






01.计算机的五大核心组件

寄存器只负责存储运算相关的数据,断点后数据会丢失,因此,还需要IO外设,作为辅助存储设备。
02.系统设定
默认输入设备: 标准输入STDIN默认为键盘,文件描述符为0;
默认输出设备:标准输出STDOUT 默认为显示器,文件描述符为1;
标准错误输出:STDERR,默认也为显示器,文件描述符为2。
03.IO重定向
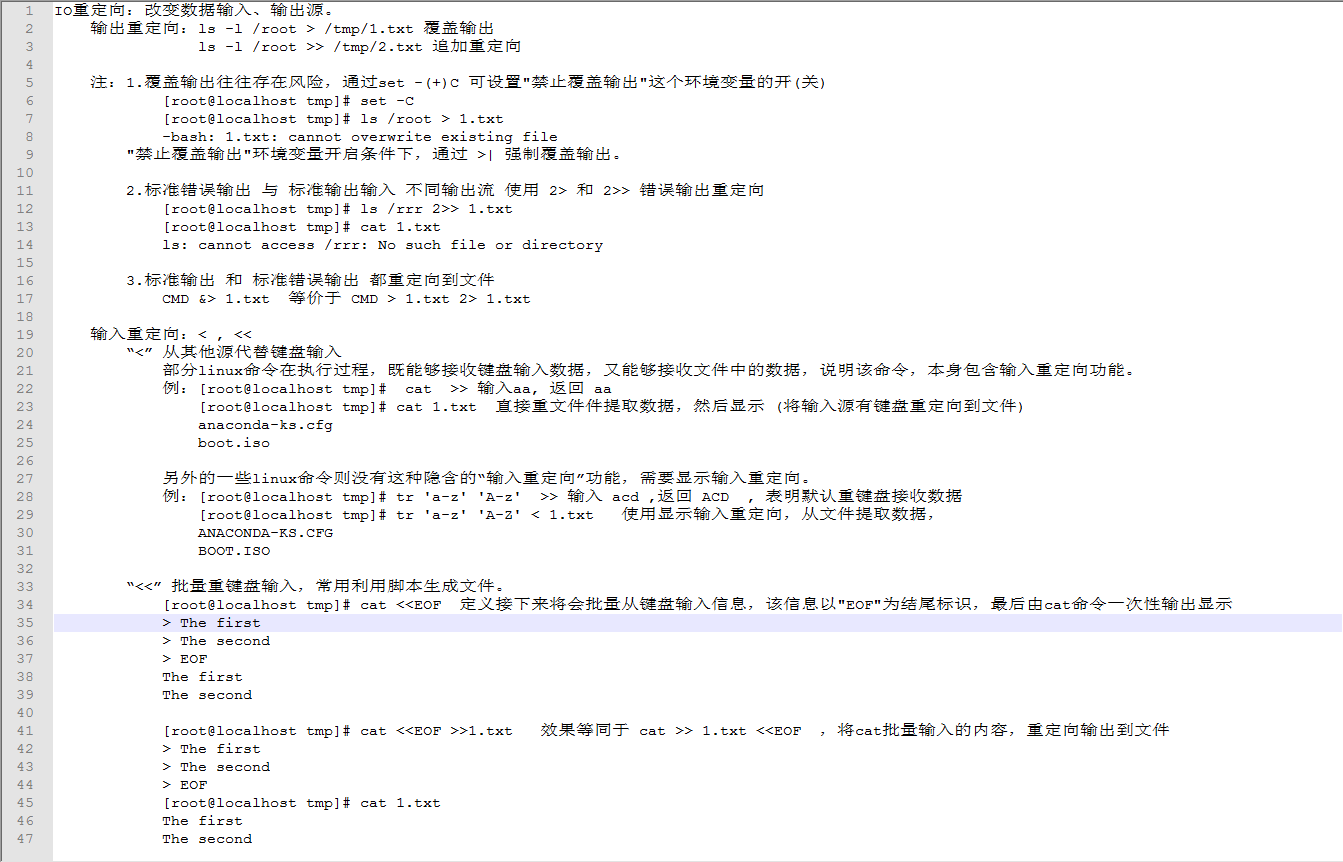
IO重定向:改变数据输入、输出源。
输出重定向:ls -l /root > /tmp/1.txt 覆盖输出
ls -l /root >> /tmp/2.txt 追加重定向
注:1.覆盖输出往往存在风险,通过set -(+)C 可设置"禁止覆盖输出"这个环境变量的开(关)
[root@localhost tmp]# set -C
[root@localhost tmp]# ls /root > 1.txt
-bash: 1.txt: cannot overwrite existing file
"禁止覆盖输出"环境变量开启条件下,通过 >| 强制覆盖输出。
2.标准错误输出 与 标准输出输入 不同输出流 使用 2> 和 2>> 错误输出重定向
[root@localhost tmp]# ls /rrr 2>> 1.txt
[root@localhost tmp]# cat 1.txt
ls: cannot access /rrr: No such file or directory
3.标准输出 和 标准错误输出 都重定向到文件
CMD &> 1.txt 等价于 CMD > 1.txt 2> 1.txt
输入重定向:< , <<
“<” 从其他源代替键盘输入
部分linux命令在执行过程,既能够接收键盘输入数据,又能够接收文件中的数据,说明该命令,本身包含输入重定向功能。
例:[root@localhost tmp]# cat >> 输入aa, 返回 aa
[root@localhost tmp]# cat 1.txt 直接重文件件提取数据,然后显示 (将输入源有键盘重定向到文件)
anaconda-ks.cfg
boot.iso
另外的一些linux命令则没有这种隐含的“输入重定向”功能,需要显示输入重定向。
例:[root@localhost tmp]# tr 'a-z' 'A-z' >> 输入 acd ,返回 ACD , 表明默认重键盘接收数据
[root@localhost tmp]# tr 'a-z' 'A-Z' < 1.txt 使用显示输入重定向,从文件提取数据,
ANACONDA-KS.CFG
BOOT.ISO
“<<” 批量重键盘输入,常用利用脚本生成文件。
[root@localhost tmp]# cat <<EOF 定义接下来将会批量从键盘输入信息,该信息以"EOF"为结尾标识,最后由cat命令一次性输出显示
> The first
> The second
> EOF
The first
The second
[root@localhost tmp]# cat <<EOF >>1.txt 效果等同于 cat >> 1.txt <<EOF ,将cat批量输入的内容,重定向输出到文件
