









 本文探讨RNN中梯度消失现象,通过数学推导解释其原因,并指出ReLU对缓解问题的影响。重点介绍GRU与LSTM的区别,强调LSTM通过记忆单元C避免梯度消失,并提供了PyTorch实现LSTM的实例。
本文探讨RNN中梯度消失现象,通过数学推导解释其原因,并指出ReLU对缓解问题的影响。重点介绍GRU与LSTM的区别,强调LSTM通过记忆单元C避免梯度消失,并提供了PyTorch实现LSTM的实例。
1、RNN发生梯度消失的原因是什么?
此处本文以下图为例,RNN的权重参数就是下图的Wo、Ws、Wx,RNN中的权重参数在每个单元是共享的,x1、x2、x3为输入特征,s1、s2、s3为隐状态,o1、o2、o3为输出特征
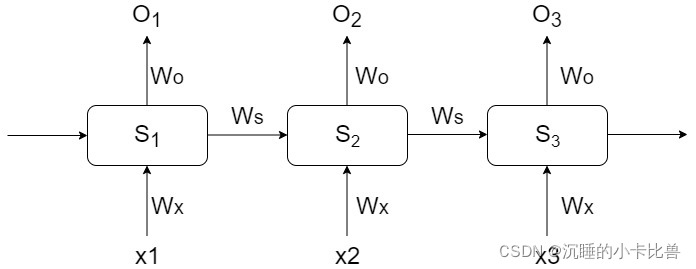
假设 loss function为 L3 = loss(y3, o3),S到O的映射一般视任务而定,这里设定为线性变换
S1 = tanh(Wx*x1 + Ws*S0 + b1), O1 = Wo*S1 + b2
S2 = tanh(Wx*x2 + Ws*S1 + b1), O2 = Wo*S2 + b2
S3 = tanh(Wx*x3 + Ws*S2 + b1), O3 = Wo*S3 + b2
分别计算RNN权重参数Ws、Wx的梯度(仅计算o3传递的部分):
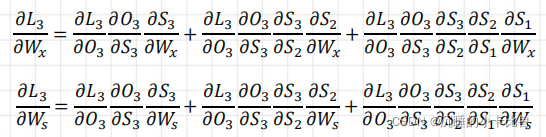
可以发现越远位置的梯度有连乘项,写成一般形式

可以看到tanh在(-1, 1)之间,连乘之后这项会越来越小
注意:RNN中梯度问题是长程依赖导致的远距离的梯度更新问题,和DNN中的梯度消失有所不同。RNN中梯度本身不会消失,但是远距离时间步产生的梯度会消失。
当然也有可能会产生梯度爆炸的情况,相对而言梯度爆炸更容易去处理。
遇到梯度爆炸可以尝试的解决方法:
(1)梯度裁剪,梯度设置最大阈值
(2)Truncated BPTT分段传播
(3)学习率设置
2、RNN中使用ReLU可以解决梯度消失问题吗?
效果可能会好一些,但本质上还是存在长程依赖的问题,因为relu小于0的部分梯度就消失了。
3、GRU和LSTM的差别
LSTM主要在RNN的基础上维护了记忆单元C,前一层的隐状态输出和这一层的token特征都需要和记忆C做交互,从而得到更新后的C和隐状态;
GRU是对LSTM的简化,将需要记忆和遗忘的步骤合并在隐状态的更新过程中,而且没有独立的输出门。
GRU参数量是LSTM的
LSTM的结构
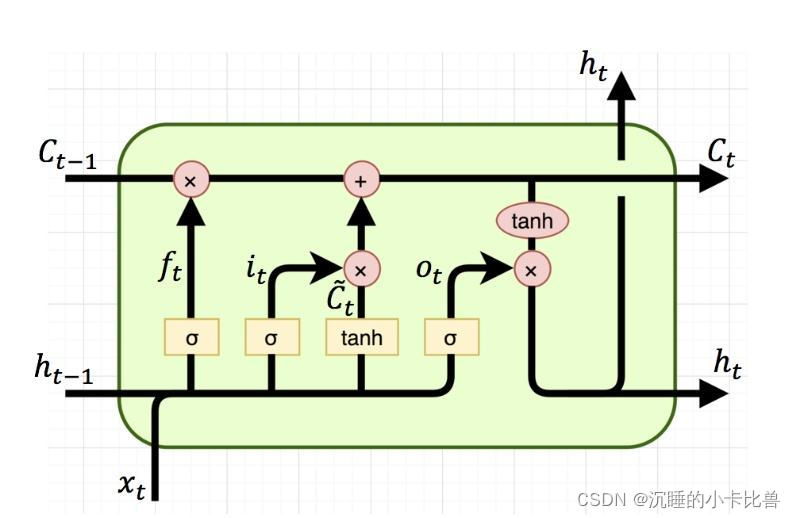
对应pytorch中LSTM文档的相关公式:
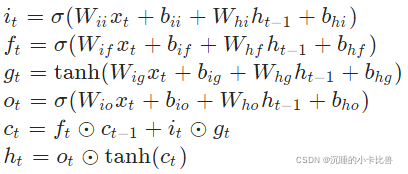
其中含有Wi和Wh的四个矩阵参数concat在了一起
GRU的结构
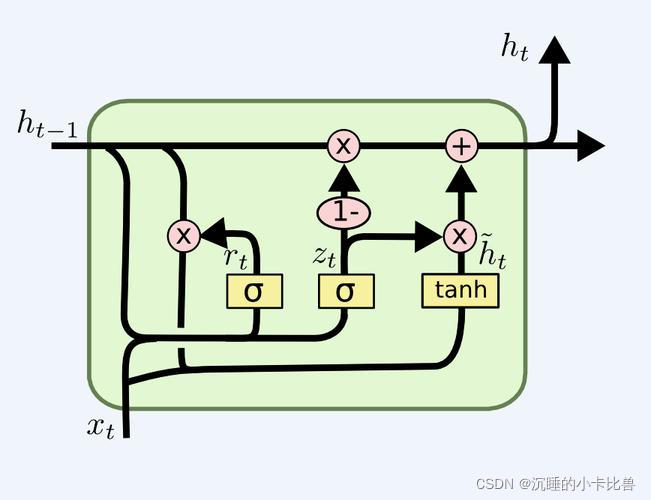
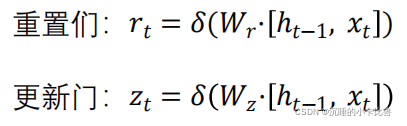
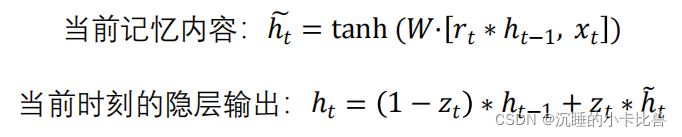
4、LSTM为什么能够解决梯度消失/爆炸的问题?
在网上搜这个问题看到很多的文章大致会跟你说,这是因为对记忆单元C求Ct对Ct-1的导数是几项相加得到的,导致梯度不会消失。为什么要看这项呢?
在RNN的梯度更新中,长程依赖导致梯度中的链式累乘项为隐状态St与St-1求导的连乘;而LSTM中累成项为Ct与Ct-1求导的连乘
可能是疫情离职在家太空了,所以把这些公式和原理又推敲了一下,发现有个B站的up主已经做过这个事情而且录视频了。这部分要推导出来确实有点篇幅。因此直接给出能推导清楚的链接,如下(其实踏踏实实一步一个脚印推导公式都能求得,如果我年轻的时候也有这样的时间和心情或许也会这么做):
【重温经典】大白话讲解LSTM长短期记忆网络 如何缓解梯度消失,手把手公式推导反向传播_哔哩哔哩_bilibili
5、pytorch实现LSTM前向传播过程
代码基于pytorch 1.10
首先,看一下pytorch中的LSTM
https://pytorch.org/docs/1.10/generated/torch.nn.LSTM.html?highlight=lstm#torch.nn.LSTM
模型输入为input向量,可手动设置初始的隐状态h0和记忆状态c0
import torch
import torch.nn as nn
bs, T, i_size, h_size = 2, 3, 4, 5 #batch_size, seq_length,input_size, hidden_size
input = torch.randn(bs, T, i_size)
c0 = torch.randn(bs, h_size)
h0 = torch.randn(bs, h_size)
#调用官方API
lstm_layer = nn.LSTM(i_size, h_size, batch_first = True)
output, (h_final, c_final) = lstm_layer(input, (h0.unsqueeze(0), c0.unsqueeze(0)))
for p, n in lstm_layer.named_parameters():
print(p, n.shape)可以看到模型的参数如下:

