







基于java
常用正则
| 说明 | 正则表达式 |
|---|---|
| 汉字(字符) | [\u4e00-\u9fa5] |
| 中文及全角标点符号(字符) | [\u3000-\u301e\ufe10-\ufe19\ufe30-\ufe44\ufe50-\ufe6b\uff01-\uffee] |
| 中国大陆身份证号(15位或18位) | \d{15}(?:\d\d[0-9xX])? |
| IP地址 | (?:(?:2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(?:2[0-4]\d|25[0-5]|[01]?\d\d?) |
| 日期(年-月-日) | (?:\d{4}|\d{2})-(?:(?:1[0-2])|(0?[1-9]))-(?:(?:[12][0-9])|(?:3[01])|(?:0?[1-9])) |
| 时间(小时:分钟, 24小时制) | (?:(?:1|0?)[0-9]|2[0-3]):(?:[0-5][0-9]) |
| 不包含abc的单词 | \b(?:(?!abc)\w)+\b |
元字符收集
基本
| 元字符 | 匹配对象 |
|---|---|
| ^、\A | 匹配一行的开头位置 |
| $、\Z、\z | 匹配一行的结束位置 |
| . | 匹配单个任意字符。java即使不开启点号通配模式,也可以匹配单个Unicode的行终结符 |
| […] | 匹配单个列出的字符 |
| [^…] | 匹配单个未列出的字符 |
| ? | 匹配优先量词,容许匹配一次,但非必须 |
| * | 匹配优先量词,可以匹配任意多次,也可以不匹配 |
| + | 匹配优先量词,至少匹配一次 |
| {min,max} | 匹配优先量词,至少匹配min次,至多匹配max次,注意无逗号后面无空格 |
| | | 多选结构,匹配任意分隔的表达式。从左到右顺序检查表达式的多选分支,取首次完全匹配成功的。 |
| (…) | 限定多选结构的范围,标注量词作用的元素,为反向引用“捕获”文本。java中可以使用 1、 2取得捕获的文本,另使用方法Matcher.group(0)获得完整的匹配,Matcher.group(1)获得第一组括号匹配的文本 |
| (?:…) | 非捕获型括号 |
(?<Name>……) | 命名捕获。java中使用方法Matcher.group(String name)取得捕获的文本 |
| \char | 若char是元字符,或转义序列无特殊含义时,匹配char对应的普通字符 |
| \w | 单词中的字符,等价于[a-zA-Z0-9_] |
| \W | 非单词字符,等价于[^\w] |
| \d | 数字,等价于[0-9] |
| \D | 非数字,等价于[^\d] |
| \s | 空白字符,通常等价于[ \f\n\r\t\v] |
| \S | 非空白字符,等价于[^\s] |
| \b | 单词分界符 |
| \B | 非单词分界符 |
其它
| 元字符 | 匹配对象 |
|---|---|
| \a | 警报,通常对应ASCII的 BEL 字符,八进制编码007 |
| \e | Escape字符,通常对应ASCII的 ESC 字符,八进制编码033 |
| \f | 进纸符,通常对应ASCII的 FF 字符,八进制编码014 |
| \n | 换行符,通常对应ASCII的 LF 字符,八进制编码012 |
| \r | 回车符,通常对应ASCII的 CR 字符,八进制编码015 |
| \t | 水平制表符,对应ASCII的 HT 字符,八进制编码011 |
| \v | 垂直制表符,对应ASCII的 VT 字符,八进制编码013 |
| \num | 八进制,通常要求任何八进制转义都必须以0开头 |
| \xnum、\unum | 十六进制 |
(?=……) | 肯定顺序环视。只匹配位置,不匹配文本。环视的子表达式匹配尝试结束后,不会保留备用状态。 |
(?!……) | 否定顺序环视。只匹配位置,不匹配文本 |
(?<=……) | 肯定逆序环视。只匹配位置,不匹配文本 |
(?<!……) | 否定逆序环视。只匹配位置,不匹配文本 |
(?<!\pL)(?=\pL)……(?<=\pL)(?!\pL) | 单词开始……结束(java) |
| (?i)…… | 不区分大小写 |
| (?-i)…… | 区分大小写 |
| (?x) | 宽松排序和注释模式。空白字符作为一个“无意义元字符”,(\12 3表示3接在\12后面,而不是\123);#符号与换行符号之间的内容视为注释。 |
| (?s) | 点号通配模式,点号可以匹配换行符 |
| (?m) | 增强的行锚点模式(多行模式),使^与$可以匹配字符串内部的换行符,但\A、\Z与\z不会改变 |
| (?modifier:……) | 模式修饰范围,简化正则表达式,如(?i:……)非捕获不区分大小写 |
