表的关键,没有头节点的话就会出现找不到下一个数据的情况,而且头节点不存储数据。
所以最后定义LinkList类的无参构造器代码我们可以这样去写
public LinkList() {
//初始化头节点
this.head = new Node(null,null);
//初始化元素个数
this.N = 0;
}
4.简单的API实现
这里我统称时间复杂度为O(1)的操作为简单操作,这部分的操作原因,我会以注释给出。
//空置链表
public void clear(){
//将头节点的指针域置空,不能访问下一个节点就相当于将链表空置
head.next = null;
N = 0;
}
//判断链表是否为空,是返回true,否的返回false
public boolean isEmpty(){
//直接判断头节点是否有指向下一个节点,道理和空置链表相同
return head.next == null;
}
//获取链表中元素个数
public int length(){
//因为N是存储节点数量的变量,所以直接返回它就好了
return N;
}
这里我补充一个简单操作,这个操作与顺序表的按值查找的操作相似,这里就不过多赘叙。
//返回链表中首次出现的指定数据元素的位序号,若不存在,则返回-1
public int indexOf(T t){
Node curr = head;
for (int index = 0; index < N; index++) {
curr = curr.next;
if (curr.item.equals(t)) {
return index;
}
}
return -1;
5.插入API的实现
我们先用代码来展示我们的插入操作,这里有两个插入操作,这里涉及了方法的重载。
- 第一种——是在尾部进行插入
public void insert(T t){
/*
目标:往最后一个节点之后增加节点
*/
//1.进行遍历,找到最后一个节点
Node curr = head;//创建一个新节点,让它等于头节点,可以往后遍历整个单链表
for (int i = 0; i <= N-1; i++) {
curr = curr.next;
}
//2.创造一个数据域为t,指针域为空的新节点
Node newNode = new Node(t,null);
//3.让最后一个节点指向新节点
curr.next = newNode;
//4.让节点数量增加一
N++;
}
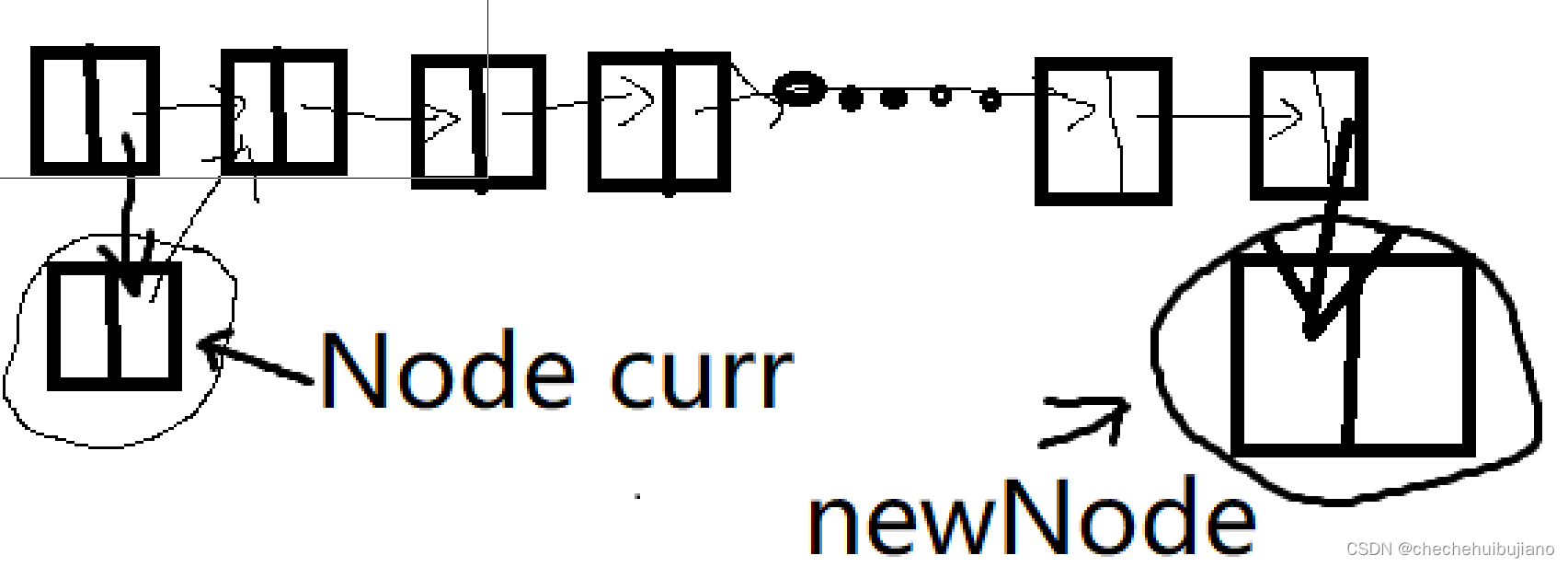
步骤如下:
- 创建一个新节点,让它等于头节点,可以往后遍历整个单链表
- 进行遍历,找到最后一个节点
- 创造一个数据域为t,指针域为空的新节点
- 让最后一个节点指向新节点
- 让节点数量增加一
我们进行这个操作用图来表示的话,就是如下图
2. 按下表值插入
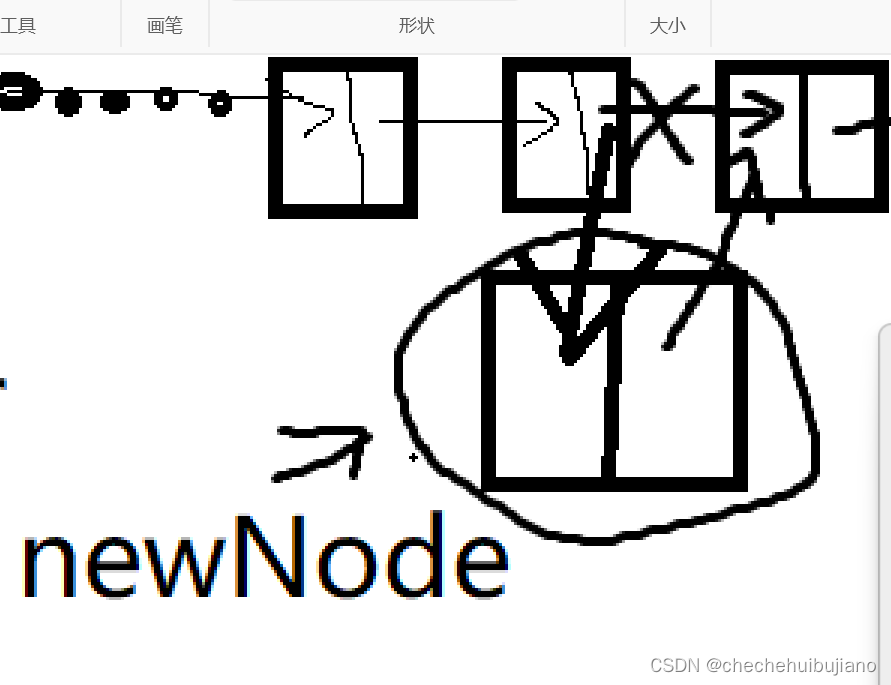
//在链表第i个元素之前插入一个值为t的数据元素
public void insert(T t,int i){
//遍历链表,注意要判断i是否合理
if (i < 0||i > N) {
return;
}
//首先节点数目加一
N++;
//如果索引是最后一个元素,直接使用从尾部插入
if (i == N-1) {
insert(t);
return;
}
