









 本文介绍了POET模型,一个结合CNN和Transformer的端到端可训练的多实例姿态估计框架。受DETR启发,POET将姿态识别转化为集合预测问题,使用Transformer编码器-解码器和二部图匹配,无需后处理即可预测所有个体姿态。在COCO关键点检测任务中,POET表现出色,特别是在处理大目标人体时。未来工作将聚焦于提升小目标人体识别准确率和模型收敛速度。
本文介绍了POET模型,一个结合CNN和Transformer的端到端可训练的多实例姿态估计框架。受DETR启发,POET将姿态识别转化为集合预测问题,使用Transformer编码器-解码器和二部图匹配,无需后处理即可预测所有个体姿态。在COCO关键点检测任务中,POET表现出色,特别是在处理大目标人体时。未来工作将聚焦于提升小目标人体识别准确率和模型收敛速度。
[论文阅读:姿态识别&Transformer] 2103 POET: End-to-End Trainable Multi-Instance Pose Estimation with Transformers
Swiss Federal Institute of Technology (苏黎世联邦理工学院)
paper https://arxiv.org/abs/2103.12115
- 主要参照的是DETR,使用二部图匹配,将姿态识别问题转化为集合预测问题
- Bottom-up的端到端的多人姿态识别模型,同样是CNN Backbone+Transformer Encoder&Decoder
- 后续优化目标:如何提高小目标人体的姿态识别准确率,如何加速模型收敛,如何降低参数和计算量使在高分辨率输入情况下也能较为高效
摘要:
提出了一个新的端到端可训练的多实例(multi-instance)姿态估计模型,其结合了CNN和Transformer。我们将多实例图像姿态估计作为直接集合预测问题。受最近关于Transformer端到端可训练的目标检测工作的启发,我们使用Transformer编码器-解码器架构和二部图匹配(bipartite matching)方案来直接回归给定图像中所有个体的姿态。我们的模型称为POse Estimation Transformer(POET),使用一种新的基于集合的全局损失进行训练,该全局损失包括关键点损失、关键点可见性损失、中心损失和类损失。POET利用被检测的人与整个图像环境之间的关系来直接并行的预测姿态。结果表明,POET能够在具有挑战性的COCO关键点检测任务中实现较高的精度。据我们所知,该模型是第一个端到端可训练的多实例人体姿态估计方法。

图1. 在COCO关键点估计任务中,POET与完全卷积关联嵌入方法在encoder stride变化情况下的性能。尽管POET具有较低的分辨率特征,但仍然获得了较强的性能。
1.introduction
从单一图像中估计多人姿态,即预测每个人身体部位位置的任务,是计算机视觉的一个重要问题。姿态估计有广泛的应用,从医疗保健和生物学的行为测量到虚拟现实和人机交互。
多人姿态估计可以看作是一个层次化的集合预测任务。一个算法需要预测所有个体的身体部位,并将它们正确地分组归类为人体。由于这一过程的复杂性,目前的方法由多个步骤组成,并不是端到端可训练的。基本上,Top-down和Bottom-up的方法是主要的方法。Top-down方法首先基于目标检测算法预测所有个体的位置(bounding boxes),然后使用单独的网络预测每个裁剪个体的所有身体部位的位置。Bottom-up方法首先预测所有身体部位,然后将它们分组为个体。然而,这两种方法要么需要后处理, 要么需要两个不同的网络。这促使人们寻求端到端解决方案。
受最新的基于Transformer的目标检测体系结构DETR的启发,我们提出了一种新颖的端到端可训练的多实例姿态估计方法。POse Estimation Transformer(POET)是第一个端到端用于多实例姿态估计的模型,不需要像自上而下方法那样进行后处理或使用两个网络。POET无需任何后期处理就能预测所有人类姿势,并通过一个新颖但简单的损失函数进行训练,它允许预测的和真实的人类姿势之间的二部图匹配。我们的方法在难度较大的COCO关键点挑战上取得了出色的结果,特别是对于图像中占比较大的人体,即使在更高的空间分辨率下也比基线模型表现得更好(图1)。

