






机器学习中损失函数有哪些,有什么作用
分类
从功能上分,可以分为以下三类:
-
Probabilistic losses,主要用于分类
-
Regression losses, 用于回归问题
-
Hinge losses, 又称"maximum-margin"分类,主要用作svm,最大化分割超平面的距离
Probabilistic losses
对于分类概率问题常用交叉熵来作为损失函数.
BinaryCrossentropy(BCE)
BinaryCrossentropy用于0,1类型的交叉.
函数原型
tf.keras.losses.BinaryCrossentropy(
from_logits=False,
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='binary_crossentropy'
)
参数from_logits默认为False,表示输出的logits需要经过激活函数的处理。比如,如果logits经过sigmoid函数处理后,logits的值域为(-1, 1);经过softmax激活函数处理,logits的取值范围为(0, 1)。但是如果没有经过激活函数处理,输出logits的值域为负无穷到正无穷之间。
计算公式:
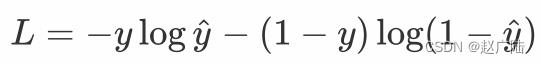
交叉熵描述了两个概率分布之间的距离,当交叉熵越小说明二者之间越接近。
公式设计的目的:
对于positive样本 y=1,loss= - logy^ , 当y^ 越大时,loss越小。最理想情况下y^=1,loss=0
对于negative样本 y=0,loss= - log(1-y^), 当y^ 越小时,loss越小。最理想情况下y^=0,loss=0
CategoricalCrossentropy(CCE)
CategoricalCrossentropy和SparseCategorialCrossentropy都用于多分类器,而CategoricalCrossentropy通常用于One-hot分类的问题中
函数用法:
tf.keras.losses.CategoricalCrossentropy(
from_logits=False, label_smoothing=0.0, axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='categorical_crossentropy'
)
计算公式:
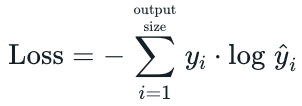
yi,要么是0,要么是1。而当yi等于0时,结果就是0,当且仅当yi等于1时,才会有结果。也就是说categorical_crossentropy只专注与一个结果,因而它一般配合softmax做单标签分类
SparseCategorialCrossentropy(SCCE)
SparseCategorialCrossentropy用于数值标签的多分类器
函数用法:
tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=False,
reduction=losses_utils.ReductionV2.AUTO,
name='sparse_categorical_crossentropy'
)
from_logits: 为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定;
reduction:类型为tf.keras.losses.Reduction,对loss进行处理,默认是求平均;
name: op的name
计算公式:

