






安装指南
环境
麒麟需要正确设置Hadoop环境下运行。下面是运行麒麟的最小要求,更多的细节,请查看Hadoop环境。
最常见的是在Hadoop的客户机安装的麒麟,麒麟可以通过命令行包括Hive,HBase,Hadoop Hadoop集群的说话,
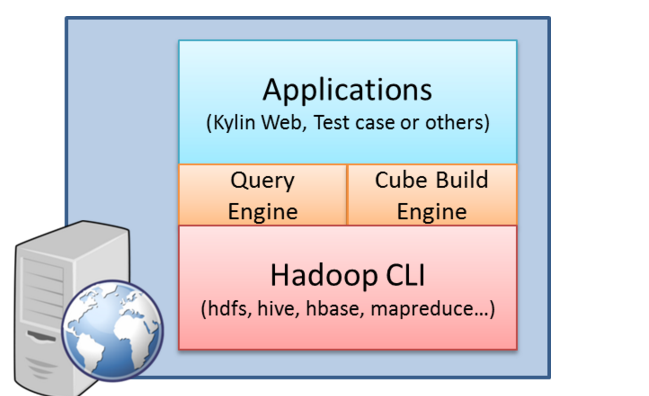
正常使用情况下,上图中的应用意味着麒麟网,其中包含一个多维数据集构建Web界面、查询和各种管理。麒麟网推出的搜索引擎查询和多维数据集的构建多维数据集生成引擎。这两个引擎和Hadoop的组件之间的交互,如Hive和HBase。
除了一些必要的软件的安装,麒麟安装的核心是通过运行一个脚本来完成。运行该脚本后,您将能够生成示例多维数据集,并通过一个统一的网络接口在多维数据集后面查询表
安装麒麟
在http://kylin.apache.org/download下载最新麒麟双星
import kylin_home指着麒麟文件夹中
确保用户的特权来运行Hadoop,Hive和HBase cmd壳。如果你不知道,你可以运行
./bin/check-env.sh,它将打印的详细信息,如果您有一些环境问题。
开始麒麟,运行./bin/kylin.sh start,服务器启动后,你可以看日志/ kylin.log运行日志;
停止麒麟 ./bin/kylin.sh stop运行
如果你想有多个麒麟节点运行提供高可用性,请参阅本
http://kylin.apache.org/docs15/install/kylin_cluster.html
翻译自 http://kylin.apache.org/docs15/install/index.html















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









