







前言
ElasticSearch 是一个高可用开源全文检索和分析组件。提供存储服务,搜索服务,大数据准实时分析等。一般用于提供一些提供复杂搜索的应用。
ElasticSearch 提供了一套基于restful风格的全文检索服务组件。前身是compass,直到2010被一家公司接管进行维护,开始商业化,并提供了ElasticSearch 一些相关的产品,包括大家比较熟悉的 kibana、logstash 以及 ElasticSearch 的一些组件,比如 安全组件shield 。当前最新的EElasticSearch 版本为 5.1.1 ,比较应用广泛的为2.X,直到 2016-12 推出了5.x 版本 ,将版本号调为 5.X 。这是为了和 kibana 和 logstash 等产品版本号进行统一 ElasticSearch 。
准实时:ElasticSearch 是一个准实时的搜索工具,在一般情况下延时少于一秒。
特点
1.开箱即用
支持物理上的水平扩展,并拥有一套分布式协调的管理功能
2.操作简单
i:单节点的ES,安装启动后,会默认创建一个名为elasticsearch的es集群。如果在局域网中存在该clustr.name,会自动加入该集群。形成一个ElasticSearch 集群 。
ii:多节点ES,在同一个局域网内的ES服务,只需要配置为同一个clust.name 名称即可成为
一个ES集群。集群能够将同一个索引的分片,自动分布到各个节点。并在高效的提供查询服务的同时,自动协调每个节点的下线以及上线情况。
3.restful 风格的API
提供了一套关于索引以及状态查看的restful风格接口。至于什么是Restful风格服务,请移步
对比Solr
Solr与ES都是基于java/lucence来做一套面向文档结构的Nosql结构的数据库。
1.分布式
solr 分布式 需要结合zookeeper 来实现,ES 自身有相关分布式协调。
2.支持的数据结构
solr支持 xml json html 等多种数据结构,而ES 仅支持json这种结构。
3.性能
solr在新建索引时是IO阻塞的,所以如果在新建索引时同时进行搜索这时候相比ES来的相对较快。所以在实时性上,ElasticSearch 相比还是更好的选择。
对比MongoDB
MongoDB与ES都是一种Nosql结构的处理方式,故在这里也进行一些比较
1.分布式
MongoDB支持副本集的集群方式,而ES同样支持分布式结构
2.数据结构
MongoDB支持json方式,这点与ES也是一样。MongoDB同样还支持 Grid 方式来存放多媒体文档,这点Es是不支持的。
3.事务性
在这点上MongoDB和ES倒是有点类似,都没有对于强事务的支持。虽然MongoDB手册中有两阶段的方式来支持多个文档的操作事务的支持,但是一般情况都好像没有使用到。
从人的认知系统来说,总是倾向于的将一些未知和陌生的事物联系到自身已经有的知识系统上,或者实例化到实际生活中某个场景。我们会经常看到一些‘helloworld’程序结合生活中的实例来理解,也是这个道理。这里为了我们更好的理解 ElasticSearch 这样一个全文检索的工具
联系到之前常用的关系型数据库Mysql,但这里并不能完全类同,因为本身两个存储方式有差异,这里的比较仅限辅助理解。
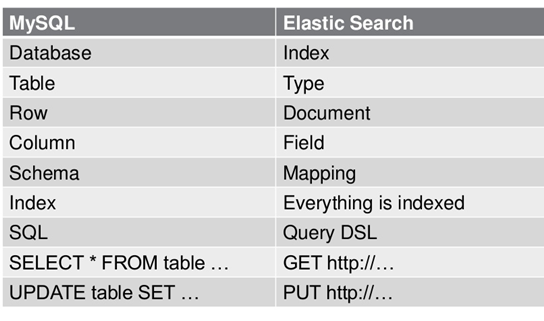
基本概念
Index
定义:类似于mysql中的database。索引只是一个逻辑上的空间,物理上是分为多个文件来管理的。
命名:必须全小写