2. 相关工作
2.1. Transformers in vision and beyond
Transformer被引入机器翻译,并极大地提高了语言任务中的深度学习模型的性能。它们的架构本质上允许建模和发现数据中的远程交互。其用途最近已经扩展到语音识别、自动定理证明和许多其他任务。在计算机视觉中,不管是结合使用CNN还是作为CNN的替代,Transformer都取得了巨大的效果。值得注意的是,Visual Transformer (ViT)在纯Transformer模型的图像识别任务上展示了最先进的性能。在其他可视化任务中,如文本到图像,已经显示了出色的结果,例如DALL-E。
最近,Carion等人开发了一种新的端到端模式,用于用Transformer检测视觉对象,这一任务以前需要两阶段方法或后处理。这种方法,即DETR,将目标检测定义为一个结合了二部图匹配损失的集合预测问题。DETR是一种优雅的解决方案,然而,该模型需要较长的训练时间,并且在小对象上表现得相对较差。这些问题通过进一步的工作得到了缓解; Deformable DETR提出了一种multi-scale Deformable Attention Module,针对不同尺度只关注feature map中的一定数量的点,从而减少了训练时间,提高了小目标检测性能。Sun等人去掉了Transformer解码器,并将来自CNN Backbone的特征输入到特征金字塔网络(27)。
重要的是,端到端的方法已经成功应用于许多复杂的预测任务,如语音识别或机器翻译,但多实例姿态估计中仍缺乏端到端的预测方法。
2.2. 姿态估计
多实例姿态估计方法(就是多人姿态估计)可分为自顶向下(Top-down)和自底向上(Bottom-up)两种。Top-down方法基于Bounding box用单独的网络定位个体(目标检测网络),再预测每个个体的每个身体部位的位置(单人姿态识别网络)。Bottom-up方法首先预测所有身体部位,然后通过部分亲和场(part affinity fields, OpenPose[9])、成对预测(pairwise predictions [10] [11] [14] [35] [36])、复合场(composite fields [13] [16])或关联嵌入(associative embeddings,[12] [15])将其分组。无论是Top-down还是Bottom-up的方法,都需要后处理步骤或两个不同的神经网络(用于定位人体和单人姿态估计)。
最新的(最先进的)方法是完全卷积和预测关键点热图。最近,Yang等人提出了TransPose(2021ICCV),这是一种Top-down的方法用于预测热图,是CNN backbone + Transformer Encoder的结构。Transformer还用于(单个)人体的3D姿势和mesh重建,在Human3.6M上达到了最先进的水平(End-to-end human pose and mesh reconstruction with transformers)。扩展这一工作,我们在DETR的基础上,提出了一个端到端可训练的多人姿态估计方法,直接将姿态作为向量输出(没有热图)。将姿态估计作为一个层次化的集合预测问题,我们采用CenterNet(36)和Single-Stage Multi-Person Pose Machines(14)的姿态表示。
3. POET框架总览
**POse Estimation Transformer(POET)**模型如图2所示。我们的工作与DETR密切相关,并从根本上将该目标检测框架扩展到多实例姿态估计。与DETR一样,POET由两个主要成分组成:
(1)基于Transformer的架构,可以并行地预测一组人类姿势;
(2)一个预测损失的集合,是类(class)、关键点坐标(keypoint coordinate)和可见性(visibilities)的简单子损失的线性组合。
为了将多实例的姿态估计作为一个集合预测问题,我们将每个个体的姿态表示为身体中心以及每个身体部位的相对偏移量。每个身体部位可以被遮挡或可见。POET被训练成直接输出一个包含中心、相对身体部位以及身体部位可见性(bool)的向量(图2b)。

