







G.-B. Huang, Q.-Y. Zhu and C.-K. Siew, “Extreme Learning Machine: Theory and Applications”, Neurocomputing, vol. 70, pp. 489-501, 2006.
SLFN :单隐层前馈神经网络
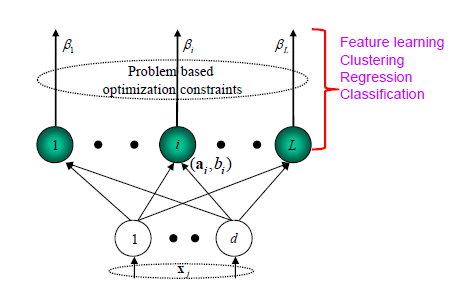
SLFN 应该是含有隐层节点中最简单地神经网络了。
以SLFN为例,传统的神经网络训练方法:
- 初始化参数(输入层到隐层的权重与偏置,隐层到输出层的权重与偏置)
- 计算输出层误差并反向传播,迭代直至误差满足要求
BP算法利用迭代的思路将误差逐步降低,然而迭代率过低则训练速度慢,迭代率过大则无法收敛,系统不够稳定。以致于现在深度学习的炫酷效果都是实验室团队常年累月的调参数得来的,是否真的属于机器的智能不得而知。
在ELM模型理论中,提出的问题是,这些权重真的需要进行不断地迭进行求解吗?然后它给出了一个更加狂拽炫酷的思路:从输入层到隐层的权重根本不需要进行迭代优化,随机赋值即可!。并在论文中给出了严格的数学证明。
输入层到隐层权重随机赋值后,便将原来的多层网络转化成为一个线性系统,用最小二乘进行矩阵求解就可以了。
最后贴出超限学习机的算法思路:

这该是本年度见过最美的论文了。















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









