






任务
使用Pytorch实现简单的网络模型搭建
准备工作
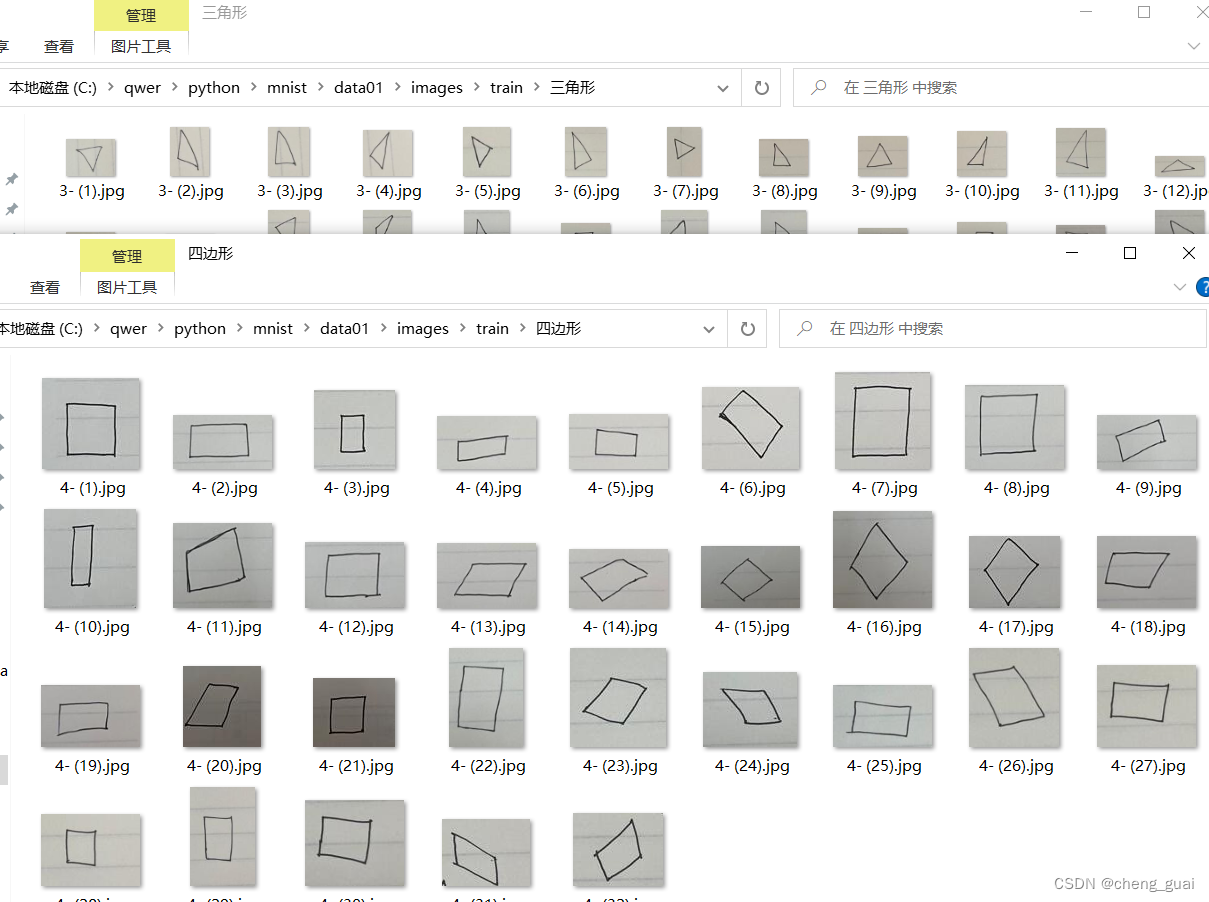
首先需要准备自己的数据集,比如我自己的数据集为一个简单的二分类,实现识别三角形和四边形,如下图所示

代码实现
搭建网络模型
首先搭建一个简单的网络模型,主要包含卷积、池化、全连接。其中参数可以根据自己需求更改。
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(3, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(64, 128, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(128, 256, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.dense = torch.nn.Sequential(
torch.nn.Linear(256 * 37 * 37, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 2)
)
def forward(self, x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
res = conv3_out.view(conv3_out.size(0), -1)
out = self.dense(res)
return out数据处理及加载
将原始图像根据需求进行简单处理(包括更改尺寸,变换数据类型等)并加载。
transform = transforms.Compose([
transforms.Resize((300, 300)),
transforms.ToTensor()
])
transform_test = transforms.Compose([
transforms.Resize((300, 300)),
transforms.ToTensor()
])
# 使用ImageFolder加载图像数据集
'''
ImageFolder会自动为加载的图像分配标签,这些标签是基于子文件夹的名称来分配的。
每个子文件夹的名称将被视为一个类别,而其中的图像将被分配相应的类别标签。
这减少了手动标记数据的工作。
'''
dataset_train = torchvision.datasets.ImageFolder('C:/qwer/python/mnist/data01/images/train',transform)
dataset_test = torchvision.datasets.ImageFolder('C:/qwer/python/mnist/data01/images/test',transform_test)
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)模型加载以及设置一些参数
model = Net().to(DEVICE)
# print(model)
# 学习率,如果不提供学习率参数,Pytorch将使用默认学习率值0.01
learning_rate = 0.01
# 优化器,定义优化器,并将模型参数传给优化器
optimizer = torch.optim.Adam(model.parameters(),lr = learning_rate)
# 损失函数
loss_func = torch.nn.CrossEntropyLoss()
# 用数组保存每一轮迭代中,训练的损失值和精确度,也是为了通过画图展示出来。
train_losses = []
train_acces = []
# 用数组保存每一轮迭代中,在测试数据上测试的损失值和精确度,也是为了通过画图展示出来。
eval_losses = []
eval_acces = []训练
训练次数可以自己根据需求更改。
num_epoch = 45
for epoch in range(num_epoch):
print('epoch {}'.format(epoch + 1))
# ==========================训练模式==========================
train_loss = 0.
train_acc = 0.
model.train() # 将模型改为训练模式
for tra_inputs, tra_labels in train_loader:
tra_inputs, tra_labels = Variable(tra_inputs).to(DEVICE), Variable(tra_labels).to(DEVICE)