y是样本x属于某一个类别的真实概率,而f(x)是样本属于某一类别的预测概率,m是样本数,Q用来衡量真实值与预测值之间差异性的损失结果。
Poisson
泊松损失,计算 y_true 和 y_pred 之间的泊松损失
函数用法:
tf.keras.losses.Poisson(
reduction=losses_utils.ReductionV2.AUTO, name=‘poisson’
)
计算公式:
KLDivergence
Kullback-Leibler 散度损失,两个概率分布(probability distribution)间差异的非对称性度量
函数用法:
tf.keras.losses.KLDivergence(
reduction=losses_utils.ReductionV2.AUTO,
name='kl_divergence'
)
计算公式:
loss = y_true * log(y_true / y_pred)
Regression losses
MeanSquaredError(MSE)
均方误差(Mean Squared Error,MSE):MSE是回归任务中常用的损失函数,它衡量模型预测值与实际值之间的平均平方误差
函数用法:
tf.keras.losses.MeanSquaredError(
reduction=losses_utils.ReductionV2.AUTO, name='mean_squared_error'
)
计算公式:
MeanAbsolutePercentageError(MAPE)
平均绝对百分比误差预测结果与真实值之间的偏差比例
函数用法:
tf.keras.losses.MeanAbsolutePercentageError(
reduction=losses_utils.ReductionV2.AUTO,
name='mean_absolute_percentage_error'
)
计算公式:
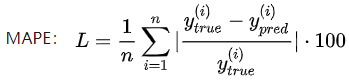
MeanSquaredLogarithmicError(MSLE)
计算y_true和y_pred之间的平均平方对数误差。
函数用法:
tf.keras.losses.MeanSquaredLogarithmicError(
reduction=losses_utils.ReductionV2.AUTO,
name='mean_squared_logarithmic_error'
)
计算公式:
CosineSimilarity (余弦相似度)
计算标签和预测之间的余弦相似度。
函数用法:
tf.keras.losses.CosineSimilarity(
axis=-1, reduction=losses_utils.ReductionV2.AUTO,
name=‘cosine_similarity’
)
计算公式:
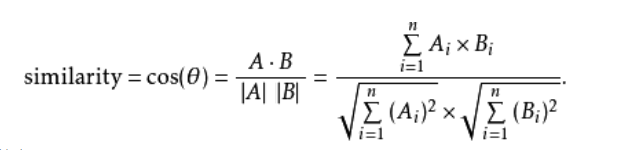
Huber
Huber Loss 是一个用于回归问题的带参损失函数, 优点是能增强平方误差损失函数(MSE, mean square error)对离群点的鲁棒性
函数用法:
tf.keras.losses.Huber(
delta=1.0, reduction=losses_utils.ReductionV2.AUTO, name='huber_loss'
)
计算公式:
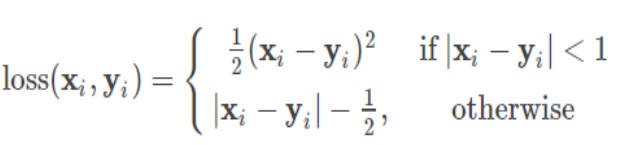
LogCosh
Log-Cosh是应用于回归任务中的另一种损失函数,它比L2损失更平滑。Log-cosh是预测误差的双曲余弦的对数
函数用法:
tf.keras.losses.LogCosh(
reduction=losses_utils.ReductionV2.AUTO, name='log_cosh'
)
计算公式:
HingeLoss
Hinge
hinge loss是一种损失函数,它通常用于"maximum-margin"的分类任务中,如支持向量机
函数用法:
tf.keras.losses.Hinge(
reduction=losses_utils.ReductionV2.AUTO, name='hinge'
)
计算公式:
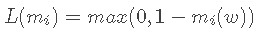
当把损失值推广到整个训练数据集,则应为:
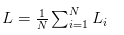
SquaredHinge
Hinge的基础上平方
函数用法:
tf.keras.losses.SquaredHinge(
reduction=losses_utils.ReductionV2.AUTO, name='squared_hinge'
)
计算公式:
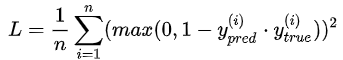
CategoricalHinge
分类铰链损失
函数用法:
tf.keras.losses.CategoricalHinge(
reduction=losses_utils.ReductionV2.AUTO, name='categorical_hinge'
)
总结
目标函数:
mean_squared_error / mse 均方误差,常用的目标函数,公式为((y_pred-y_true)**2).mean()
mean_absolute_error / mae 绝对值均差,公式为(|y_pred-y_true|).mean()
mean_absolute_percentage_error / mape公式为:(|(y_true - y_pred) / clip((|y_true|),epsilon, infinite)|).mean(axis=-1) * 100,和mae的区别就是,累加的是(预测值与实际值的差)除以(剔除不介于epsilon和infinite之间的实际值),然后求均值。
mean_squared_logarithmic_error / msle公式为: (log(clip(y_pred, epsilon, infinite)+1)- log(clip(y_true, epsilon,infinite)+1.))^2.mean(axis=-1),这个就是加入了log对数,剔除不介于epsilon和infinite之间的预测值与实际值之后,然后取对数,作差,平方,累加求均值。
squared_hinge 公式为:(max(1-y_true*y_pred,0))^2.mean(axis=-1),取1减去预测值与实际值乘积的结果与0比相对大的值的平方的累加均值。
hinge 公式为:(max(1-y_true*y_pred,0)).mean(axis=-1),取1减去预测值与实际值乘积的结果与0比相对大的值的的累加均值。
binary_crossentropy: 常说的逻辑回归, 就是常用的交叉熵函数
categorical_crossentropy: 多分类的逻辑, 交叉熵函数的一种变形吧,没看太明白
性能评估函数:
binary_accuracy: 对二分类问题,计算在所有预测值上的平均正确率
categorical_accuracy:对多分类问题,计算再所有预测值上的平均正确率
sparse_categorical_accuracy:与categorical_accuracy相同,在对稀疏的目标值预测时有用
top_k_categorical_accracy: 计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确
sparse_top_k_categorical_accuracy:与top_k_categorical_accracy作用相同,但适用于稀疏情况















 5974
5974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