图2. POET模型概述。a) POET结合CNN Backbone网络和Transformer,直接预测多个人的姿势。b)每个姿势被表示为一个向量,其中包括中心(xc,yc)、每个身体部位i的相对偏移量(∆xi,∆yi)及其可见性vi。c) POET通过与ground-truth姿势最接近的预测的二部图匹配进行端到端训练,然后反向传播损失。
3.1. POET Architecture
POET结构包含三个主要元素:
- 提取输入图像特征的CNN backbone
- 一个 encoder-decoder transformer
- 输出估计姿态集合的前馈网络头(FFN head)
3.2. CNN Backbone
图像 I ∈ R B × 3 × H × W I \in \mathbb{R}^{B \times 3 \times H\times W} I∈RB×3×H×W,作为输入, 其batch size为B, 3个颜色通道,图像尺寸(H,W)。输入到CNN Backbone中,通过几个计算和降采样步骤,CNN生成了较低分辨率的feature maps, F ∈ R B × C × H / S × W / S F\in \mathbb{R}^{B\times C\times H/S\times W/S} F∈RB×C×H/S×W/S with stride S。具体来说,我们选择不同的ResNets,具有不同的stride S,具体在实验部分中详细介绍。
3.3. Encoder-Decoder Transformer
编码器-解码器Transformer模型遵循标准Transformer架构。Encoder和decoder都由6个层组成,每个层有8个attention head。
该Encoder利用CNN Backbone的输出特性,通过1×1卷积降低其通道维数。这个下采样后的张量沿着空间维度折叠为一维,为multi-head机制提供序列化的输入。我们为Encoder输入添加一个固定位置编码(fixed positional encoding),因为Transformer架构是排列不变的,若不添加位置信息则会忽略图像的空间结构。
相反,Decoder的输入嵌入是可学习的位置编码(learned positional encodings),我们称之为object queries。由于排列不变性(permutation-invariance),这些queries必须是不同的,以便解码器产生不同的结果。它们和编码器输出相加作为解码器的输入。解码器将queries转换为output embeddings,然后输入到姿态预测头中,并独立解码为最终的姿态集和类标签。因此,每个query都可以搜索一个object/instance,并预测其姿态和类。我们将object queries的数量N设置为25,因为这大约比COCO数据集中的一张图像中出现的最大人类数量高两倍。借助编码器和解码器中的self-attention,网络能够利用它们之间的成对关系(pairwise relationship)对所有对象进行全局推理,同时利用整个图像作为上下文信息。这个Transformer解码器(以及DETR(17)中的解码器)与原始公式的不同之处在于每一层的N个对象的并行解码,与Vaswani等人(Attention is all you need, 18)使用的自回归模型形成对比。
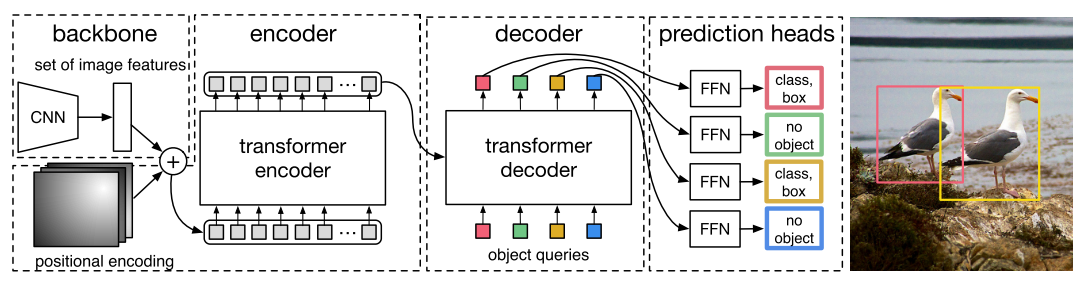
图为DETR的整体架构。POET的架构与DETR基本类似。
3.4. Pose prediction head
最终的姿态估计由一个带有ReLU激活的3层感知器和一个线性投影层(FFN head)进行。该头部输出中心坐标、相对于中心的所有身体部位的位移以及单个向量中每个身体部位的可见性得分(图2b),线性层使用softmax函数输出类标签。因此,我们将中心和偏移量归一化到图像大小。
3.5. Traning loss
为了同时预测所有人体姿态,网络通过最优匹配后的损失进行训练,在找到预测值与真实值的最优匹配后对个体进行求和。因此,我们的损失必须对**类(class)、关键点坐标(keypoint coordinates)及其可见性(visibilities)**进行相应的评分,生成匹配,然后优化多实例特定姿势的损失。
对于每一个实例i,在ground truth中,我们计算所有可见关键点的中心(例如,COCO(29)包含没有注释的人可见性设置为0), 然后计算[xc,yc,∆x1,∆y1,v1,∆x2,∆y2,v2…、∆xn,∆yn,vn],其中每个body part的中心(xc、yc), 相对偏移量(∆xi,∆yi)的以及可见性vi。
为了使损失函数更清晰,我们将这个向量分割成yi= (ci, Ci,Zi,Vi), 由目标类标签(人/非人)ci, 中心坐标Ci = (xc、yc), 相对姿势:Zi=[∆x1,∆y1,∆x2, ∆y2,…, ∆xn,∆yn] (相对于中心Ci的关节点位移) 和二元可见性向量Vi = [v1,v1,v2,v2,…,vn,vn]对图像中每个关节进行编码,无论其可见与否。
对于实例i的网络的预测,定义为** y ^ i = ( p ^ ( c i ) , C ^ i , Z ^ i , V ^ i \hat{y}i =(\hat{p}(ci),\hat{C}_i,\hat{Z}_i,\hat{V}_i y^i=(p^(ci),C^i,Z^i,V^i),其中 p ^ ( c i ) \hat{p}(ci) p^(ci)是类ci的预测概率, C ^ i \hat{C}i C^i是预测中心, Z ^ i \hat{Z}_i Z^i是预测的姿态,而 V ^ i \hat{V}_i V^i是预测可见性**。网络并不预测人体中心的可见性。
接下来,我们用y表示姿态的ground-truth集合, y ^ = { y ^ i } i = 1 N \hat{y}=\{\hat{y}i\}^N_{i=1} y^={y^i}i=1N表示N个预测集。这里,y是图像中填充了非对象的一组集合。我们将ground truth yi与具有指标σ(i)的预测之间的**成对匹配损失(pair-wise matching cost)**定义为:

