






理解输出各个列的含义

id:每个select子句的标识id
select_type:select语句的类型
table:当前表名
显示查询将访问的分区,如果你的查询是基于分区表
type:当前表内访问方式
possible_keys:可能使用到的索引
key:经过优化器评估最终使用的索引
key_length:使用到的索引长度
ref:引用到的上一个表的列
rows:rows_examined,要得到最终记录索要扫描经过的记录数
filtered:表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
Extra:额外的信息说明
Type的相关知识点:
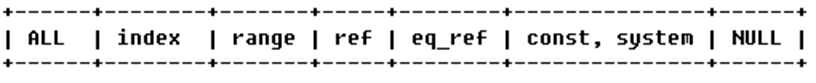
由左至右,性能由最差到最好
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index:Full Index Scan,index与ALL区别为index类型只遍历索引树
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。常见于使用非唯一索引即唯一索引的非唯一前缀进行的查找
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量
NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引
Extra的相关知识点:
Using temporary
表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询
Using filesort
MySQL中无法利用索引完成的排序操作称为“文件排序”
Using Index
表示直接访问索引就能够获取到所需要的数据(覆盖索引),不需要通过索引回表;
覆盖索引: 如果一个索引包含(或者说覆盖)所有需要查询的字段的值。我们称之为“覆盖索引”。如果索引的叶子节点中已经包含要查询的数据,那么还有什么必要再回表查询呢?
Using Index Condition
在MySQL 5.6版本后加入的新特性(Index Condition Pushdown);会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
Using where
表示MySQL服务器在存储引擎收到记录后进行“后过滤”(Post-filter),如果查询未能使用索引,Using where的作用只是提醒我们MySQL将用where子句来过滤结果集。这个一般发生在MySQL服务器,而不是存储引擎层。一般发生在不能走索引扫描的情况下或者走索引扫描,但是有些查询条件不在索引当中的情况下。
下面我们通过实验来测试、验证一下,并加深一下我们对这些概念的理解,测试环境数据库为Sakila, 首先使用下面脚本准备测试环境:
CREATE TABLE TEST(
i1 INT NOT NULL DEFAULT 0,
i2 INT NOT NULL DEFAULT 0,
d DATE DEFAULT NULL,
f INT default 0,
PRIMARY KEY (i1, i2)
) ENGINE = InnoDB;
INSERT INTO TEST VALUES
(1, 1, '1998-01-01',1), (1, 2, '1999-01-01',2),
(1, 3, '2000-01-01',1), (1, 4, '2001-01-01',2),
(1, 5, '2002-01-01',1), (2, 1, '1998-01-01',2),
(2, 2, '1999-01-01',1), (2, 3, '2000-01-01',2),
(2, 4, '2001-01-01',1), (2, 5, '2002-01-01',2),
(3, 1, '1998-01-01',1), (3, 2, '1999-01-01',2),
(3, 3, '2000-01-01',1), (3, 4, '2001-01-01',2),
(3, 5, '2002-01-01',1), (4, 1, '1998-01-01',2),
(4, 2, '1999-01-01',1), (4, 3, '2000-01-01',2),
(4, 4, '2001-01-01',1), (4, 5, '2002-01-01',2),
(5, 1, '1998-01-01',1), (5, 2, '1999-01-01',2),
(5, 3, '2000-01-01',1), (5, 4, '2001-01-01',2),
(5, 5, '2002-01-01',1);
Extra中为Using where的情况
Extra中出现“Using where”,通常来说,意味着全表扫描或者在查找使用索引的情况下,但是还有查询条件不在索引字段当中。具体来说有很多种情况,下面简单罗列一下测试过程中遇到的各种情况(部分案例)。
1: 查询条件中的相关列,不是索引字段, 全表扫描后,通过Using where过滤获取所需的数据。
通俗来说,因为字段D没有索引,所以必须全表扫描,然后在服务器层使用WHERE过滤数据。
mysql> EXPLAIN
-> SELECT COUNT(*) FROM TEST WHERE D = '2000-01-01';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | TEST | ALL | NULL | NULL | NULL | NULL | 25 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
2: (type=ref)非唯一性索引扫描,但是由于索引未覆盖所有查询条件(字段d并未包含在聚集索引PRIMARY中),在存储引擎返回记录后,仍然需要过滤数据(排除d != '2000-01-01'的数据)。
mysql> EXPLAIN
-> SELECT COUNT(*) FROM TEST WHERE i1 = 3 AND d = '2000-01-01';
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | TEST | ref | PRIMARY | PRIMARY | 4 | const | 5 | Using where |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql>