这里weight_ih_l0,注意这里不是10而是l0(L的小写)因为这里就设置了一层LSTM。
这里h_size设置成为5,而权重都是20维的。这是因为把Wi和Wh的四个向量都cancat在一起了。具体顺序和上文公式顺序一样。
def lstm_forward(input, initial_states, w_ih, w_hh, b_ih, b_hh):
h0, c0 = initial_states
bs, T, i_size = input.shape
h_size = w_ih.shape[0] // 4
prev_h = h0 # [bs, h_size]
prev_c = c0
batch_w_ih = w_ih.unsqueeze(0).tile(bs, 1, 1)
batch_w_hh = w_hh.unsqueeze(0).tile(bs, 1, 1)
output = torch.zeros(bs, T, h_size)
for t in range(T):
x = input[:, t, :].unsqueeze(-1)
w_times_x = torch.bmm(batch_w_ih, x).squeeze(-1)
w_times_h_prev = torch.bmm(batch_w_hh, prev_h.unsqueeze(2)).squeeze(-1)
i_t = torch.sigmoid(w_times_x[:, :h_size] + w_times_h_prev[:, :h_size] \
+ b_ih[: h_size] + b_hh[: h_size])
f_t = torch.sigmoid(w_times_x[:, h_size: 2 * h_size] + w_times_h_prev[:, h_size: 2 * h_size] \
+ b_ih[h_size: 2 * h_size] + b_hh[h_size: 2 * h_size])
g_t = torch.tanh(w_times_x[:, 2 * h_size: 3 * h_size] + w_times_h_prev[:, 2 * h_size: 3 * h_size] \
+ b_ih[2 * h_size: 3 * h_size] + b_hh[2 * h_size: 3 * h_size])
o_t = torch.sigmoid(w_times_x[:, 3 * h_size: ] + w_times_h_prev[:, 3 * h_size: ] \
+ b_ih[3 * h_size: ] + b_hh[3 * h_size: ])
prev_c = f_t * prev_c + i_t * g_t
prev_h = o_t * torch.tanh(prev_c)
output[:, t, :] = prev_h
return output, (prev_h, prev_c)
custom_out, (custom_h, custom_c) = lstm_forward(input, (h0, c0), lstm_layer.weight_ih_l0, lstm_layer.weight_hh_l0, lstm_layer.bias_ih_l0, lstm_layer.bias_hh_l0)
print(torch.allclose(custom_out, output))
print(torch.allclose(custom_h, h_final))
print(torch.allclose(custom_c, c_final))参考:https://www.bilibili.com/video/BV1zq4y1m7aH?spm_id_from=333.999.0.0



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









