







SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。
# s as SnowNLP(text)
1) s.words 词语
2) s.sentences 句子/分句
3) s.sentiments 情感偏向,0-1之间的浮点数,越靠近1越积极(正面)
4) s.pinyin 转为拼音
5) s.han 转为简体
6) s.keywords(n) 提取关键字,n默认为5
7) s.summary(n) 提取摘要,n默认为5
8) s.tf 计算term frequency词频
9) s.idf 计算inverse document frequency逆向文件频率
10) s.sim(doc,index) 计算相似度1、分词

2、词性标注

3、断句

4、情绪判断
返回值为正面情绪的概率,
越接近1表示正面情绪
越接近0表示负面情绪

5、拼音

6、繁体转简体

7、关键词抽取
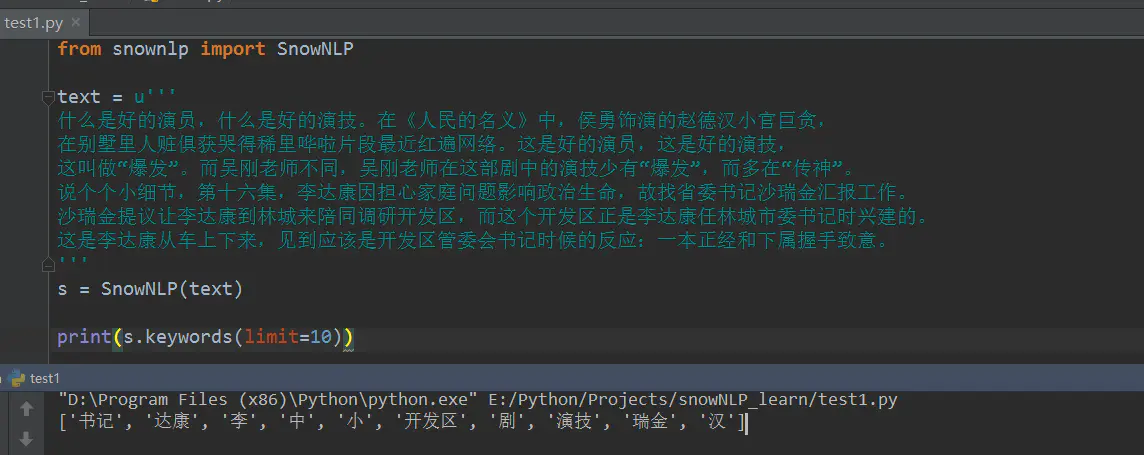
8、概括总结文意

9、信息量衡量
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
TF词频越大越重要,但是文中会的“的”,“你”等无意义词频很大,却信息量几乎为0,这种情况导致单纯看词频评价词语重要性是不准确的。因此加入了idf
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t越重要
TF-IDF综合起来,才能准确的综合的评价一词对文本的重要性。

10、文本相似性
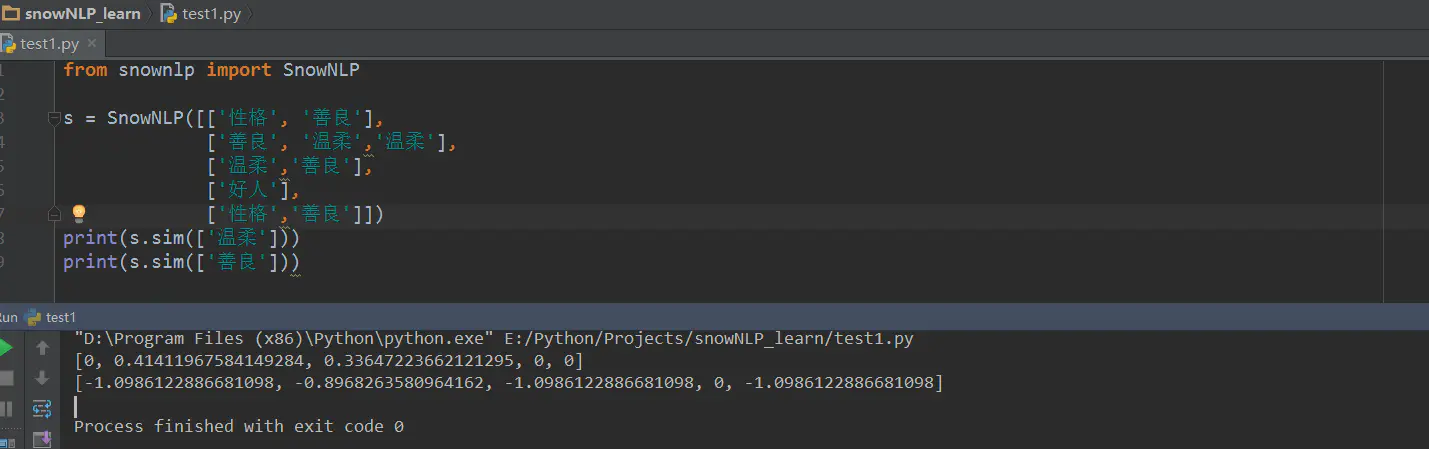
参考地址:https://www.jianshu.com/p/4692d1b5364d















 6564
6564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