# 计算前向传播,并且得到损失函数的值
out = model(tra_inputs)
loss = loss_func(out, tra_labels)
# 记录误差
train_loss += loss.item()
# 计算分类的准确率
pred = torch.max(out, 1)[1]
train_correct = (pred == tra_labels).sum()
train_acc += train_correct.item()
# 反向传播,把上一次的梯度清零,并且step更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(train_loss / len(dataset_train))
train_acces.append(train_acc / len(dataset_train))
# print(len(dataset_train))
print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(
dataset_train)), train_acc / (len(dataset_train))))
# =========================每次进行完一个训练迭代,就去测试一下看看此时的效果==========================
model.eval() # 将模型改为预测模式
eval_loss = 0.
eval_acc = 0.
for val_inputs, val_labels in test_loader:
with torch.no_grad():
val_inputs, val_labels = Variable(val_inputs).to(DEVICE), Variable(val_labels).to(DEVICE)
out = model(val_inputs)
loss = loss_func(out, val_labels)
eval_loss += loss.item()
pred = torch.max(out, 1)[1]
num_correct = (pred == val_labels).sum()
eval_acc += num_correct.item()
eval_losses.append(eval_loss / len(dataset_test))
eval_acces.append(eval_acc / len(dataset_test))
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
dataset_test)), eval_acc / (len(dataset_test))))画图
画出精确度和损失的图像,便于观察,我这里进行了图像的保存,保存图像的位置和名称可以自行更改。
# 画图
plt.plot(np.arange(len(train_losses)), train_losses,label="train loss")
plt.plot(np.arange(len(train_acces)), train_acces, label="train acc")
plt.plot(np.arange(len(eval_losses)), eval_losses, label="valid loss")
plt.plot(np.arange(len(eval_acces)), eval_acces, label="valid acc")
plt.legend() #显示图例
plt.xlabel('epoches')
plt.title('Model accuracy&loss')
# 存储图像
plt.savefig('C:/qwer/python/mnist/lossAndacc/3or4lossandacc-4.png')
plt.show()保存训练的权重
权重的名称以及保存路径可以自己更改。
torch.save(model.state_dict(),'C:/qwer/python/mnist/weights/3or4-4.pth')训练结果
训练之后,可以得到精度和损失的图像以及训练之后的权重文件,后续可以使用得到权重文件来真实检测。
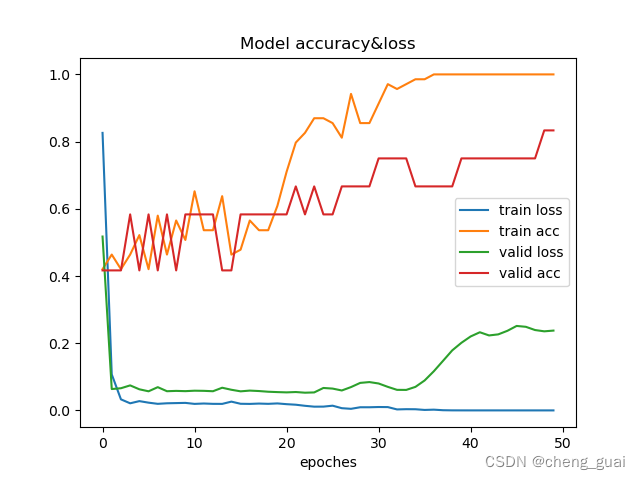
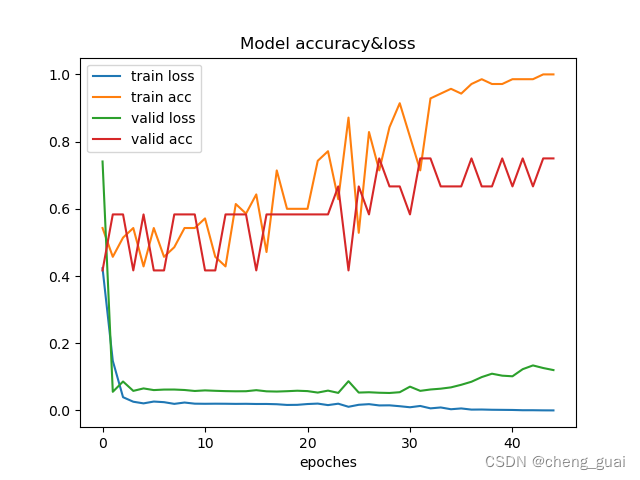
这里对比了两次训练之后的精度与损失图像,可以看出,在接近40轮训练之后,损失开始上升了,这是因为本身的数据集太小,训练的次数过多时,模型开始过度拟合训练数据,验证误差开始上升,即是过拟合现象,当然模型的具体性能还与模型架构和复杂性、学习率和优化器等等有关。
