







最近笔者在研究tomcat底层架构,肯定要扒一扒tomcat源码,笔者希望知道工作量有多大,也就是统计一下tomcat源码中文件有多少。笔者首先是个比较懒得人(不懒也不会干IT),所以不可能手动的去统计,也不会自己写代码去统计,然后在网上找了一个java版本的代码。
java代码如下:
package statistic;
import java.io.File;
public class Test {
static int count=0;
public static void main(String[] args) {
getFile("D:/eclipse/work/apache-tomcat-6.0.35-src");
System.out.println("共有"+count+"个文件");
}
public static void getFile(String filepath) {
//com.bizwink.cms.util.Convert con = new com.bizwink.cms.util.Convert();
File file = new File(filepath);
File[] listfile = file.listFiles();
for (int i = 0; i < listfile.length; i++) {
//System.out.println("****** = "+listfile[i].getPath().toString());
if (!listfile[i].isDirectory()) {
//com.bizwink.cms.util.Convert con = new com.bizwink.cms.util.Convert();
String temp=listfile[i].toString().substring(7,listfile[i].toString().length()) ;
//System.out.println("temp=="+temp);
//con.convertFile(listfile[i].toString(), "D:\\newtest"+temp, 0, 3);
count++;
//System.out.println("文件"+count+"---path=" + listfile[i]);
} else {
getFile(listfile[i].toString());
}
}
}
}
运行结果如下:
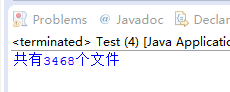
总体来讲,此代码中规中矩,统计倒是很准确,但是tomcat源码中有各类的文件,笔者希望统计信息更详细一点,加上笔者最近在学习python,在加上突然想到该案例是一个非常好的递归案例,然后笔者一时技痒,自己写了几行代码:
python代码如下:
#_*_ coding:utf-8 _*_
'''
Created on 2018年9月15日
@author: admin
'''
import os.path
rootFolder = 'D:/eclipse/work/apache-tomcat-6.0.35-src'
#后缀名字典表
result = {'folder':0}
def statistic(folder):
for temp in os.listdir(folder):
filepath = os.path.join(folder,temp)
#判断是否文件夹,如果是文件夹,则继续递归遍历
if (os.path.isdir( filepath )):
result['folder'] += 1
statistic(filepath)
else:
(name, extension)= os.path.splitext(temp)
#判断后缀名是否在后缀名字典表中
#如果有,直接将该后缀名文件数加1
if result.has_key(extension):
result[extension] += 1
#如果没有,则添加新的字典项目,该后缀名文件数置位1
else:
result[extension] = 1
if __name__ == '__main__':
statistic( rootFolder )
sum = 0
for name in result.keys():
if( name == '' ):
print('该文件夹下共有类型为【无后缀名】的文件%s个'%(result[name]))
else:
print('该文件夹下共有类型为【%s】的文件%s个'%(name, result[name]))
sum += result[name]
print("共有目录及文件%s个"%sum)
if result.has_key(extension):
python3
替换成 if extension in result:
运行结果如下:
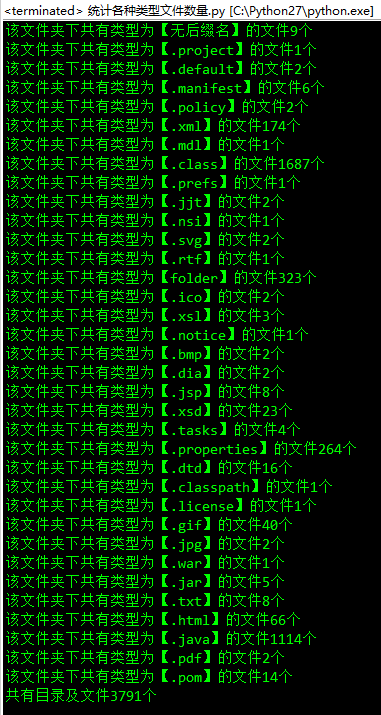
注意:上面代码第21行代码是一个坑,因为开始笔者写的是os.path.isdir( temp ),会一直报错,因为isdir()函数里面传入的参数是一个绝对路径,不然一直会返回false。
遍历D盘下边所有文件,除了有权限问题的目录不能访问之外,其他的都能遍历:
def traversal_dirs(path):
# 递归遍历目录 listdir
for dir in os.listdir(path):
dir = os.path.join(path, dir)
if dir.find('Volume') > -1 or dir.find('RECYCLE') > -1:
continue
if os.path.isdir(dir):
traversal_dirs(dir)
else:
print(dir)
当文件过多时,一个线程执行改程序,耗时比较长,考虑使用多线程执行该程序。
程序运行过慢,考虑多线程遍历
# -*- coding:utf-8 -*-
# exe直接丢入父级目录下
import os
import xlwt
SHEET_MAX_RECORD = 50000
# 定义个获取目录的函数。没用到
def get_dir():
return 'D:/'
def getAllFile(dir, dict):