描述:因为本身ES是基于Lucene的,所以内部索引的本质上其实Lucene的索引构造方式,具体Lucene的 索
引文件具体分为那几个文件,之前我在Lucene部分的有过介绍【http://blog.csdn.net/cfl20121314/article/details/46008203 】。
ES中index可能被分为多个分片【对应物理上的lcenne索引】,在实践过程中每个index都会有一个相应的副
本。主要用来在硬件出现问题时,用来回滚数据的。这也某种程序上,加剧了ES对于内存高要求。
Type
定义:类似于mysql中的table,ES6.0之前理论上根据用户需求每个index中可以新建任意数量的type。同一个index中不同的type之间相同的字段命名的的类型需要保持一致;随着es6,es7升级之后,在6的版本中每个index中仅限一个type,7的版本则是直接去除type的概念。升级之后的es版本推荐的做法,在遇到需要多type的时候建议使用不同index来处理。
Document
定义:对应mysql中的row。有点类似于MongoDB中的文档结构,每个Document是一个json格式的文本。每个文档不会跨分片处理。
Mapping
更像是一个用来定义每个字段类型的语义规范在mysql中类似sql语句,在ES中经过包装后,都被封装为友好的Restful风格的接口进行操作。这一点也是为什么开发人员更愿意使用ES或者compass这样的框架而不是直接使用Lucene的一个原因。
Shards & Replicas
定义:能够为每个索引提供水平的扩展以及备份操作。
描述:
Shards:在单个节点中,index的存储始终是有限制,并且随着存储的增大会带来性能的问题。为了解决这个问题,ElasticSearch提供一个能够分割单个index到集群各个节点的功能。你可以在新建这个索引时,手动的定义每个索引分片的数量。
Replicas:在每个node出现宕机或者下线的情况,Replicas能够在该节点下线的同时将副本同时自动分配到其他仍然可用的节点。而且在提供搜索的同时,允许进行扩展节点的数量,在这个期间并不会出现服务终止的情况。
默认情况下,每个索引会分配5个分片,并且对应5个分片副本,同时会出现一个完整的副本【包括5个分配的副本数据】。
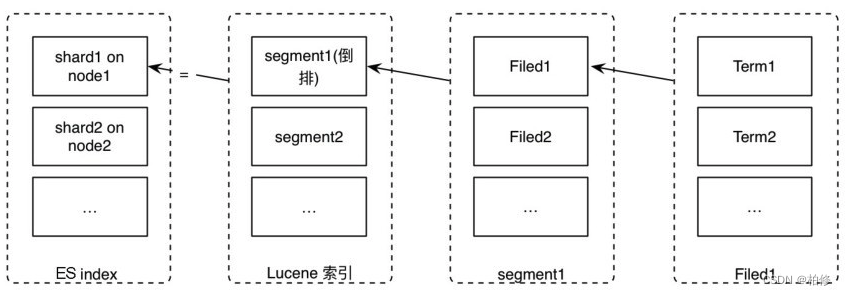
如上我们使用一张图来总结索引,分片,以及一个lucene索引,分段,term分词的关系。
在我们建立一个index索引的时候默认为5个主分片,同时也会设置5个主分片对应的副分片。
一个分片通过es会将分片分配到指定node节点,一个分片本质上就是一个lucene索引。
lucene索引内部则由很多分段注册,每个分段都是一个倒排索引。
而在分段内部不同的字段都自己的倒排索引,根据分词每个字段则又被拆为几个词注册,这里的分词则又由不同的分词器甚至自定义的分词器进行转换。
言而总之,用一句话来总结下。ElasticSearch 是一个基于 lucence 可水平扩展的自动化近实时全文搜索服务组件。
FAQ:
1.es 为什么是准实时的搜索引擎
2.
参考文档:
ElasticSearch 官方文档 [https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html]
索引的原理:http://blog.chinaunix.net/uid-22679909-id-1771453.html














 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