| \Q……\E | 消除其中除\E之外的所有元字符的特殊含义,相当于java中Pattern.quote()方法,在使用变量构建正则表达式时非常有用 |
| *、+、?、{min,max} | 匹配优先量词。先使用当前表达式匹配所有可匹配的,再匹配后面的表达式,如果需要,逐步释放已匹配字符 |
| *?、+?、??、{min,max}? | 忽略优先量词。先忽略当前表达式,去匹配后面表达式;不成功,则使用当前表达式去匹配一个字符,又先忽略当前,去匹配后面;如此循环,出现惰性匹配的现象。DFA引擎不支持忽略优先 |
| *+、++、?+、{min,max}+ | 占有优先量词。匹配成功后,不创建备用状态。可以使用固化分组来实现,如.++与(?>.+)的结果一样 |
| (?>……) | 固化分组。匹配成功,放弃分组内的备用状态,所以不会释放已匹配字符,正确的使用可以能够提高匹配的效率。注意(?>.*?)这个表达式无法匹配任何字符。 |
正则表达式的匹配原理
java使用的是传统型NFA引擎
正则引擎分类
1.DFA(Deterministic Finite Automaton确定型有穷自动机)
文本主导。
不支持捕获型括号和回溯。
匹配速度非常快。
2.NFA(Nondeterministic Finite Automaton非确定型有穷自动机)
表达式主导
1).传统型NFA
2).POSIX NFA
3.DFA与NFA混合
NFA
特性:忽略优先、固化分组、环视、条件判断、反向引用(引用捕获内容)
1.回溯
依次处理各个子表达式或组成元素,遇到需要在两个可能成功的可能中进行选择的时候,会选择其一,同时记住另一个,以备稍后可能的需要。
需要做出选择的情形包括量词与多选结构。
如果需要在“进行尝试”与“跳过尝试”之间选择,对于匹配优先,引擎会优先选择“进行尝试”,而对于忽略优先,会选择“跳过尝试”。
距离当前最近储存的选项就是本地失败强制回溯时返回的。使用的原则是LIFO后进先出。
回溯过程参考图
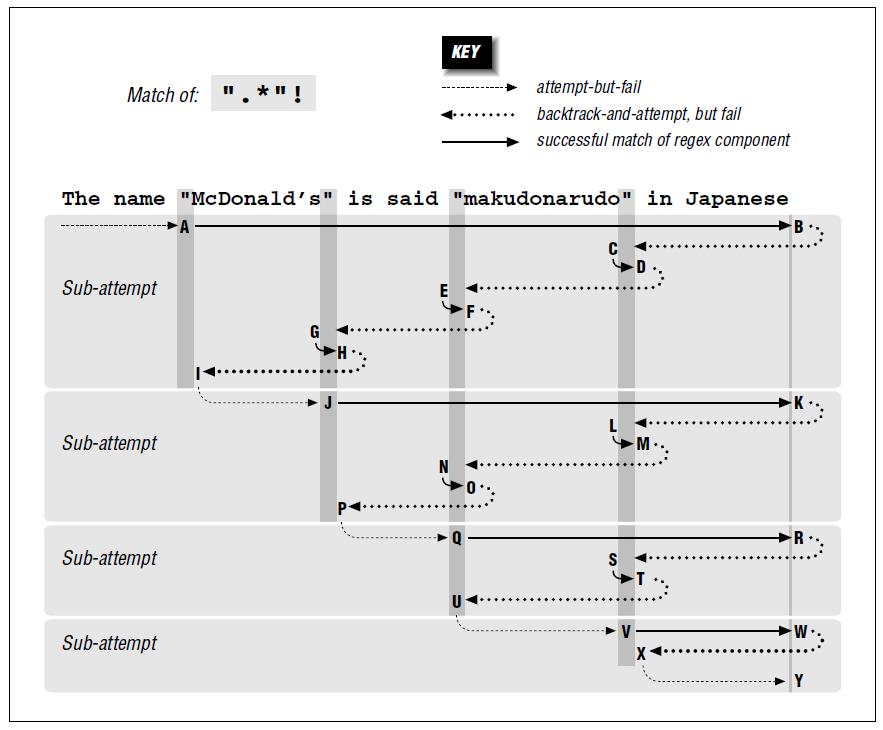
下图是无匹配结果的回溯过程:
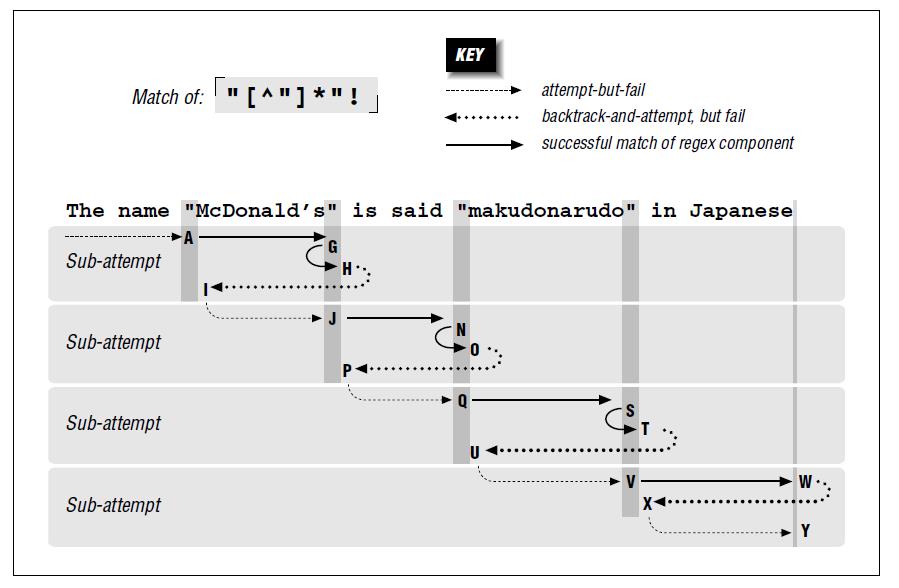
下图是优化后的匹配过程:
2.匹配优先
尽可能多的匹配。如使用^.*test$来匹配this is test,.*会首先匹配到行尾,但由于还需要匹配test,所以.*匹配的内容将“被迫”交还一些字符。
// 测试匹配优先
public static void testGreediness() {
String text = "The name \"McDonald's\" is said \"makudonarudo\" in Japanese";
String regex = "(\".*\")";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(text);
System.out.println(m.find()); // true
System.out.println(m.groupCount()); // 1
// 匹配优先。.*会匹配到行末尾,之后回溯一个备用状态(此处就类型被迫交还一个字符)
System.out.println(m.group(1)); // "McDonald's" is said "makudonarudo"
}
// 测试匹配优先2
public static void testGreediness2() {
String text = "The name \"McDonald's\" is said \"makudonarudo\" in Japanese";
String regex = "(\"[^\"]*\")";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(text);
System.out.println(m.find()); // true
System.out.println(m.groupCount()); // 1
System.out.println(m.group(1)); // "McDonald's"
}3.忽略优先
步步为营。遇到量词,尽可能忽略,先匹配后面的正则部分,若不行,再回头。
public static void testLazyQuantifiers() {
String text = "The name \"McDonald's\" is said \"makudonarudo\" in Japanese";
String regex = "(\".*?\")";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(text);
System.out.println(m.find()); // true