mysql> EXPLAIN
-> SELECT * FROM TEST WHERE i1 = 3 AND d = '2000-01-01';
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | TEST | ref | PRIMARY | PRIMARY | 4 | const | 5 | Using where |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql>
mysql> EXPLAIN
-> SELECT COUNT(i1) FROM TEST WHERE i1 = 3 AND d = '2000-01-01';
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | TEST | ref | PRIMARY | PRIMARY | 4 | const | 5 | Using where |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql>
这里即使在存储引擎层进行非唯一性索引扫描,但是索引扫描过程中,只是过滤获取i1=3的行记录,相关记录返回MySQL服务器后,还需要对记录进行过滤,只返回d = '2000-01-01'的记录。简单来说,索引无法过滤掉无效的行。如下所示i1=3的记录有5条,但是i1 = 3 AND d = '2000-01-01'的记录只有一条。如下所示:
mysql> SELECT * FROM TEST WHERE i1 = 3 ;
+----+----+------------+------+
| i1 | i2 | d | f |
+----+----+------------+------+
| 3 | 1 | 1998-01-01 | 1 |
| 3 | 2 | 1999-01-01 | 2 |
| 3 | 3 | 2000-01-01 | 1 |
| 3 | 4 | 2001-01-01 | 2 |
| 3 | 5 | 2002-01-01 | 1 |
+----+----+------------+------+
5 rows in set (0.00 sec)
mysql> SELECT * FROM TEST WHERE i1 = 3 AND d = '2000-01-01';
+----+----+------------+------+
| i1 | i2 | d | f |
+----+----+------------+------+
| 3 | 3 | 2000-01-01 | 1 |
+----+----+------------+------+
1 row in set (0.00 sec)
mysql>
3:WHERE筛选条件不是索引的前导列,导致不走索引,而走全表扫描。
其实此处是因为WHERE中的刷选条件不是索引的前导列,所以执行计划走全表扫描(ALL),然后在服务器层进行过滤数据。
mysql> EXPLAIN
-> SELECT COUNT(i1) FROM TEST WHERE i2=4 AND d = '2000-01-01';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | TEST | ALL | NULL | NULL | NULL | NULL | 25 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql>
注意:
Using where过滤元组和执行计划是否走全表扫描或走索引查找没有关系。如上测试所示,Using where: 仅仅表示MySQL服务器在收到存储引擎返回的记录后进行“后过滤”(Post-filter)。 不管SQL语句的执行计划是全表扫描(type=ALL)或非唯一性索引扫描(type=ref)。网上有种说法“Using where:表示优化器需要通过索引回表查询数据" ,上面实验可以证实这种说法完全不正确。
Extra中为Using index的情况
表示直接访问索引就能够获取到所需要的数据(索引覆盖),不需要通过索引回表。
注意:执行计划中的Extra列的“Using index”跟type列的“index”不要混淆。Extra列的“Using index”表示索引覆盖。而type列的“index”表示Full Index Scan。
首先,我们在表TEST上创建二级索引IX_TEST_N1
mysql> CREATE INDEX IX_TEST_N1 ON TEST(d);
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN
-> SELECT COUNT(*) FROM TEST WHERE D = '2000-01-01';
+----+-------------+-------+------+---------------+------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------------+---------+-------+------+-------------+
| 1 | SIMPLE | TEST | ref | IX_TEST_N1 | IX_TEST_N1 | 4 | const | 5 | Using index |
+----+-------------+-------+------+---------------+------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql> EXPLAIN
-> SELECT * FROM TEST WHERE D = '2000-01-01';
+----+-------------+-------+------+---------------+------------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------------+---------+-------+------+-------+
| 1 | SIMPLE | TEST | ref | IX_TEST_N1 | IX_TEST_N1 | 4 | const | 5 | NULL |
