







个人学习笔记
源自B站尚硅谷讲师宋红康的MySQL课程
B站地址:https://www.bilibili.com/video/BV1iq4y1u7vj
都有哪些维度可以进行数据库调优?简言之:
- 索引失效、没有充分利用到索引――索引建立
- 关联查询太多JOIN (设计缺陷或不得已的需求)—-SQL优化。
- 服务器调优及各个参数设置(缓冲、线程数等)――调整my.cnf
- 数据过多――分库分表
关于数据库调优的知识点非常分散。不同的DBMS,不同的公司,不同的职位,不同的项目遇到的问题都不尽相同。这里我们分为三个章节进行细致讲解。
虽然SQL查询优化的技术有很多,但是大方向上完全可以分成 物理查询优化 和 逻辑查询优化 两大块。
- 物理查询优化是通过
索引和表连接方式等技术来进行优化,这里重点需要掌握索引的使用。 - 逻辑查询优化就是通过SQL等价变换提升查询效率,直白一点就是说,换一种查询写法执行效率可能更高。
1. 数据准备
学员表 插 50万 条, 班级表 插 1万 条
创建数据库
CREATE DATABASE atguigudb2;
USE atguigudb2;
步骤1:建表
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
步骤2:设置参数
- 命令开启:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
步骤3:创建函数
保证每条数据都不同。
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#假如要删除
#drop function rand_string;
随机产生班级编号
#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT)
RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1));
RETURN i;
END //
DELIMITER ;
#假如要删除
#drop function rand_num;
步骤4:创建存储过程
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, name ,age ,classId ) VALUES ((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_stu;
创建往class表中插入数据的存储过程
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor) VALUES (rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_class;
步骤5:调用存储过程
class
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
stu
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
步骤6:删除某表上的索引
创建存储过程
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>'PRIMARY' ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
执行存储过程
CALL proc_drop_index("dbname","tablename");
2.1 全值匹配我最爱
系统中经常出现的sql语句如下:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd' ;
建立索引前执行:(关注执行时间)
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd ';
Empty set,1 warning (0.28 sec)
建立索引
CREATE INDEX idx_age ON student( age ) ;
CREATE INDEX idx_age_classid ON student( age , classId);
CREATE INDEX idx_age_classid_name ON student( age ,classId , name ) ;
建立索引后执行:
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId=4 AND name = 'abcd ';
Empty set, 1 warning (0.01 sec)
可以看到,创建索引前的查询时间是 0.28 秒,创建索引后的查询时间是 0.01 秒,索引帮助我们极大的提高了查询效率。
2.2 最佳左前缀法则
在MySQL建立联合索引时会遵守最佳左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
举例1:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd' ;
举例2:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student. name = 'abcd' ;
举例3:索引idx_age_classid_name还能否正常使用?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE classid=4 AND student.age=30 AND student .name= 'abcd' ;
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列;
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name =' abcd';

虽然可以正常使用,但是只有部分被使用到了。
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name =' abcd ' ;

