






List:有序
ArrayList:底层基于可变数组实现,实现List接口,允许null;非同步
Object[] elementData;
DEFAULT_CAPACITY = 10;
MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
该集合是可变长度数组,数组扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量增长大约是其容量的1.5倍,这种操作的代价很高;
int newCapacity = oldCapacity + (oldCapacity >> 1);
Arrays.copyOf(elementData, newCapacity);
采用了Fail-Fast机制,面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险?
LinkedList:基于双链表实现,实现了List接口,允许null。非同步
双向链表节点对应的类Node的实例,Node中包含成员变量:prev,next,item
Node<E>;
E item;值
Node<E> next;下一节点
Node<E> prev;上一节点
Map:无序
HashMap:基于哈希表的Map接口的实现,非同步,允许null 键值。
http://blog.csdn.net/wushiwude/article/details/75331926 参考资料
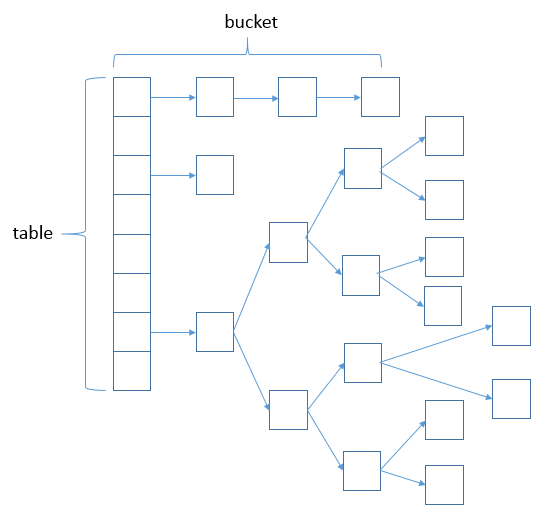
底层实现是数组,数组中每一项是单向链表,即数组+链表结合;当链表长度达到一定阈值时(长度超过8),链表转化为红黑树,节省链表查询时间(JDK1.8)。
当需要存储一个Node对象时,会根据key的hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Node时,也会根据key的hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Node。
HashMap进行数组扩容需要重新计算扩容后每个元素在数组中的位置,很耗性能。
采用了Fail-Fast机制,通过一个modCount值记录修改次数,对HashMap内容的修改都将增加这个值。迭代器初始化过程中会将这个值赋给迭代器的expectedModCount,在迭代过程中,判断modCount跟expectedModCount是否相等,如果不相等就表示已经有其他线程修改了Map,马上抛出异常。
DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
MAXIMUM_CAPACITY = 1 << 30;
DEFAULT_LOAD_FACTOR = 0.75f;
Entry<?,?>[] EMPTY_TABLE = {};
resize(2 * table.length);
ConcurrentHashMap:允许多个修改操作并发进行,其关键在于使用了锁分离技术。
Segment是什么呢?Segment本身就相当于一个HashMap对象。
同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。像这样的Segment对象,在ConcurrentHashMap集合中有多少个呢?有2的N次方个,共同保存在一个名为segments的数组当中。
Segment<K,V>[] segments;
HashEntry<K,V>[] table;
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
延伸知识:数据结构(数组 链表 单链表 双链表)
如何让数据均匀的分布在每个桶中,hashMap,ConcurrentHashMap??
HashMap Hashtable 的区别
继承的父类不同
线程安全性不同(HashMap为什么是线程不安全??)
HashMap底层是一个Entry数组,当发生hash冲突的时候,hashmap是采用链表的方式来解决的,在对应的数组位置存放链表的头结点。对链表而言,新加入的节点会从头结点加入。
put:在hashmap做put操作的时候会调用到以上的方法。现在假如A线程和B线程同时对同一个数组位置调用addEntry,两个线程会同时得到现在的头结点,然后A写入新的头结点之后,B也写入新的头结点,那B的写入操作就会覆盖A的写入操作造成A的写入操作丢失。
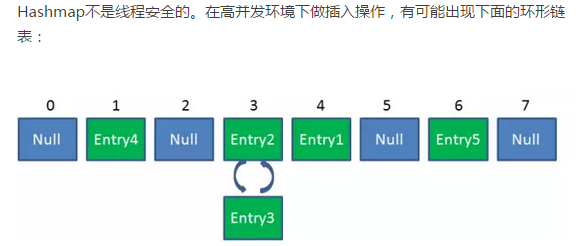
resize:当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。
remove:
key和value是否允许null值
Hashtable中,key和value都不允许出现null值。
但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,
因为key和value都是Object类型,但运行时会抛出NullPointerException异常,
这是JDK的规范规定的
两个遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用 了Enumeration的方式 。
hash值不同
hashtable =hashSeed ^ k.hashCode();
内部实现使用的数组初始化和扩容方式不同
hashtable 长度默认11,resize= 2*old+1















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