+----+-------------+-------+------+---------------+------------+---------+-------+------+-------+
1 row in set (0.00 sec)
mysql>
如上所示,上面SQL例子中,Extra为 Using index的表示覆盖索引,而不需回表。而Null则表示需要回表。
mysql> EXPLAIN
-> SELECT i1, i2 FROM TEST WHERE i1=3 AND i2=5;
+----+-------------+-------+-------+---------------+---------+---------+-------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------------+------+-------------+
| 1 | SIMPLE | TEST | const | PRIMARY | PRIMARY | 8 | const,const | 1 | Using index |
+----+-------------+-------+-------+---------------+---------+---------+-------------+------+-------------+
1 row in set (0.00 sec)
mysql> EXPLAIN
-> SELECT * FROM TEST WHERE i1=3 AND i2=5;
+----+-------------+-------+-------+---------------+---------+---------+-------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------------+------+-------+
| 1 | SIMPLE | TEST | const | PRIMARY | PRIMARY | 8 | const,const | 1 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+-------------+------+-------+
1 row in set (0.00 sec)
mysql>
Extra中为Using where; Using index的情况
下面我们关闭Index Extensions选项(具体可以参考博客MySQL索引扩展(Index Extensions)学习总结),那么二级索引(Secondary Index)就不会自动补齐主键,将主键列追加到二级索引列后面,此时,Extra则会由Using index变为Using where; Using index。如下所示
mysql> EXPLAIN
-> SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01';
+----+-------------+-------+------+---------------+------+---------+-------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-------------+------+-------------+
| 1 | SIMPLE | t1 | ref | PRIMARY,k_d | k_d | 8 | const,const | 1 | Using index |
+----+-------------+-------+------+---------------+------+---------+-------------+------+-------------+
1 row in set (0.00 sec)
mysql> SET optimizer_switch = 'use_index_extensions=off';
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN
-> SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01';
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| 1 | SIMPLE | t1 | ref | PRIMARY,k_d | k_d | 4 | const | 5 | Using where; Using index |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
1 row in set (0.00 sec)
mysql>
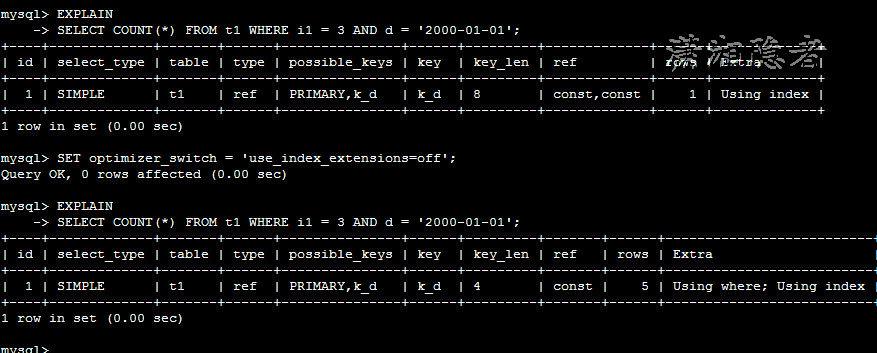
这样的细微差别,代表什么区别呢? 我们可以理解为:MySQL服务器在收到存储引擎返回i1 = 3的记录后进行“后过滤”(Post-filter),过滤返回d = '2000-01-01'的记录。另外,我们以样例数据库sakila为例, 如下所示,表rental在字段customer_id上建有二级索引idx_fk_customer_id ,下面两个SQL语句的执行计划就是Using index 与Using where; Using index的区别。
mysql> EXPLAIN SELECT customer_id FROM rental WHERE customer_id=300;
+----+-------------+--------+------+--------------------+--------------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+--------------------+--------------------+---------+-------+------+-------------+
| 1 | SIMPLE | rental | ref | idx_fk_customer_id | idx_fk_customer_id | 2 | const | 31 | Using index |
+----+-------------+--------+------+--------------------+--------------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql>