# 从配置获取目录名,这里并没用到。因为程序就在目标目录下。可以重新赋值为.
for parentDir, dirs, files in os.walk(dir):
for file in files:
dict.get('dirKey').append(dir)
dict.get('fileKey').append(file)
for dir2 in dirs:
getAllFile(dir + '\\' + dir2, dict)
if __name__ == '__main__':
# 创建 xls 文件对象
wb = xlwt.Workbook()
# 新增一个表单
sh = wb.add_sheet('sheet0')
row = 0
dict = {'dirKey': [], 'fileKey': []}
getAllFile(get_dir(), dict)
for i in range(len(dict.get('dirKey'))):
if ((i + 1) % SHEET_MAX_RECORD == 0):
sh = wb.add_sheet('sheet' + str(int((i + 1) / SHEET_MAX_RECORD)))
row = 0
sh.write(i % SHEET_MAX_RECORD, 0, dict.get('dirKey')[i])
sh.write(i % SHEET_MAX_RECORD, 1, dict.get('fileKey')[i])
wb.save("文件信息结果.xls")
print('hehe~~')
import concurrent.futures
import os
# 指定要遍历的文件夹路径
folder_path = 'D:/华为培训'
# 存储文件列表的空列表
file_list = []
# 遍历文件的函数
def process_folder(root, files):
for file_name in files:
# 获取文件的完整路径
file_path = os.path.join(root, file_name)
# 将文件路径添加到文件列表
file_list.append(file_path)
# 创建线程池
with concurrent.futures.ThreadPoolExecutor() as executor:
# 遍历文件夹及其子文件夹,并在多个线程中执行
for root, dirs, files in os.walk(folder_path):
executor.submit(process_folder, root, files)
# 遍历文件夹及其子文件夹
for root, dirs, files in os.walk(folder_path):
for file_name in files:
# 获取文件的完整路径
file_path = os.path.join(root, file_name)
# 将文件路径添加到文件列表
file_list.append(file_path)
# 打印文件列表
# for file_path in file_list:
# print(file_path)
print(len(file_list))
多线程
import os
import threading
import time
def get_target_dir():
return 'D:\\华为培训'
def traverse_dir(parent_path, all_file_list):
for name in os.listdir(parent_path):
temp_path = os.path.join(parent_path, name)
if os.path.isdir(temp_path):
traverse_dir(temp_path, all_file_list)
else:
all_file_list.append(temp_path)
def multi_thread_traverse_dir():
all_file = []
all_dir = []
path = get_target_dir()
for file_name in os.listdir(path):
if str(file_name).find("Volumn") >= 0 or str(file_name).find("Volume") >= 0 or file_name.find('RECYCLE') >= 0:
continue
file_path = os.path.join(path, file_name)
if os.path.isdir(file_path):
all_dir.append(file_path)
else:
all_file.append(file_path)
num_threads = len(all_dir)
threads = []
temp_big_files = []
for i in range(num_threads):
temp_small_file = []
temp_big_files.append(temp_small_file)
thread = threading.Thread(target=traverse_dir, args=(all_dir[i], temp_small_file))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
for temp_big_file in temp_big_files:
all_file.extend(temp_big_file)
print(len(all_file))
fp = open(r'tb2.txt', 'a+', encoding='utf-8') # 写入文件
for i in range(0, len(all_file)):
print(all_file[i], file=fp)
if __name__ == '__main__':
# 获取开始时间
start_time = time.time()
# 运行需要统计时间的代码
multi_thread_traverse_dir()
# 获取结束时间
end_time = time.time()
# 计算耗时
elapsed_time = end_time - start_time
print("代码运行耗时:%s" % elapsed_time)
多线程执行结果
C:\ProgramData\anaconda3\python.exe C:\code_test\multithread\multiThread7.py
105016
代码运行耗时:4.863859415054321
Process finished with exit code 0
单线程
# -*- coding:utf-8 -*-
# exe直接丢入父级目录下
import os
import time
SHEET_MAX_RECORD = 50000
# 定义个获取目录的函数。没用到
def get_dir():
return 'D:\\华为培训'
def single_thread_traverse_dir():
all_file = []
getAllFile(get_dir(), all_file)
fp = open(r'tb.txt', 'a+', encoding='utf-8') # 写入文件
for i in range(0, len(all_file)):
print(all_file[i], file=fp)
print(len(all_file))
def getAllFile(dir, all_file):