在这里,Lpose特定姿势损失,如公式3所示,包括中心、身体各部位及其可见性的损失。
然后根据匈牙利算法(Hungarian loss)发现最优分配是匹配损失最小的二部图匹配。
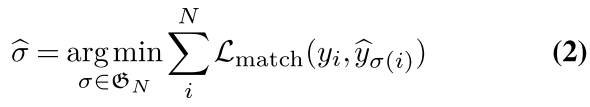
一旦得到最优匹配,我们就可以计算所有匹配对的匈牙利损失。
和匹配损失类似,Lpose包含一个计算姿态的损失, 是下列损失的线性组合,包括一个L1损失计算相对关键点坐标之间的差异, 一个L2损失计算中心坐标损失,一个L2损失计算可见性损失, 超参数为λL1, λL2和λctr:

因此,◦表示逐点乘法。这三种损失在batch内按照人员数量来标准化。
最终的损失为匈牙利损失,其是类别预测的对数似然函数的负值和上述定义的关键点特定损失的线性组合,对于最优分配 σ ^ \hat{σ} σ^的所有对来说,损失如下:
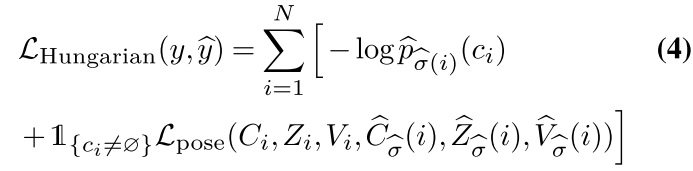
大多数COCO图像只包含少量注释的人。为了解释这种类不平衡,我们对所有non-objects对数概率项的权重降低了10倍。
4. 实验结果
数据集 使用COCO数据集。
实现细节 超参数设置 λ L 1 = 4 , λ L 2 = 0.2 , λ c t r = 0.5 \lambda_{L1}=4, \lambda_{L2}=0.2, \lambda_{ctr}=0.5 λL1=4,λL2=0.2,λctr=0.5。Transformer的初始学习速率设置为10−4,CNN Backbone为10−5,权重衰减到10−4,使用AdamW,dropout=0.1,并使用Xavier初始化(47)对其进行初始化。对于编码器,我们选择了不同步长s的ResNet50,模型分别称为POET-R50和POET-DC5-R50(当使用扩张卷积的C5级(将步幅从32减少到16)。
我们进行了两组不同的实验:
(1)训练POET,由ImageNet权重初始化,以与当前最先进的模型进行比较;
(2)训练多个模型包括基线模型,由MMPose的COCO关键点挑战预训练权重来初始化。
为了与最先进的模型进行比较,我们对POET-R50以batch size=6 在两个NVIDIA V100 gpu上进行300个epoch的训练(因此总batch size为12),学习速率在200个epoch之后下降10倍,在250个epoch之后再次下降10倍。在这种设置中,一个epoch大约需要一个小时。图4和图6可以看到COCO-val上mAP的损失曲线和演化。

