






标题
Mocov: Model Based Fuzzing Through Coverage Guided Technology
Mocov:一个基于覆盖率引导的fuzz模型
1. 摘要
论文观点:盲目的随机的fuzz很难发现隐藏比较深的bug。所以提出了Mocov,一种基于代码覆盖率引导的fuzz技术,该技术借用了插桩和实时反馈来避免盲目性,以此来发现隐藏较深的bug。
2. 概述
Mocov instruments the source code of the target program, including the function of getting and saving the coverage information, then compiles the program using the address-sanitizer compilation option to detect the error while the program is running. The error message will be saved in a file.
mocov在源代码中对获得和保存函数的覆盖率信息进行插桩,然后对这个程序进行编译,通过address-sanitizer
汇编探测程序的错误,这些错误信息将会保存在一个文件中。
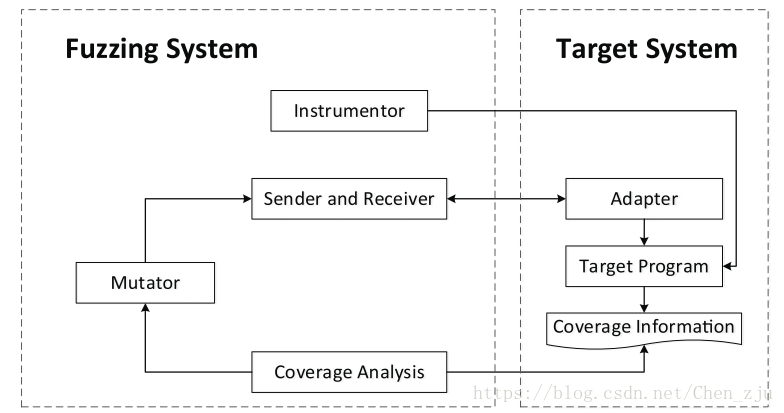
Mocov uses an adapter to send and receive data between fuzzing system and target program. This design allows loose coupling between the target program and Mocov.
mocov使用一个adapter在fuzzing系统和目标程序之间发送和接收数据。这样的设计是的目标程序和mocov能解耦合。
Mocov detects if a new coverage file is generated using communication interface
provided by the target system. If a new coverage file generated, then Mocov analyses
the path coverage information to see if a new basic block occurred, if occurred, the seed
data will be saved as the candidate and be added to a queue where all the candidate seed
data is arranged in terms of weights. Mocov chooses the first candidate seed data in this
queue each iteration.
如果发现一个新的coverage文件,mocov分析路径覆盖信息,以此来判断是否有新的路径被发现。如果有,则种子数据将被保存,并根据权重添加到候选队列。迭代时,mocov将从queue中取出第一个种子。
After choosing the seed file, Mocov analyses the seed data using data model, if it
can be properly parsed, then mutates the seed using the default mutation strategy of
Peach. If it fails, Mocov mutates the seed using the random mutation strategy, including
sequential bit flips with varying lengths and stepovers, sequential addition and subtrac‐
tion of small integers, sequential insertion of known interesting integers.
选中种子之后,mocov通过data模型分析这个种子。如果能进一步处理,这个种子将通过Peach策略进行默认变异。如果不行,mocov通过随机变异策略,包括序列的bit翻转,加减法,插入等。
3. 设计
3.1 插桩
插桩方式和AFL相同,都是通过bitmap实现,插桩代码如下
int seq_byte = position/8;
int seq_in_byte =1<<(position%8);
blocks[seq_byte]=blocks[seq_out_byte]|seq_in_byte;
3.2 覆盖率分析
如果被测试的seed检查到能访问到新的区域,这个seed保存到候选队列进行变异。
seed插入到队列的位置按照seed的权重weight决定,weight的计算方式如下:
weight = num\_cov / (seed\_size * exec\_time * numexec)
num_cov: the number of the executed basic blocks
seed_size: the size of the seed
exec_time: the time that the seed was processed in the program.
num_exec: the number of times current seed was executed
3.3 seed变异
从队列中取出第一个seed进行变异,变异的数量有权重决定,权重越大,产生seed越多。
如果选出来的seed能被pit file处理,则通过peach策略进行随机的变异;如果不能被pit file处理,mocov会将这个seed进行变异。
4 实现和评估
略.
5. 相关工作
这个部分比较有意思,相当于一个综述,写的很全,可以看看拓展思路。因为较长,而且本身就是一两句话描述一个东西,比较精简,就不摘录了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