Node pre = head;//创建一个新节点,让它等于头节点,可以往后遍历整个单链表
for (int index = 0; index < i-1; index++) {
pre = pre.next;
}
//创建一个新节点,将pre的指针域赋值给它的指针域
Node newNode = new Node(t,pre.next);
//让pre节点的后继节点直接指向下一个节点
pre.next = newNode;
}
这种插入方法实现的步骤是:
- 遍历链表,注意要判断i是否合理
- 合理的话,首先节点数目加一并且创建一个新节点,让它等于头节点,可以往后遍历整个单链表
- 创建一个新节点,将pre的指针域赋值给它的指针域
- 让pre节点的后继节点直接指向下一个节点
注意:
我们遍历的话是遍历到我们插入位置的前面一个位置
6.删除API的实现
//删除并返回链表中第i个元素
public Node remove(int i){
//先判断索引是否合法
if (i < 0||i > N) {
return null;
}
Node curr = head;
//先让它指向要删除元素的前一个元素
for (int index = 0; index < i-1; index++) {
curr = curr.next;
}
//将删除节点进行记录
Node removeNode = curr.next;
//然后改变这个元素指针域,让它本来指向下一个一个元素变成指向下一个元素的下一个元素指针域
curr.next = curr.next.next;
N--;
return removeNode;
}
我们进行这个操作用图来表示的话,就是如下图展示一般
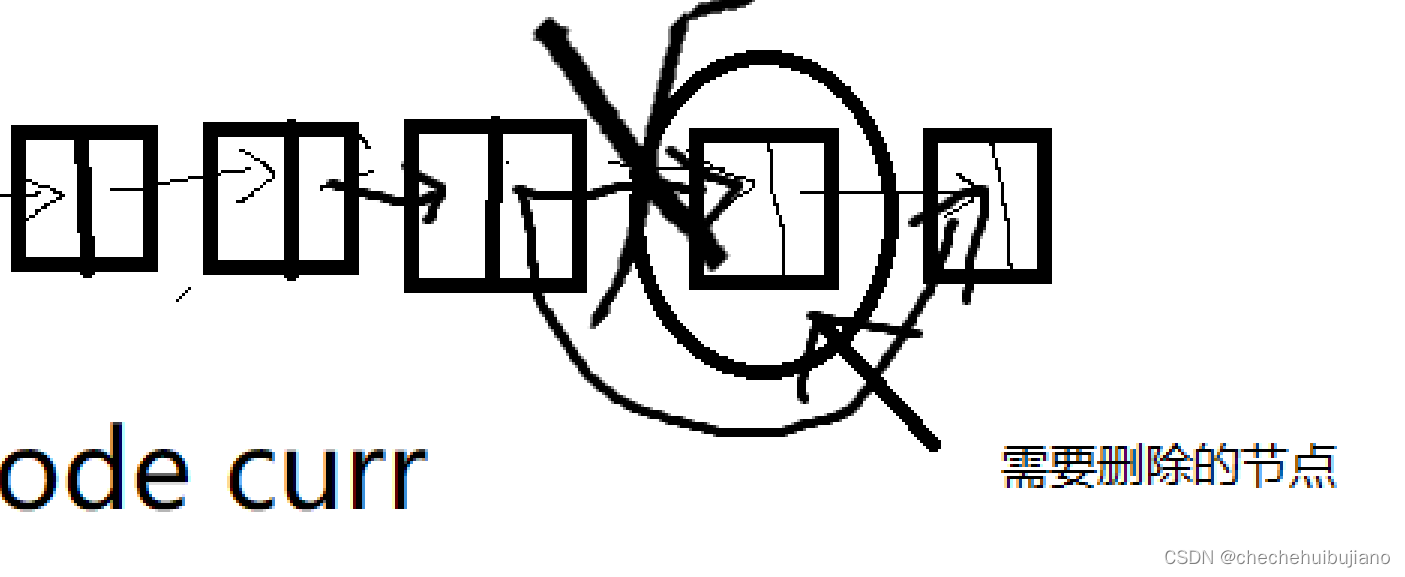
我们要进行删除步骤如下:
- 先判断索引是否合法
- 然后改变这个元素指针域,让它本来指向下一个一个元素变成指向下一个元素的下一个元素指针域
下一个一个元素变成指向下一个元素的下一个元素指针域 原因:
这个是改变元素指向的关键!就是将下个元素忽略掉。
三.迭代器的实现
迭代器的使用我们需要实现iterator这个接口,还要实现Iterator接口。
- 实现iterator接口
//迭代器的声明
@Override
public Iterator iterator() {
return new SLinkList(head);
}
解释SLinkList(head)需要看实现Iterator接口的方式
- 实现Iterator接口
//迭代器的实现
public class SLinkList implements Iterator{
//成员变量
private Node node;
//构造器
public SLinkList(Node node) {
this.node = head;
}
//判断有无后继元素
@Override
public boolean hasNext() {
return node.next != null;
}
@Override
public Object next() {
node = node.next;
return node.item;
}
}
SLinkList这个也是一个实现类,我们只需重写hasNext方法和next方法就可以实现我们迭代的功能。
SLinkList这个类的作用就是为了实现遍历的,所以我们会在它的构造器中传入头节点
四.具体的代码实现