完全没有使用上索引。
结论:MySQL可以为多个字段创建索引,一个索引可以包括16个字段。对于多列索引,过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。 如果查询条件中没有使用这些字段中第1个字段时,多列(或联合)索引不会被使用。
拓展:Alibaba《Java开发手册》
索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
2.3 主键插入顺序
对于一个使用InnoDB存储引擎的表来说,在我们没有显示的创建索引时,表中的数据实际上都是存储在聚簇索引的叶子节点的。而记录又存储在数据页中的,数据页和记录又是按照记录主键值从小到大的顺序进行排序,所以如果我们插入的记录的主键值是依次增大的话,那我们每插满一个数据页就换到下一个数据页继续插,而如果我们插入的主键值忽小忽大的话,则可能会造成页面分裂和记录移位。
假设某个数据页存储的记录已经满了,它存储的主键值在 1~100 之间,
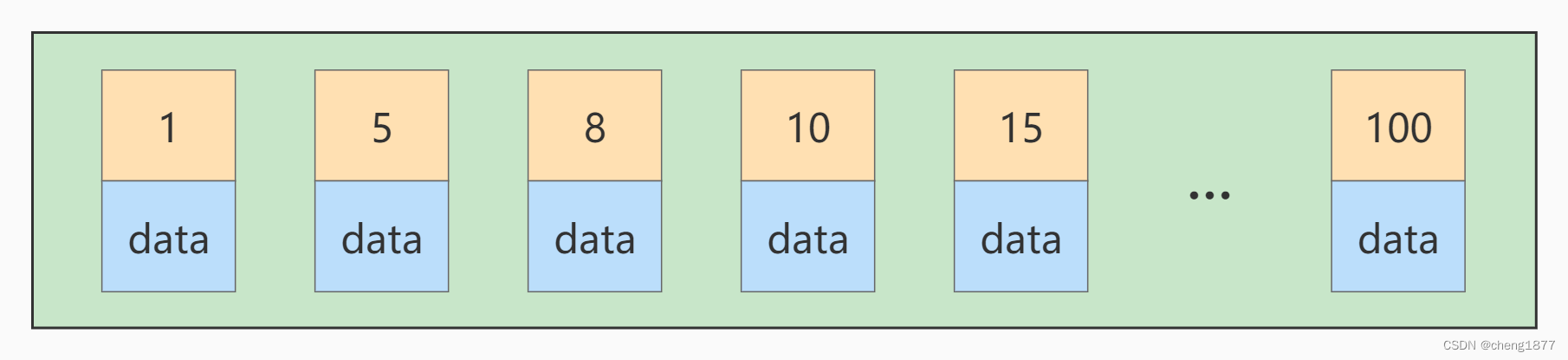
如果此时再插入一条主键值为 9 的记录,那它插入的位置就如下图:
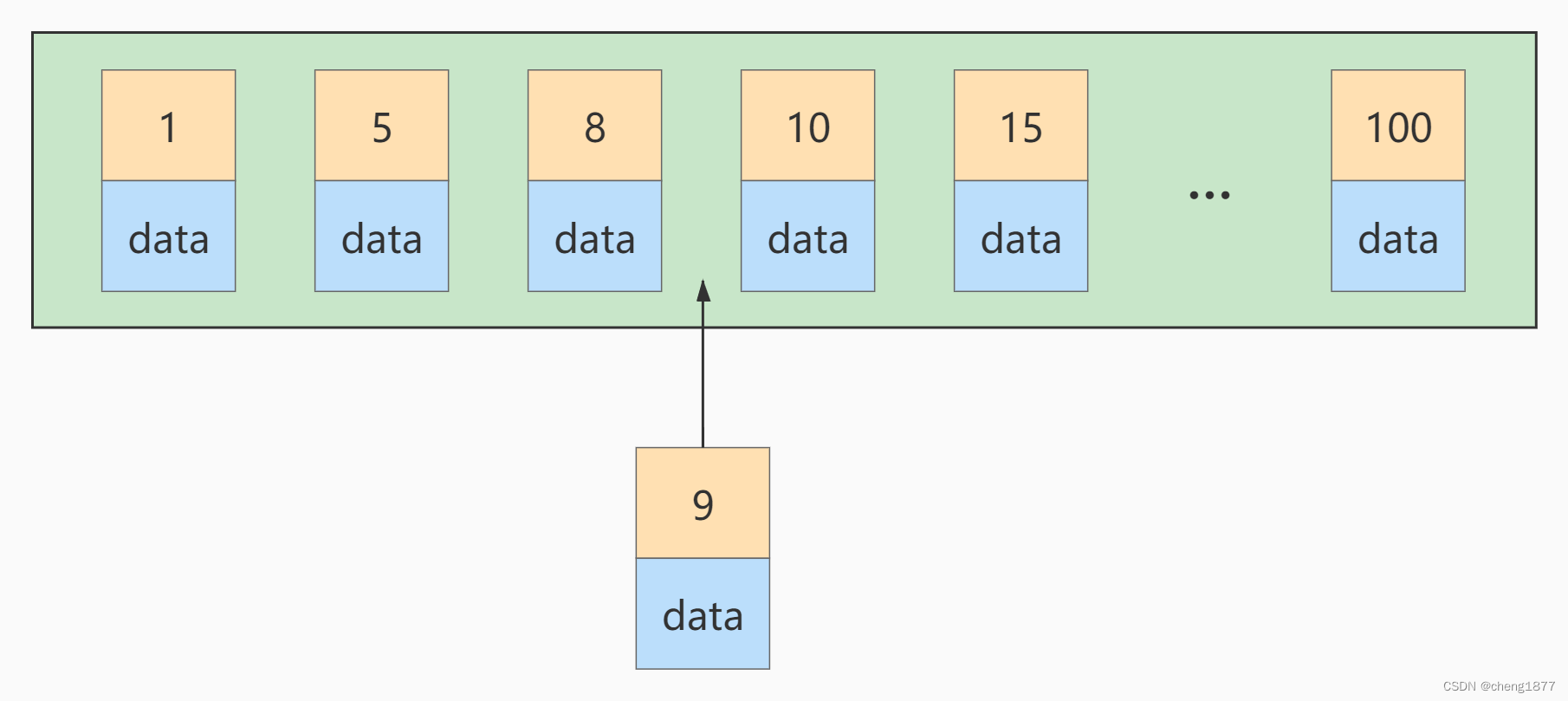
可这个数据页已经满了,再插进来咋办呢?我们需要把当前 页面分裂 成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着: 性能损耗 !所以如果我们想尽量避免这样无谓的性能损耗,最好让插入的记录的 主键值依次递增 ,这样就不会发生这样的性能损耗了。所以我们建议:让主键具有 AUTO_INCREMENT ,让存储引擎自己为表生成主键,而不是我们手动插入 。
比如: person_info 表:
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);
我们自定义的主键列 id 拥有 AUTO_INCREMENT 属性,在插入记录时存储引擎会自动为我们填入自增的主键值。这样的主键占用空间小,顺序写入,减少页分裂。
2.4 计算、函数、类型转换(自动或手动)导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
创建索引
CREATE INDEX idx_name ON student(NAME);
第一种:索引优化生效
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';

SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
mysql> SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
+--------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+--------+--------+--------+------+---------+
| 438056 | 538056 | ABcHeB | 20 | 321 |
| 150883 | 250883 | abciJU | 21 | 388 |
| 171122 | 271122 | aBCiju | 21 | 924 |
| 237412 | 337412 | ABcIjW | 7 | 825 |
| 354085 | 454085 | aBCikB | 3 | 661 |
| 482399 | 582399 | ABcJlg | 48 | 386 |
| 488710 | 588710 | ABcJlg | 46 | 221 |
| 255517 | 355517 | aBCjmI | 33 | 190 |
| 389862 | 489862 | AbCJMI | 6 | 514 |
| 95480 | 195480 | ABcJnm | 21 | 364 |
| 474364 | 574364 | ABcJno | 30 | 141 |
| 25447 | 125447 | AbCJPW | 15 | 628 |
| 410171 | 510171 | ABcKqA | 29 | 334 |
| 440453 | 540453 | aBCkqb | 10 | 824 |
| 150817 | 250817 | AbCKQY | 23 | 326 |
| 348398 | 448398 | ABcKsK | 22 | 14 |
| 470809 | 570809 | AbCKTm | 30 | 225 |
| 248457 | 348457 | aBClvu | 37 | 490 |
| 388252 | 488252 | abclWZ | 7 | 721 |
| 162414 | 262414 | AbCLXC | 47 | 988 |
| 1158 | 101158 | abclYh | 40 | 524 |
+--------+--------+--------+------+---------+
21 rows in set, 1 warning (0.00 sec)
mysql> SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'ab%';
+--------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+--------+--------+--------+------+---------+
| 438056 | 538056 | ABcHeB | 20 | 321 |
| 150883 | 250883 | abciJU | 21 | 388 |
| 171122 | 271122 | aBCiju | 21 | 924 |
| 237412 | 337412 | ABcIjW | 7 | 825 |
| 354085 | 454085 | aBCikB | 3 | 661 |
| 482399 | 582399 | ABcJlg | 48 | 386 |
| 488710 | 588710 | ABcJlg | 46 | 221 |
| 255517 | 355517 | aBCjmI | 33 | 190 |
.......
| 351097 | 451097 | ABhfeg | 19 | 438 |
| 233473 | 333473 | ABhffj | 33 | 667 |
| 282412 | 382412 | abhFFj | 5 | 912 |
| 494189 | 594189 | aBHFfJ | 4 | 359 |
| 234145 | 334145 | AbJZgF | 35 | 668 |
| 346191 | 446191 | AbJZgH | 42 | 218 |
| 399207 | 499207 | AbJZgH | 45 | 450 |
| 63895 | 163895 | AbJZhK | 4 | 249 |
+--------+--------+--------+------+---------+
728 rows in set, 1 warning (0.01 sec)
type为"range”,表示有使用到索引,查询时间仅为0.01秒。
第二种:索引优化失效
mysq1> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';