# 从配置获取目录名,这里并没用到。因为程序就在目标目录下。可以重新赋值为.
for parentDir, dirs, files in os.walk(dir):
for file in files:
all_file.append(os.path.join(parentDir, file))
if __name__ == '__main__':
# 获取开始时间
start_time = time.time()
# 运行需要统计时间的代码
single_thread_traverse_dir()
# 获取结束时间
end_time = time.time()
# 计算耗时
elapsed_time = end_time - start_time
print("代码运行耗时:%s" % elapsed_time)
单线程执行结果
C:\ProgramData\anaconda3\python.exe C:\code_test\multithread\singleThread6.py
105019
代码运行耗时:1.7679948806762695
Process finished with exit code 0
完结:遍历D盘,并将结果写入到excel文件,每个文件配一个链接,可以将文件直接点开
# -*- coding:utf-8 -*-
# exe直接丢入父级目录下
import os
import xlwt
import threading
import time
SHEET_MAX_RECORD = 50000
SHEET_NAME_INDEX = 2
# 定义个获取目录的函数。没用到
def get_target_dir():
return 'D:\\'
def traverse_dir(root_dir, wb):
all_file_list = []
sheet_name = root_dir.split('\\')[-1]
# 从配置获取目录名,这里并没用到。因为程序就在目标目录下。可以重新赋值为.
for parentDir, dirs, files in os.walk(root_dir):
for file in files:
all_file_list.append(os.path.join(parentDir, file))
sheet = wb.add_sheet(sheet_name)
for j in range(len(all_file_list)):
file_path = all_file_list[j]
if j > 1 and j % SHEET_MAX_RECORD == 0:
sheet = wb.add_sheet('{}_{}'.format(sheet_name, str(int(j / SHEET_MAX_RECORD))))
sheet.write(j % SHEET_MAX_RECORD, 0, all_file_list[j])
try:
sheet.write(j % SHEET_MAX_RECORD, 1,
xlwt.Formula('HYPERLINK("%s";"%s")' % (file_path, file_path.split('\\')[-1])))
except Exception:
print(file_path)
#xlwt.Formula 执行之后的字符串长度有超过255的风险:raise Exception('String longer than 255 characters')
def multi_thread_traverse_dir():
all_dir = []
all_file = []
path = get_target_dir()
# 创建 xls 文件对象
wb = xlwt.Workbook()
sheet = wb.add_sheet('first')
for file_name in os.listdir(path):
if str(file_name).find("Volumn") >= 0 or str(file_name).find("Volume") >= 0 or file_name.find('RECYCLE') >= 0:
continue
file_path = os.path.join(path, file_name)
if os.path.isdir(file_path):
all_dir.append(file_path)
else:
all_file.append(file_path)
for j in range(len(all_file)):
sheet.write(j, 0, all_file[j])
sheet.write(j, 1, xlwt.Formula('HYPERLINK("%s";"%s")' % (all_file[j], all_file[j].split('\\')[-1])))
num_threads = len(all_dir) # 总目录下有多少个子目录就开启多少个线程
threads = []
for i in range(num_threads):
thread = threading.Thread(target=traverse_dir, args=(all_dir[i], wb))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
print('**' * 50)
print('**' * 50)
wb.save("文件信息结果.xls")
if __name__ == '__main__':
# 获取开始时间
start_time = time.time()
# 运行需要统计时间的代码
multi_thread_traverse_dir()
# 获取结束时间
end_time = time.time()
# 计算耗时
elapsed_time = end_time - start_time
print("代码运行耗时:%s" % elapsed_time)















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