System.out.println(m.groupCount()); // 1
// 忽略优先。.*会先忽略,使用其后面的引号进行匹配,不行的话,回头使用点号匹配一个字符,再如此循环继续。
System.out.println(m.group(1)); // "McDonald's"
}4.占有优先
?+, ++, ++, and {min,max}+
占有优先量词与匹配优先量词很相似,只是它们从来不交还已经匹配到的字符,占有优先不会创建备用状态。这区别于固化分组,固化分组是分组匹配完毕后,放弃组内的备用状态。
5.固化分组
(?>……)
如果匹配到此结构的闭括号之后,那么此结构内的所有备用状态都会被放弃。也就是说,在固化分组结束时,它已经匹配的文本已经固化为一个单位,只能作为整体而保留或放弃。
正确使用可以有效提高匹配效率。如果确定某一部分是不需要回溯的,可以使用固化分组。
6.环视
在环视结构匹配尝试结束后,不会留下任何备用状态。
环视结构不匹配任何字符,只匹配文本中的特定位置,这一点与单词分界符\b、锚点^和$相似。
四种类型的环视
| 类型 | 正则表达式 | 说明 |
|---|---|---|
| 肯定逆序环视 否定逆序环视 | (?<=……) (?<!……) | 匹配一个位置,子表达能够匹配这个位置的左则文本 匹配一个位置,子表达不能匹配这个位置的左则文本 |
| 肯定顺序环视 否定顺序环视 | (?=……) (?!……) | 匹配一个位置,子表达能够匹配这个位置的右则文本 匹配一个位置,子表达不能匹配这个位置的右则文本 |
示例:使用环视分隔数字
public static void lookaround() {
// 1纯数字
String str = "134545756";
// (?:...) 非捕获
String regex = "(?<=\\d)(?=(?:\\d\\d\\d)+$)";
str = str.replaceAll(regex, ",");
System.out.println(str); // 输出134,545,756
// 2非纯数字
str = "134545756$";
regex = "(?<=\\d)(?=(\\d\\d\\d)+(?!\\d))";
str = str.replaceAll(regex, ",");
System.out.println(str); // 输出134,545,756$
}正则优化技巧
1.避免重新编译
2.使用非捕获括号
3.不要滥用括号(包括非捕获型括号)
4.不要滥用字符组,如单字符的最好使转义即可
5.使用锚点(如^、\A、$)
6.从量词中提取必须的元素,如使用XX*代替X+
7.提取多选结构开头的必须元素,如使用th(?:is|at)代替(?:this|that)
8.理解匹配优先与忽略优先的原理,合理地使用它们
9.对大多数引擎来说,排除型字符组的效率比忽略优先量词的效率高的多
10.模拟字符开头字符识别,如使用环视,但由于环视也需要一定的开销
11.理解固化分组与占有优先量词的原理,如果可以,尽量使用它们
12.将最可能匹配的多选分支放在前头
示例
匹配24小时制时间
public static void match24H() {
String str = "23";
String regex = "2[0-3]|[01]?[0-9]"; // 注意尽量不要使用[01]?[0-9]|2[0-3],因为多选结构,会按顺序进行匹配。
System.out.println(str.matches(regex)); // true
}java中使用捕获的值
// 测试代码
public static void testGroup() {
String text = "test456Group";
String regex = "\\w+?(?<gname>\\d+)\\w+";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(text);
System.out.println(m.find());
System.out.println(m.groupCount()); // 分组数量,输出1
System.out.println(m.group(0)); // 完整匹配,输出test456Group
System.out.println(m.group(1)); // 每一组匹配文本,输出456
System.out.println(m.group("gname")); // 使用命名捕获,输出456
}
// 将email转换为url形式
public static void testEmailToUrl() {
String text = "test@gmail.com";