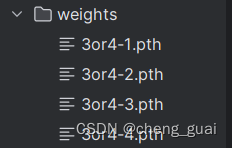
除此之外,还会保存一个训练之后的权重,如下图所示
完整代码
from torch.autograd import Variable
from torch.utils.data import Dataset
from torchvision import transforms
import matplotlib.pyplot as plt
import numpy as np
import os
import torch
import torchvision
from torch.utils import data
from PIL import Image
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
BATCH_SIZE = 64
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(DEVICE)
transform = transforms.Compose([
transforms.Resize((300, 300)),
transforms.ToTensor()
])
transform_test = transforms.Compose([
transforms.Resize((300, 300)),
transforms.ToTensor()
])
# 使用ImageFolder加载图像数据集
'''
ImageFolder会自动为加载的图像分配标签,这些标签是基于子文件夹的名称来分配的。
每个子文件夹的名称将被视为一个类别,而其中的图像将被分配相应的类别标签。
这减少了手动标记数据的工作。
'''
dataset_train = torchvision.datasets.ImageFolder('C:/qwer/python/mnist/data01/images/train',transform)
dataset_test = torchvision.datasets.ImageFolder('C:/qwer/python/mnist/data01/images/test',transform_test)
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(3, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(64, 128, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(128, 256, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.dense = torch.nn.Sequential(
torch.nn.Linear(256 * 37 * 37, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 2)
)
def forward(self, x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
res = conv3_out.view(conv3_out.size(0), -1)
out = self.dense(res)
return out
model = Net().to(DEVICE)
# print(model)
# 学习率,如果不提供学习率参数,Pytorch将使用默认学习率值0.01
learning_rate = 0.01
# 优化器,定义优化器,并将模型参数传给优化器
optimizer = torch.optim.Adam(model.parameters(),lr = learning_rate)
# 损失函数
loss_func = torch.nn.CrossEntropyLoss()
# 用数组保存每一轮迭代中,训练的损失值和精确度,也是为了通过画图展示出来。
train_losses = []
train_acces = []
# 用数组保存每一轮迭代中,在测试数据上测试的损失值和精确度,也是为了通过画图展示出来。
eval_losses = []
eval_acces = []
num_epoch = 45
for epoch in range(num_epoch):
print('epoch {}'.format(epoch + 1))
# ==========================训练模式==========================
train_loss = 0.
