







2021常见面试题汇总
1.Valatile的定义和使用?
1.保持变量在不同线程之间的可见性
2.放在指令重排序(有序性)
1.1 可见性
在这之前我们要大致了解一下java的内存模型
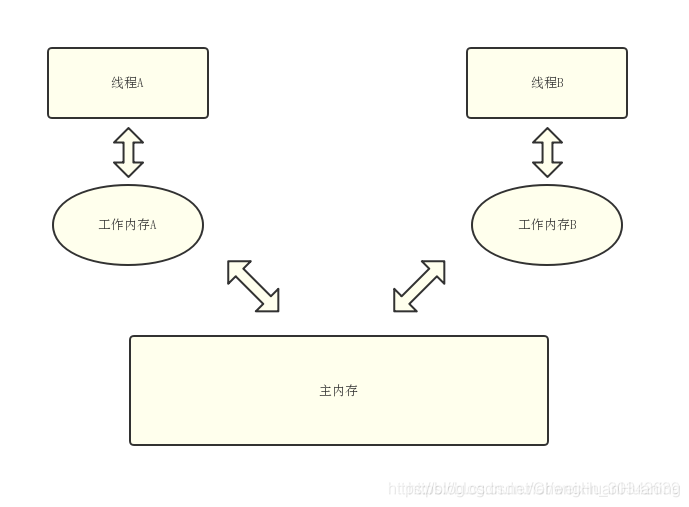
每一个线程都会有一个独立的工作内存,线程不会直接操作主内存中的变量。而是将主内存的变量存一份副本在自己线程中的工作内存中,只会操作自己工作内存中的变量,修改完毕后再将修改后的结果存入主内存中。
在上述流程中在单线程中不会存中问题,在多线程中可能出现脏数据的问题,两个线程都拿到了主内存的数据都进行了操作,导致了数据错误。
所以Valatile的第一个作用就是: 自己在工作内存中如果修改了valatile修饰的变量,那么会直接刷新到主内存中且其他工作内存中的该变量都直接失效,需要强制重新从主内存中拉取,这样来保证可见性。
1.2 有序性
排序。比方说下面的代码:
int i = 1;
int j = 2;
上述的两条赋值语句在同一个线程之中,根据程序上的次序,“int i = 1;”的操作要先行发生于“int j = 2;”,但是“int j = 2;”的代码完全可能会被处理器先执行。JVM会保证在单线程的情况下,重排序后的执行结果会和重排序之前的结果一致。但是在多线程的场景下就不一定了。最典型的例子就是双重检查加锁版的单例实现,代码如下所示:
public class Singleton {
private volatile static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
由上可以看到,instance变量被volatile关键字所修饰,但是如果去掉该关键字,就不能保证该代码执行的正确性。这是因为“instance = new Singleton();”这行代码并不是原子操作,其在JVM中被分为如下三个阶段执行:
- 为instance分配内存
- 初始化instance
- 将instance变量指向分配的内存空间
由于JVM可能存在重排序,上述的二三步骤没有依赖的关系,可能会出现先执行第三步,后执行第二步的情况。也就是说可能会出现instance变量还没初始化完成,其他线程就已经判断了该变量值不为null,结果返回了一个没有初始化完成的半成品的情况。
volatile的第二个作用而加上volatile关键字修饰后,可以保证instance变量的操作不会被JVM所重排序,每个线程都是按照上述一二三的步骤顺序的执行,这样就不会出现问题。
本段转载于:https://blog.csdn.net/weixin_30342639/article/details/91356608
2.syc1.8之后有什么区别

简单来说:
1.对象创建出来是无锁;
2.第一个线程访问它,就变成偏向锁
3.再有其他线程来访问,就有了竞争,升级为cas;
4.cas转几次,说明竞争比较激烈,升级为重量级锁。
整个过程是单向的不可逆

具体请看:Synchronized底层实现
3.synchronized和Lock的区别
-
synchronized是关键字,是JVM层面的底层啥都帮我们做了,而Lock是一个接口,是JDK层面的有丰富的API。
-
synchronized会自动释放锁,而Lock必须手动释放锁。
-
synchronized是不可中断的,Lock可以中断也可以不中断。
-
通过Lock可以知道线程有没有拿到锁,而synchronized不能。
-
synchronized能锁住方法和代码块,而Lock只能锁住代码块。
-
Lock可以使用读锁提高多线程读效率。
-
synchronized是非公平锁,ReentrantLock可以控制是否是公平锁。
4.redis如何进行大key或value值删除
1个大小200MB的String键(String Object最大512MB),内存空间占用较大;1个包含100000000(1kw)个字段的Hash键,对应访问模式(如hgetall)时间复杂度高
我们一般来说前一种内存占用大的不太会影响我们的删除效率,但后一种的时间复杂度较高的情况下,我们在删除的时候会阻塞我们redis数十秒(单线程)。
解决方式:
1.尽量不要存储这种大建,删除时会造成程序阻塞
2.通过scan命令来进行分段删除,比如每次500个key值
3.Redis 3.4版本开始,Redis会支持lazy delete free的方式,删除大键的过程不会阻塞正常请求。就是使用UNLINK,UNLINK其实是直接返回,然后在后台线程慢慢删除
(lazy free的本质就是把某些cost(主要时间复制度,占用主线程cpu时间片)较高删除操作,从redis主线程剥离,让bio子线程来处理,极大地减少主线阻塞时间。从而减少删除导致性能和稳定性问题。)
5.redis如何进行模糊搜索
含有两个参数:scan、keys都可以进行模糊搜索。
5.1使用keys进行模糊搜索
redis中有三个通配符 * ?[]
- *: 通配任意多个字符
- ?: 通配单个字符
- []: 通配括号内的某1个字符
存在问题:在模糊遍历查找期间,造成无法接受其他的get,set请求,造成缓存服务不可用
5.2使用scan进行模糊搜索
对比KEYS命令,虽然SCAN无法一次性返回所有匹配结果,但是却规避了阻塞系统这个高风险,从而也让一些操作可以放在主节点上执行。
命令:SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
scan提供4个参数,第一个是 cursor 整数值,第二个是 key 的正则模式,第三个是遍历的 limit hint。第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束














 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