图4. POET-R50在训练时期不同损失部分的变化(公式4)。实线对应于训练损失,虚线对应于验证损失(在COCO数据集上)。
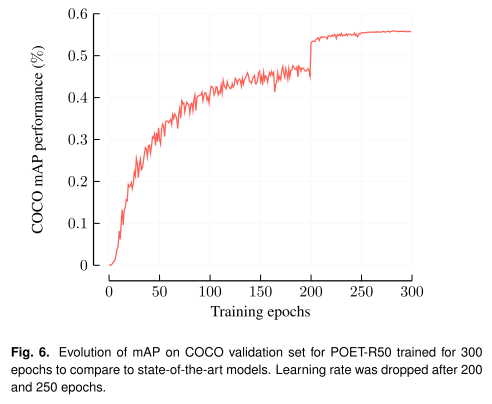
图6。在经过300个epochs训练的POET-R50的COCO验证集上的mAP演化, 与最先进的模型进行比较。学习速率在200和250个epochs后下降。
为了与基线模型进行比较,我们使用MMPose中associative embedding(12,15)实现。为了考虑高内存占用和长训练时间,我们在训练期间限制最大图像大小为512,并训练POET模型(POET- R50和POET-DC5- R50),总batch size为64 (DC5模型为50),训练250个周期,以便与基线模型进行比较。
基线模型在MMPose中使用AE + ResNet模型的默认学习率进行100个周期的训练,并使用类似的增强方法(没有coarse dropout,但使用仿射变换增强)。尽管常用的训练计划一般用300个epoch,但我们只训练了100个epoch的基线模型,因为我们实际上使用那些在COCO上使用stride 4训练并通过删除上采样层来减少stride的模型对AE + ResNet模型进行初始化。
定量评价
POET-R50的性能与其他Bottom-up的方法相比,在大尺度人体上( A P L AP_L APL)具有竞争力,但在 A P M , A P S AP_M, AP_S APM,APS上比其它方法效果差。我们认为这是由于在所有强方法(如≥4,见表1)中encoder的较大stride,这导致Transformer输入处的空间分辨率较低。Transformer在输入尺寸上按 O ( ( H ⋅ W / S 2 ) 2 ) O((H·W/S^2)^2) O((H⋅W/S2)2)进行缩放,因此增加输入图像的尺寸代价很高。总的AP比HigherHRNet还差了不少呀,哦,和其它的相比也比不过。。。
为了展示我们方法的强大潜力,与之前的方法相比,我们接下来将POET与带有ResNet Backbone(和变化的步长)的基线模型进行比较。我们选择Associative Embedding (AE)(12,45)作为模型进行比较,因为该方法被证明是一种强大的自底向上方法,在目前是最先进的方法高分辨率主干HigherHRNet(15)中应用。我们创建基线模型,使用相同的预训练ResNet Backbone,输入图像大小和类似的数据增强。