package com.dataStucture.lister.linkList;
import java.util.Iterator;
/**
* @program:IntelliJ IDEA
* @Description:研究单链表的实现
* @author:Mr.CheCheHuiBujianO
* @data: 2022/4/24 17:19
*/
//在LinkList类中一样可以装迭代器
public class LinkList<T> implements Iterable<T> {
//成员变量
private Node head;//记录头节点
private int N;//记录链表长度
//创建LinkList对象
public LinkList() {
//初始化头节点
this.head = new Node(null,null);
//初始化元素个数
this.N = 0;
}
//迭代器的声明
@Override
public Iterator iterator() {
return new SLinkList(head);
}
//迭代器的实现
public class SLinkList implements Iterator{
//成员变量
private Node node;
//构造器
public SLinkList(Node node) {
this.node = head;
}
//判断有无后继元素
@Override
public boolean hasNext() {
return node.next != null;
}
@Override
public Object next() {
node = node.next;
return node.item;
}
}
//创建内部类
private class Node{
//需要记录当前节点数据
T item;
//需要记录下一个节点的位置
Node next;
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
//空置链表
public void clear(){
//将头节点的指针域置空,不能访问下一个节点就相当于将链表空置
head.next = null;
N = 0;
}
//判断链表是否为空,是返回true,否的返回false
public boolean isEmpty(){
//直接判断头节点是否有指向下一个节点,道理和空置链表相同
return head.next == null;
}
//获取链表中元素个数
public int length(){
//因为N是存储节点数量的变量,所以直接返回它就好了
return N;
}
//往链表中添加一个数据为T的元素
public void insert(T t){
/*
目标:往最后一个节点之后增加节点
*/
//1.进行遍历,找到最后一个节点
Node curr = head;//创建一个新节点,让它等于头节点,可以往后遍历整个单链表
for (int i = 0; i <= N-1; i++) {
curr = curr.next;
}
//2.创造一个数据域为t,指针域为空的新节点
Node newNode = new Node(t,null);
//3.让最后一个节点指向新节点
curr.next = newNode;
//4.让节点数量增加一
N++;
}
//读取并返回链表中第i个元素的值