> The first
> The second
> EOF
[root@localhost tmp]# cat 1.txt
The first
The second04.管道
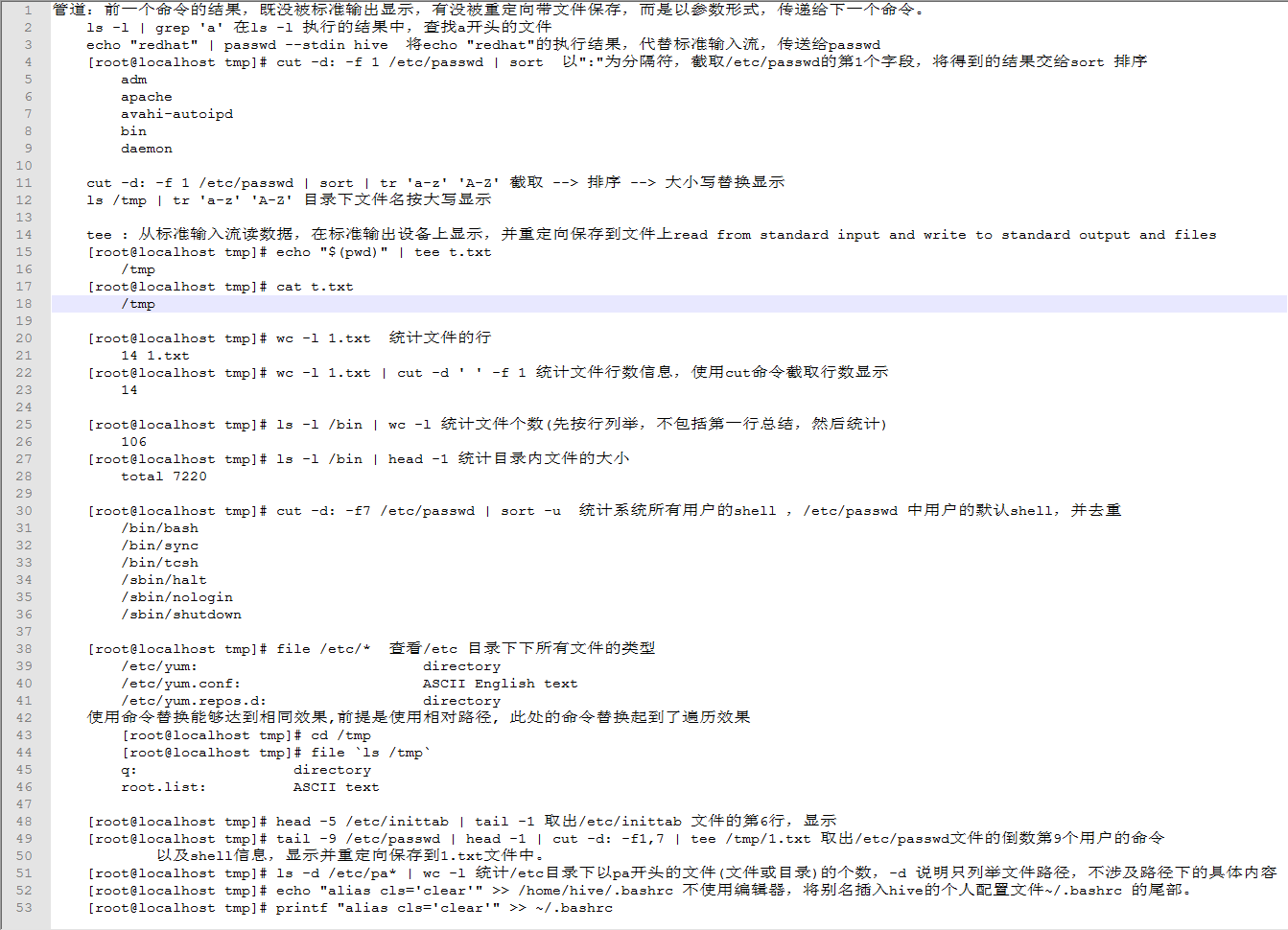
管道:前一个命令的结果,既没被标准输出显示,有没被重定向带文件保存,而是以参数形式,传递给下一个命令。
ls -l | grep 'a' 在ls -l 执行的结果中,查找a开头的文件
echo "redhat" | passwd --stdin hive 将echo "redhat"的执行结果,代替标准输入流,传送给passwd
[root@localhost tmp]# cut -d: -f 1 /etc/passwd | sort 以":"为分隔符,截取/etc/passwd的第1个字段,将得到的结果交给sort 排序
adm
apache
avahi-autoipd
bin
daemon
cut -d: -f 1 /etc/passwd | sort | tr 'a-z' 'A-Z' 截取 --> 排序 --> 大小写替换显示
ls /tmp | tr 'a-z' 'A-Z' 目录下文件名按大写显示
tee : 从标准输入流读数据,在标准输出设备上显示,并重定向保存到文件上read from standard input and write to standard output and files
[root@localhost tmp]# echo "$(pwd)" | tee t.txt
/tmp
[root@localhost tmp]# cat t.txt
/tmp
[root@localhost tmp]# wc -l 1.txt 统计文件的行
14 1.txt
[root@localhost tmp]# wc -l 1.txt | cut -d ' ' -f 1 统计文件行数信息,使用cut命令截取行数显示
14
[root@localhost tmp]# ls -l /bin | wc -l 统计文件个数(先按行列举,不包括第一行总结,然后统计)
106
[root@localhost tmp]# ls -l /bin | head -1 统计目录内文件的大小
total 7220
[root@localhost tmp]# cut -d: -f7 /etc/passwd | sort -u 统计系统所有用户的shell ,/etc/passwd 中用户的默认shell,并去重
/bin/bash
/bin/sync
/bin/tcsh
/sbin/halt
/sbin/nologin
/sbin/shutdown
[root@localhost tmp]# file /etc/* 查看/etc 目录下下所有文件的类型
/etc/yum: directory
/etc/yum.conf: ASCII English text
/etc/yum.repos.d: directory