train_acc = 0.
model.train() # 将模型改为训练模式
for tra_inputs, tra_labels in train_loader:
tra_inputs, tra_labels = Variable(tra_inputs).to(DEVICE), Variable(tra_labels).to(DEVICE)
# 计算前向传播,并且得到损失函数的值
out = model(tra_inputs)
loss = loss_func(out, tra_labels)
# 记录误差
train_loss += loss.item()
# 计算分类的准确率
pred = torch.max(out, 1)[1]
train_correct = (pred == tra_labels).sum()
train_acc += train_correct.item()
# 反向传播,把上一次的梯度清零,并且step更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(train_loss / len(dataset_train))
train_acces.append(train_acc / len(dataset_train))
# print(len(dataset_train))
print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(
dataset_train)), train_acc / (len(dataset_train))))
# =========================每次进行完一个训练迭代,就去测试一下看看此时的效果==========================
model.eval() # 将模型改为预测模式
eval_loss = 0.
eval_acc = 0.
for val_inputs, val_labels in test_loader:
with torch.no_grad():
val_inputs, val_labels = Variable(val_inputs).to(DEVICE), Variable(val_labels).to(DEVICE)
out = model(val_inputs)
loss = loss_func(out, val_labels)
eval_loss += loss.item()
pred = torch.max(out, 1)[1]
num_correct = (pred == val_labels).sum()
eval_acc += num_correct.item()
eval_losses.append(eval_loss / len(dataset_test))
eval_acces.append(eval_acc / len(dataset_test))
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
dataset_test)), eval_acc / (len(dataset_test))))
# 画图
plt.plot(np.arange(len(train_losses)), train_losses,label="train loss")
plt.plot(np.arange(len(train_acces)), train_acces, label="train acc")
plt.plot(np.arange(len(eval_losses)), eval_losses, label="valid loss")
plt.plot(np.arange(len(eval_acces)), eval_acces, label="valid acc")
plt.legend() #显示图例
plt.xlabel('epoches')
plt.title('Model accuracy&loss')
# 存储图像
plt.savefig('C:/qwer/python/mnist/lossAndacc/3or4lossandacc-4.png')
plt.show()
# 保存训练的权重
torch.save(model.state_dict(),'C:/qwer/python/mnist/weights/3or4-4.pth')测试模型
新建一个python文件,编写代码用于测试保存下来的权重。
import torch
from torchvision import transforms
from PIL import Image
import torch.nn as nn
# 定义模型结构
class MyModel(nn.Module):
def __init__(self):
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(3, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(64, 128, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(128, 256, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.dense = torch.nn.Sequential(
torch.nn.Linear(256 * 37 * 37, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 2)
)
def forward(self, x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
res = conv3_out.view(conv3_out.size(0), -1)
out = self.dense(res)
return out
# 创建模型实例
model = MyModel()
# model = Net()
# 加载模型参数
model.load_state_dict(torch.load('C:/qwer/python/mnist/weights/3or4-4.pth'))
# 设置模型状态
model.eval() # 只是进行推理,设置模型为评估模式
preprocess = transforms.Compose([
transforms.Resize((300, 300)),
transforms.ToTensor(),
])
# 加载要分类的图像
image_path = 'C:/qwer/python/mnist/data01/images/detect/302.jpg'
image = Image.open(image_path)
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0) # 添加一个维度,模型期望的是批次
# 使用模型进行推理
with torch.no_grad():
output = model(input_batch)
# 解析输出
# 根据需求更改标签文件。
with open('C:/qwer/python/mnist/txt/3or4.txt') as f:
labels = ["三角形","四边形"]
_, predicted_idx = output.max(1)
predicted_label = labels[predicted_idx]
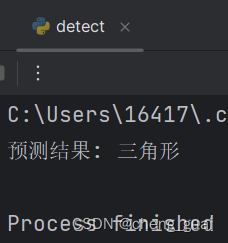
print(f'预测结果: {predicted_label}')测试结果
分别传入一个三角形和四边形的图片,可以看到识别成功了,但是由于模型较小,自己制作的数据集太小等问题精确度还是有所不足,在多次测试中还是会出现识别错误的情况。


















 5860
5860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