我们将AE的ResNet Backbone从stride-4调整到stride-32,以确保两种方法有相同的feature map尺寸。(为什么不同的stride的参数量是一样的呀?(对于POET-R50, POET-DC5-R50) 因为输入Transformer之前有一个projection会将H/s x W/s -> 统一的维度?)
表2显示了基线和POET模型在COCO-val上的AP和AR值。POET优于基线方法(相同stride时),(对于stride-16)甚至优于基线模型(stride-4),这提供了证据,Transformer head适合在图像中学习多个姿势,甚至从低分辨率的特征图(图1)。
未来的工作应该集中在寻找超参数,以更小的步幅训练POET,这可能会极大地提高性能。
分析
Transformer attentions。为了更好地理解编码器和解码器在Transformer体系结构中的作用,我们在一张样本图像上描绘了注意图(图5)。我们发现Transformer的编码器关注每个个体,而解码器特别将注意力放在每个个体看似最可区分的部分,即人脸。

图5. 编码器self-attention参考点如红色标注所示。编码器注意每个人。b)预测个体的解码器attention scores。解码器关注人体最可分辨的部分—脸部区域。图像来自COCO验证集。
可学习的人体中心(Learned Centers)。有趣的是, POET学习的人体中心在头的左侧(图7)。我们假设头部是人体最容易区分的部分,因此将中心放置在头的旁边作为参考点以帮助预测身体的其他部位。事实上,当通过在训练损失中增加中心损失的权重(方程3),来强制模型学习的中心更接近人类质心时,POET很容易学会预测质心,但不能正确地学习关键点。

图7。左图:在一个示例图像中,每个身体部位的预测中心(红色)和相对偏移量作为多个个体的蓝色向量。右:预测中心相对于ground truth中心的相对偏移量的散点图和平面直方图(用Bounding box对角线归一化)。大多数数据点位于IInd象限,这表明POET-R50确实学到了偏向于左上方的偏置。
可见性(Visibility)。损失公式还使模型了解每个关键点的可见性和位置。然而,用于COCO关键点检测挑战的度量没有考虑预测的可见性。我们发现POET准确地预测了每个被预测的身体部位的可见性(图8)。

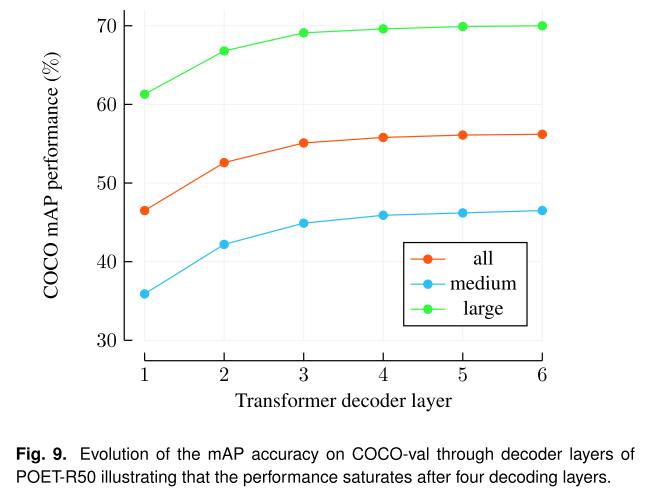
Decoder的分析。我们通过查看Decoder每个阶段的预测来分析Transformer解码器及其层的作用。我们发现,在3-5个解码器层之后,平均性能趋于稳定(图9)。
5. 结论
提出了一种新的基于卷积编码器、Transformer和二部图匹配损失的姿态估计方法POET,用于进行直接集合预测。我们的方法在困难的COCO关键点挑战上取得了强大的结果,是第一个端到端可训练的多实例姿态识别方法。POET的灵感来自于最近的DETR,其将Transformer应用于目标识别和全景分割领域。
目前,POET还没有达到最先进的性能,但我们希望它能激发未来的研究来解决这些挑战。类似地,与POET相比(见表1),DETR在小物体上的表现更差,只能达到最先进性能的80% 。POET和DETR的一个主要限制是收敛速度慢,并且需要大量的内存,这使得高分辨率Backbone的实验成本很高,而这对于精确的姿态估计是很重要的。但我们的方法很简单,可以应用于任何经过端到端训练的Backbone进行多实例姿态估计。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