使用命令替换能够达到相同效果,前提是使用相对路径, 此处的命令替换起到了遍历效果
[root@localhost tmp]# cd /tmp
[root@localhost tmp]# file `ls /tmp`
q: directory
root.list: ASCII text
[root@localhost tmp]# head -5 /etc/inittab | tail -1 取出/etc/inittab 文件的第6行,显示
[root@localhost tmp]# tail -9 /etc/passwd | head -1 | cut -d: -f1,7 | tee /tmp/1.txt 取出/etc/passwd文件的倒数第9个用户的命令
以及shell信息,显示并重定向保存到1.txt文件中。
[root@localhost tmp]# ls -d /etc/pa* | wc -l 统计/etc目录下以pa开头的文件(文件或目录)的个数,-d 说明只列举文件路径,不涉及路径下的具体内容
[root@localhost tmp]# echo "alias cls='clear'" >> /home/hive/.bashrc 不使用编辑器,将别名插入hive的个人配置文件~/.bashrc 的尾部。
[root@localhost tmp]# printf "alias cls='clear'" >> ~/.bashrc05.grep 与 正则表达

grep,egrep,fgrep
grep [OPTIONS] PATTERN [FILE...] :根据模式检索文本,并将符合条件文本列举显示。
Pattern:文本字符和正则表达式元字符组合点的匹配条件
File:执行匹配查找的数据源,可以是一个文件,或通过管道输送过来的数据源。
例: grep 'a' /etc/passwd 查看passwd文件中包含‘a’的行 。'^a' 以a开头,'a$' 以a 结尾;
ls /tmp | grep '^a' 查找tmp 路径下以‘a’ 开头命名的文件。
-i 忽略大小写查找匹配的行 grep -i '^a' /tmp/1.txt
--color 将匹配的内容带颜色输出 grep --color /tmp/1.txt
-v 将匹配的过滤掉,只保留不匹配的 grep -v /tmp/1.txt
-o 只显示各行首次被匹配到的字符串,通行以后被匹配的不考虑 grep -o 'a' /tmp/1.txt
linux中的引号:1).单引号表强引用,常用于声明匹配模式;2).双引号为弱引用,常用于引用字符串;3).反引号``,命令替换功能$()。
单引号与双引号一般可通用。
通配符
* 任意长度任意字符串
?单个任意字符串
[..] 指定范围内 [0-9] [a-z] [a-zA-Z]
[^..] 指定范围外
[:punct:] 标点符号
[:digit:] 数字,不是数值
[:lower:] [:upper:] 大,小写字母
[:alnum:] 数字 + 字母
[:blank:] 空白字符集
[:space:] 空格字符集