mysql> SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
+--------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+--------+--------+--------+------+---------+
| 1158 | 101158 | abclYh | 40 | 524 |
| 25447 | 125447 | AbCJPW | 15 | 628 |
| 95480 | 195480 | ABcJnm | 21 | 364 |
| 150817 | 250817 | AbCKQY | 23 | 326 |
| 150883 | 250883 | abciJU | 21 | 388 |
| 162414 | 262414 | AbCLXC | 47 | 988 |
| 171122 | 271122 | aBCiju | 21 | 924 |
| 237412 | 337412 | ABcIjW | 7 | 825 |
| 248457 | 348457 | aBClvu | 37 | 490 |
| 255517 | 355517 | aBCjmI | 33 | 190 |
| 348398 | 448398 | ABcKsK | 22 | 14 |
| 354085 | 454085 | aBCikB | 3 | 661 |
| 388252 | 488252 | abclWZ | 7 | 721 |
| 389862 | 489862 | AbCJMI | 6 | 514 |
| 410171 | 510171 | ABcKqA | 29 | 334 |
| 438056 | 538056 | ABcHeB | 20 | 321 |
| 440453 | 540453 | aBCkqb | 10 | 824 |
| 470809 | 570809 | AbCKTm | 30 | 225 |
| 474364 | 574364 | ABcJno | 30 | 141 |
| 482399 | 582399 | ABcJlg | 48 | 386 |
| 488710 | 588710 | ABcJlg | 46 | 221 |
+--------+--------+--------+------+---------+
21 rows in set, 1 warning (0.13 sec)
type为“ALL”,表示没有使用到索引,查询时间为0.13秒,查询效率较之前低很多。
再举例:
- student表的字段stuno上设置有索引
CREATE INDEX idx_sno ON student(stuno);
- 索引优化失效:(假设: student表的字段stuno上设置有索引)
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 500001;
运行结果:

EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 500000;

mysql> SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 500001;
+--------+--------+--------+
| id | stuno | NAME |
+--------+--------+--------+
| 400000 | 500000 | NohQJW |
+--------+--------+--------+
1 row in set, 1 warning (0.12 sec)
mysql> SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 500000;
+--------+--------+--------+
| id | stuno | NAME |
+--------+--------+--------+
| 400000 | 500000 | NohQJW |
+--------+--------+--------+
1 row in set, 1 warning (0.00 sec)
你能看到如果对索引进行了表达式计算,索引就失效了。这是因为我们需要把索引字段的取值都取出来,然后依次进行表达式的计算来进行条件判断,因此采用的就是 全表扫描 的方式,运行时间也会慢很多,最终运行时间为 0.12 秒。
- 索引优化生效
SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 500000;
运行时间为 0.00 秒。
再举例:
- student表的字段name上设置有索引
CREATE INDEX idxlname ON student(NAME);
我们想要对name的前三位为abc的内容进行条件筛选,这里我们来查看下执行计划:
- 索引优化失效
EXPLAIN SELECT id, stuno, name FROM student WHERE SUBSTRING( name, 1,3)='abc';

- 索引优化生效
EXPLAIN SELECT id, stuno, name FROM student WHERE `name` like 'abc%';

你能看到经过查询重写后,可以使用索引进行范围检索,从而提升查询效率。
2.5类型转换导致索引失效
下列哪个sql语句可以用到索引。(假设name字段上设置有索引)
#未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;

#使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';

- name=123发生类型转换,索引失效。
结论:设计实体类属性时,一定要与数据库字段类型相对应。否则,就会出现类型转换的情况。
2.6范围条件右边的列索引失效
- 如果系统经常出现的sql如下:
#删除索引-存储过程
CALL proc_drop_index('atguigudb2', 'student')
#删除索引-逐个删除
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
ALTER TABLE student DROP INDEX idx_age_classid_name;
SHOW INDEX FROM student;
CREATE INDEX idx_age_classId_name oN student (age,classId,`name`);
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc';