public T get(int i){
//遍历链表,注意要判断i是否合理
if (i < 0||i > N+1) {
return null;
}
Node curr = head;//创建一个新节点,让它等于头节点,可以往后遍历整个单链表
for (int index = 0; index < i; index++) {
curr = curr.next;
}
return curr.item;
}
//在链表第i个元素之前插入一个值为t的数据元素
public void insert(T t,int i){
//遍历链表,注意要判断i是否合理
if (i < 0||i > N) {
return;
}
//首先节点数目加一
N++;
//如果索引是最后一个元素,直接使用从尾部插入
if (i == N-1) {
insert(t);
return;
}
Node pre = head;//创建一个新节点,让它等于头节点,可以往后遍历整个单链表
for (int index = 0; index < i-1; index++) {
pre = pre.next;
}
//创建一个新节点,将pre的指针域赋值给它的指针域
Node newNode = new Node(t,pre.next);
//让pre节点的后继节点直接指向下一个节点
pre.next = newNode;
}
//删除并返回链表中第i个元素
public Node remove(int i){
//先判断索引是否合法
if (i < 0||i > N) {
return null;
}
Node curr = head;
//先让它指向要删除元素的前一个元素
for (int index = 0; index < i-1; index++) {
curr = curr.next;
}
Node removeNode = curr.next;
//然后改变这个元素指针域,让它本来指向下一个一个元素变成指向下一个元素的下一个元素指针域
curr.next = curr.next.next;
N--;
return removeNode;
}
//返回链表中首次出现的指定数据元素的位序号,若不存在,则返回-1
public int indexOf(T t){
Node curr = head;
for (int index = 0; index < N; index++) {
curr = curr.next;
if (curr.item.equals(t)) {
return index;
}
}
return -1;
}
}
总结
这次的单链表的API编写我认为是较为之简单的,但是这个单链表的难点在于编写内部类信息,我们应该放点什么进去,在单链表整个类中构造器我们应该设置什么进去。
这一次编写,我觉得如果我们对类的成员变量,构造器的问题。我们可以从宏观上看整个类中我们该放点什么,什么是关键,能连接全体的东西。内部类的话我们就应该从微观的角度看,我们需要它实现什么功能,实现这个功能我们需要内部类有什么成员变量。
就像单链表贯穿整个数据结构的关键就是头节点,所以我们会选择将头节点放在宏观大类下,而我们需要存储内容和指向下个节点的数据,我们会选择去选择放在内部类Node下。














 4706
4706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