注: 以上[] 仅表示集合,外面再套一层[],才能表示范围。[[:digit:]] 0-9 ,[[:digit:]]\{1,\} 任意数值。
正则表达式:REGular EXPression(REGEXP)默认工作在“贪婪模式”下,尽可能长匹配。
元字符
(次数)
. 任意字符 grep 'a..b' /tmp/1.txt 查找包含a??b 格式字符串,没匹配n个,就自动切除,继续向下匹配 (aabbabbb只能匹配 aabb 和 abbb)
* 匹配其前面出现字符的任意次 grep 'a*b' /tmp/1.txt {c,cb,[b,ab,aab],acb,cba} b前紧随出现0~n个连续的a
.* 任意长度的任意字符 grep 'a.*b' grep /tmp/1.txt {c,cb,b,[ab,aab,acb,acbdcb],cba} a 开头,b结束,中间任意个任意字符。
\? 匹配其前面字符最多一次, grep 'a\?b' grep /tmp/1.txt
\{m,n\} 匹配前面出现的字符,连续出现至少m次,至多n次 "\" 转义符,防止{,} 被shell解析为命令行展开 grep 'ab\{1,3\}b' /tmp/1.txt
\{1,\} 至少1次 , \{,3\} 至多3次 ,
grep 'a.\{1,3\}b' ./1.txt a与b间出现任意1~3个字符
(位置锚定)
^ 锚定行首,其后面的字符串必须出现在行首,grep '^r..t' ./1.txt
$ 锚定行尾,其前面的字符串必须出现在行尾,grep 'r..t$' ./1.txt
grep '^b..' ./1.txt | grep 'n$' 以 b.. 开头,n结尾的行
grep '[[:digit:]]$' ./1.txt 以任意数字结尾
grep '[[:digit:]]\{1,\}$' ./1.txt 以任意数值结尾
grep '[[:space:]][[:digit:]]\{1,\}$' ./1.txt 以空白符+数值 结尾的行
^$ 锚定空白行,空白行,grep '^$' ./1.txt | wc -l 统计空白行数
\< 锚定词首,后面出现的内容必须是单词的开头 grep '\<roo' ./1.txt 以 roo 开头的单词 croot ,roo:: 等效于 grep '\broo' ./1.txt
\> 锚定此为,前面的内容必须是单词的结尾 grep 'roo\>' ./1.txt 以roo 结尾 ,等效于 grep 'roo\b' ./1.txt
grep '\<roo\>' ./1.txt 出现单词 roo 的位置,以roo开头和结尾 等效于 grep '\broo\b' ./1.txt
分组
\(ab\)* 将ab 看成整体,其可连续出现任意次 grep '\(ab\)' ./1.txt ab 连续出现任意次(不出现也显示)
ab*则标识a后面紧跟若干连续的b
\1 引用字符串最外层构成的一对括号内容 \(a\(b\)c\(d\)e\) --> a\(b\)c\(d\)e
\2 引用第二层 \(a\(b\)c\(d\)e\) --> b\)c\(d
He like his liker. He like his liker.