Pattern r = Pattern.compile("\\b(\\w[-.\\w]+@[-\\w]+(?:\\.[-\\w]+)+)\\b", Pattern.CASE_INSENSITIVE);
Matcher m = r.matcher(text);
text = m.replaceAll("<a href=\"mailto:$1\">$1</a>");
System.out.println(text); // <a href="mailto:chencye@126.com">chencye@126.com</a>
}区分大小写
注意:(?i)中是i而不是叹号
public static void testCaseSensitive() {
String text = "testCaseSensitive";
String regex = "[a-z]+";
System.out.println(text.matches(regex)); // false,默认区分大小写
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m = pattern.matcher(text);
System.out.println(m.matches()); // true,不区分大小写,作用于全局
String text2 = "testCASE";
String regex2 = "(?i)^[a-z]+$";
System.out.println(text2.matches(regex2)); // true (?i)不区分大小写
String text3 = "test2CASE3Test";
String regex3 = "^[a-z]+\\d(?i)[a-z]+\\d[a-z]+$";
System.out.println(text3.matches(regex3)); // true (?i)作用于其它后面部分
String text4 = "test2CASE3Test";
String regex4 = "^[a-z]+\\d(?:(?i)[a-z]+)\\d[a-z]+$";
System.out.println(text4.matches(regex4)); // false (?i)作用于局部,可修改为(?i:[a-z]+)非捕获不区分大小写
// (?-i)区分大小写
regex = "(?-i)[a-z]+";
pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
m = pattern.matcher(text);
System.out.println(m.matches()); // false,区分大小写,即使设置了Pattern.CASE_INSENSITIVE
}匹配及解析链接
// 匹配及解析链接
public static void testURL() {
String text = "http://localhost:8080/test/index.jsp?name=chencye&action=test";//
String regex = "(?i)^(?:https?|ftp)://([a-zA-Z]++):?+(\\d*+)([^?\\s]++)\\??+((?:[^=\\s]++=?+[^=&]?+&?+)*+)$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(text);
System.out.println(m.matches()); // true
m.reset();
System.out.println(m.find()); // true
System.out.println(m.groupCount()); // 4
String host = m.replaceAll("$1");
System.out.println("host: [" + host + "]"); // host: [localhost]
String port = m.replaceAll("$2");
System.out.println("port: [" + port + "]"); // port: [8080]
String path = m.replaceAll("$3");
System.out.println("path: [" + path + "]"); // path: [/test/index.jsp]
String params = m.replaceAll("$4");
System.out.println("params:[" + params + "]"); // params:[name=chencye&action=test]
}














 9251
9251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