2. 那么索引 idx_age_classid_name这个索引还能正常使用么?
-
不能,范围右边的列不能使用。比如:(<)(<=)(>)(>=)和 between 等。
-
如果这种sql出现较多,应该建立:
create index idx_age_name_classid on student(age, name, classid); -
·将范围查询条件放置语句最后:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abc' AND student.classId>20 ;

应用开发中范围查询,例如:金额查询,日期查询往往都是范围查询。应将查询条件放置where语句最后。(创建的联合索引中,务必把范围涉及到的字段写在最后)
2.7不等于(!= 或者<>)索引失效
- 为name字段创建索引
CREATE INDEX idx_name ON student(NAME);
- 查看索引是否失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'abc' ;

或者
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'abc' ;

场景举例:用户提出需求,将财务数据,产品利润金额不等于0的都统计出来。
2.8 is null可以使用索引,is not null无法使用索引
- IS NULL:可以触发索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;

结论:最好在设计数据表的时候就将
字段设置为 NOT NULL 约束,比如你可以将INT类型的字段,默认值设置为0。将字符类型的默认值设置为空字符串(‘’)
拓展:同理,在查询中使用
not like也无法使用索引,导致全表扫描
2.9 like以通配符%开头索引失效
在使用LIKE关键字进行查询的查询语句中,如果匹配字符串的第一个字符为“%”,索引就不会起作用。只有“%”不在第一个位置,索引才会起作用。
- 使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab%';

- 未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab%';

拓展:Alibaba《Java开发手册》
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
2.10 OR前后存在非索引的列,索引失效
在WHERE子句中,如果在OR前的条件列进行了索引,而在OR后的条件列没有进行索引,那么索引会失效。也就是说,OR前后的两个条件中的列都是索引时,查询中才使用索引。
因为OR的含义就是两个只要满足一个即可,因此 只有一个条件列进行了索引是没有意义的,只要有条件列没有进行索引,就会进行 全表扫描,因此索引的条件列也会失效。
查询语句使用OR关键字的情况:
SHOW INDEX FROM student;
#删除student表所有索引
CALL proc_drop_index('atguigudb2','student');
#重新添加索引,作用在age字段
CREATE INDEX idx_age ON student(age);
#未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

#创建索引,作用在classid字段
CREATE INDEX idx_cid ON student(classid);
#使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

因为age字段和classid字段上都有索引,所以查询中使用了索引。你能看到这里使用到了 index_merge,简单来说index_merge就是对age和classid分别进行了扫描,然后将这两个结果集进行了合并。这样做的好处就是 避免了全表扫描。
2.11 数据库和表的字符集统一使用utf8mb4
统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。不同的字符集进行比较前需要进行转换会造成索引失效。
2.12练习及一般性建议
练习: 假设: index(a,b,c)
| Where语句 | 索引是否被使用 |
|---|---|
| where a= 3 | Y,使用到a |
| where a= 3 and b=5 | Y,使用到a, b |
| where a= 3 and b=5 and c=4 | Y,使用到a,b,c |
| where b= 3 或者 where b=3 and c= 4 或者 where c= 4 | N |
| where a= 3 and c=5 | 使用到a,但是c不可以, b中间断了 |
| where a= 3 and b>4 and c=5 | 使用到a和b,c不能用在范围之后, b断了 |
| where a is null and b is not null | is null支持索引但是is not null不支持。 所以a可以使用索引, 但是b不可以使用 |
| where a <> 3 | 不能使用索引 |
| where abs(a)=3 | 不能使用索引 |
where a=3 and b like 'kk%' and c =4 | Y,使用到a,b,c |
| where a=3 and b like ‘%kk’ and c=4 | Y,只用到a |
| where a=3 and b like ‘%kk%’ and c=4 | Y,只用到a |
where a=3 and b like 'k%kk%' and c=4 | Y,使用到a,b,c |
一般性建议:
- 对于单列索引,尽量选择针对当前query过滤性更好的索引。
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引|字段顺序中,位置越靠前越好。
- 在选择组合索引的时候,尽量选择能够包含当前query中的where子句中更多字段的索引。
- 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面。
总之,书写SQL语句时,尽量避免造成索引失效的情况。















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









