







终于,我们可以开始构建第⼀个机器学习模型了。
是这样吗?
在开始之前,我们必须注意⼏件事。请记住,我们将在集成开发环境/⽂本编辑器中⼯作,⽽不是
在 jupyter notebook中。你也可以在 jupyter notebook中⼯作,这完全取决于你。不过,我将只使⽤ jupyter notebook来探索数据、绘制图表和图形。我们将以这样⼀种⽅式构建分类框架,即插即⽤。您⽆需对代码做太多改动就能训练模型,⽽且当您改进模型时,还能使⽤ git 对其进⾏跟踪。
我们⾸先来看看⽂件的结构。对于你正在做的任何项⽬,都要创建⼀个新⽂件夹。在本例中,我
将项⽬命名为 "project"。
项⽬⽂件夹内部应该如下所⽰。
input
train.csv
test.csv
src
create_folds.py
train.py
inference.py
models.py
config.py
model_dispatcher.py
models
model_rf.bin
model_et.bin
notebooks
exploration.ipynb
check_data.ipynb
README.md
LICENSE
让我们来看看这些⽂件夹和⽂件的内容。
input/
:该⽂件夹包含机器学习项⽬的所有输⼊⽂件和数据。如果您正在开发 NLP 项⽬,您可以将embeddings放在这⾥。如果是图像项⽬,所有图像都放在该⽂件夹下的⼦⽂件夹中。
src/
:我们将在这⾥保存与项⽬相关的所有 python 脚本。如果我说的是⼀个 python 脚本,即任
何 *.py ⽂件,它都存储在 src ⽂件夹中。
models/
:该⽂件夹保存所有训练过的模型。
notebook/
:所有 jupyter notebook(即任何 *.ipynb ⽂件)都存储在笔记本 ⽂件夹中。
README.md
:这是⼀个标记符⽂件,您可以在其中描述您的项⽬,并写明如何训练模型或在⽣
产环境中使⽤。
LICENSE
:这是⼀个简单的⽂本⽂件,包含项⽬的许可证,如 MIT、Apache 等。关于许可证的
详细介绍超出了本书的范围。
假设你正在建⽴⼀个模型来对 MNIST 数据集(⼏乎每本机器学习书籍都会⽤到的数据集)进⾏
分类。如果你还记得,我们在交叉检验⼀章中也提到过 MNIST 数据集。所以,我就不解释这个
数据集是什么样⼦了。⽹上有许多不同格式的 MNIST 数据集,但我们将使⽤ CSV 格式的数据
集。
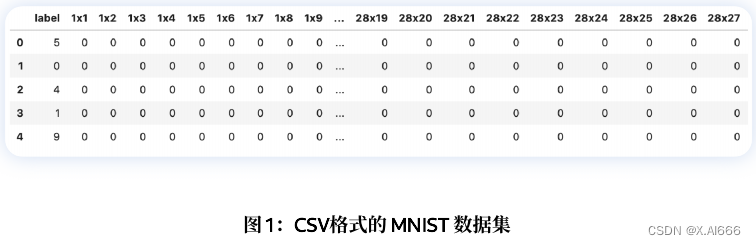
在这种格式的数据集中,CSV 的每⼀⾏都包含图像的标签和 784 个像素值,像素值范围从 0 到
255。数据集包含 60000张这种格式的图像。
我们可以使⽤ pandas 轻松读取这种数据格式。
请注意,尽管图 1 显⽰所有像素值均为零,但事实并⾮如此。
让我们来看看这个数据集中标签列的计数。
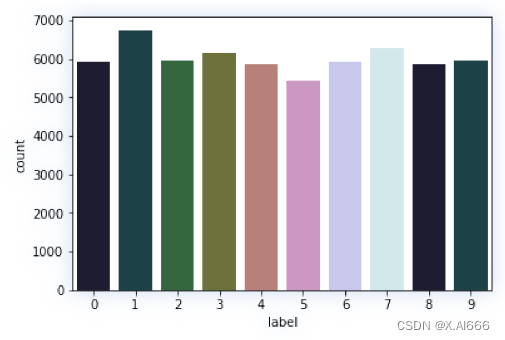
我们不需要对这个数据集进⾏更多的探索。我们已经知道了我们所拥有的数据,没有必要再对不
同的像素值进⾏绘图。从图 2 中可以清楚地看出,标签的分布相当均匀。因此,我们可以使⽤准
确率/F1 作为衡量标准。这就是处理机器学习问题的第⼀
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