She love her lover. grep '\(l..e\).*\1r' She love her lover.
He like her. --------------------->
She love her liker.
grep '\([0-9]\).*\1$' ./1.txt 行中包含任意数字,中间隔至少1个任意字符,并且以该数字结尾的行
分类
Basic REGEXP基本正则表达式
(内容)
. 任意一个字符
[abc] 指定范围内
[^abc] 指定范围外
(次数)
* 前跟字符连续出现0~n次
\? 前跟字符最多出现1次
\{m,n\} 前跟字符连续出现m~n次
.* 任意长度字符串
(位置)
^ 以后跟字符串开头
$ 以前跟字符串结尾
\< 或 \b 单词以后跟字符串开头
\> 或 \b 单词以前跟字符串结尾
\<str\> 某个单词
(组合)
\(pattern\)
\(pattern\)\1\2\n 组合复用
grep 只能使用基本正则表达式定义过滤文本的模式
-i 忽略大小
-v 排除匹配的,取反
-o 只显示匹配的内容
--color 将所有匹配内容上色显示
-E 使用扩展的正则表达式
-A num (After)显示首次成功匹配行以及接下来的num行,例:grep -A 2 '^core id' /proc/cpuinfo 显示 以 "core id" 开头和往下2行
-B num (Before)显示首次成功匹配行以及往上来的num行,例:grep -B 2 '^core id' /proc/cpuinfo 显示 以 "core id" 开头和往上2行
-C num (Context)显示首次成功匹配行以及上下各num行,例:grep -C 2 '^core id' /proc/cpuinfo 显示 以 "core id" 开头上下各2行
Extended REGEXP 扩展正则表达式
(内容)
. 任意一个字符
[abc] 指定范围内
[^abc] 指定范围外
(次数)
* 前跟字符连续0~n次
? 前跟字符最多出现1次 grep -E 'a?b' 1.txt b前最多出现一个a
+ 前跟字符至少1次 grep -E 'a+b' 1.txt b前至少一个a grep -E '^[[:space:]]+' /boot/grup/grup.conf 至少一个空白符开头
{m,n} 前跟字符允许出现m~n次, grep -E 'a{2,3}b' 1.txt b前最多3个最少2个a
{m} 前跟字符连续出现m次
(){m} 前跟模式连续出现m次
(位置)
^ 以后跟字符串开头的行
$ 以前跟字符串结尾的行
\< 以后跟字符串开头的单词
\> 以前跟字符串结尾的单词
\<xyz\> 某单词
(分组)
{abc}* abc看成整体 连续出现0~n次
{abc}.* abc出现看成整体后跟任意字符串
{l..e}.*\1r l..e 类型看成整体,后跟任意字符串,然后再次引用前面的内容并带上r
{a..b.*{c..d}}.*\1A.*\2B \1引用的四最外层的内容,\2 引用次外层的内容
grep -E '{l..e}.*\1r' 2.txt
或者
Left|Right 左或右 grep -E 'C|cat' 1.txt 以 包含C 或 cat的
fgrep : fast grep 快速匹配检索,不支持正则匹配(即,不支持元字符,通配符),匹配查找。效率比grep ,egrep 高。06.Tips

1) grep '[[:digit:]]\{1,2\}' /etc/inittab grep -E '[[:digit:]]{1,2}' /etc/inittab 出现1位或2为数
2) ifconfig | egrep '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>' 必须使用() 否则只能锚定部分,1~255的数值
3) ifconfig | egrep --color -o '(\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.){3}\<([0-9]|[1-9][0-9]|[1][0-9][0-9]|2[0-4][0-9]|25[0-5])\>'
统计全部[0~255].[0~255],[0~255].[0~255] 格式的字符串内容
IPV4地址分类:A,B,C,D,E.
1.只有ABC 是可用的,D用于广播,E是实验使用;
2.ABC 地址的第2,3网段取值在[0-254],第4网段在[1-254],唯一区别在第1端
A 类:1-127 ; B 类:128-191 ; C 类:192-223
ifconfig 命令结果中的可用IP地址表示为
ifconfig | egrep --color '\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[01][0-9]|22[0-3])\>\.(\<([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-4])\>\.){2}\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-4])\>'
--------------第一段 [1-223] 不包括"."--------------
--------第2,3 段 [0-254] 包括"." 重复2次----------------
---------------------第4段[1-254]-------------------
4) echo "Current User ID:` grep '^student' /etc/passwd | cut -d: -f3`" 当前用户的ID 等效于 echo "$(id -u)"















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