mysql> EXPLAIN SELECT customer_id FROM rental WHERE customer_id>=300;
+----+-------------+--------+-------+--------------------+--------------------+---------+------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+--------------------+--------------------+---------+------+------+--------------------------+
| 1 | SIMPLE | rental | range | idx_fk_customer_id | idx_fk_customer_id | 2 | NULL | 7910 | Using where; Using index |
+----+-------------+--------+-------+--------------------+--------------------+---------+------+------+--------------------------+
1 row in set (0.00 sec)
mysql>
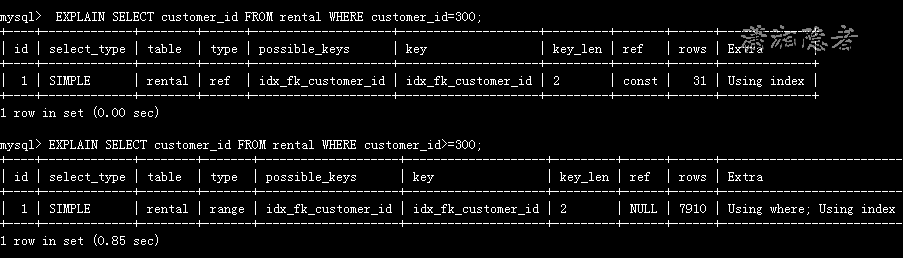
上面两个SQL语句都能满足覆盖索引的条件,但是为什么第二个SQL的执行计划是“Using where; Using index”呢? 相当长的一段时间里,即使查阅了大量关于“Using where; Using index”与“Using index”的区别的资料,但是都是雾里看花,越纠结就越糊涂。非常让人抓狂,而且始终没有弄清楚到底是啥区别:
在《高性能MySQL》的相关章节,书本里面有这样的解释:MySQL服务器在存储引擎返回行以后在应用WHERE条件过滤。
摘抄一段在此,方便各位理解:
InnoDB只有在访问行的时候才会对其加锁,而索引能够减少InnoDB访问的行数,从而减少锁的数量。但这只有当InnoDB在存储引擎层能够过滤
掉所有不需要的行时才有效,如果索引无法过滤掉无效的行,那么在InnoDB检索到数据并返回给服务器层以后, MySQL服务器才能应用WHERE子句。
这时已经无法避免锁定行了:InnoDB已经锁定了这些行,到适当的时候才释放。在MySQL 5.1和之后的版本中, InnoDB可以在服务器端过滤掉行后
就释放锁,但是在早期的MySQL版本中,InnoDB只有在事务提交后才能释放锁。
是否有人看完上面这段解释,还是有点迷惑。WHERE条件customer_id>=300 ,执行计划使索引范围扫描,对索引的扫描customer_id大于等于300的行,返回了所有匹配的值,这个已经是经过过滤后的数据了,不应该在服务器使用WHERE过滤数据啊? Why??? 直到后面看了何登成大神“SQL中的where条件,在数据库中提取与应用浅析”这篇文章,才基本上明白,MySQL对WHERE条件的分解和提取。简单点理解,就是Using where; Using index 这个表示在索引的扫描过程中,也是需要过滤数据的(Index First Key 、Index Last Key),其实表扫描和索引扫描也是很类似的。只是发生的层面不一样。个人觉得这样的解释已经是合理的,如有不对,敬请指教。
还有一个细节,就是你们会发现出现“Using where; Using index”意味着返回的记录是超过一条, 而”Using index”意味着返回单条记录,而且Type也是有所区别,从“ref"或eq_ref 到 ”range“。(这个只是简单推测,没有经过严格验证)
注意:不要把Extra列的"Using index"与type列的"index"搞混淆,其实这两者完全不同,type列和覆盖索引毫无关系,它只是表示这个查询访问数据的方式,或者说MySQL查找行的方式。
Extra中为Using index condition的情况
Extra为Using Index Condition 表示会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。Index Condition Pushdown (ICP)是MySQL 5.6 以上版本中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式。ICP开启时的执行计划含有 Using index condition 标示 ,表示优化器使用了ICP对数据访问进行优化。
关于ICP的相关资料,摘抄其它博客的两段介绍:
a 当关闭ICP时,Index仅仅是data access的一种访问方式,存储引擎通过索引回表获取的数据会传递到MySQL Server 层进行WHERE条件过滤。
b 当打开ICP时,如果部分WHERE条件能使用索引中的字段,MySQL Server 会把这部分下推到引擎层,可以利用Index过滤的WHERE条件在存储引擎层进行数据过滤,而非将所有通过Index Access的结果传递到MySQL Server层进行WHERE过滤.
优化效果:ICP能减少引擎层访问基表的次数和MySQL Server 访问存储引擎的次数,减少io次数,提高查询语句性能
ICP(index condition pushdown)是MySQL利用索引(二级索引)元组和筛字段在索引中的WHERE条件从表中提取数据记录的一种优化操作。ICP的思想是:存储引擎在访问索引的时候检查筛选字段在索引中的WHERE条件(pushed index condition,推送的索引条件),如果索引元组中的数据不满足推送的索引条件,那么就过滤掉该条数据记录。ICP(优化器)尽可能的把index condition的处理从Server层下推到Storage Engine层。Storage Engine使用索引过过滤不相关的数据,仅返回符合Index Condition条件的数据给Server层。也是说数据过滤尽可能在Storage Engine层进行,而不是返回所有数据给Server层,然后后再根据WHERE条件进行过滤。sh
下面是博客Index Condition Pushdown中的两幅插图,形象的描述了使用ICP和不使用ICP,优化器的数据访问和提取的过程。
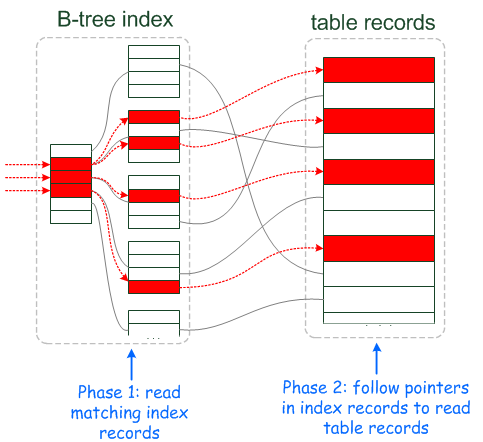
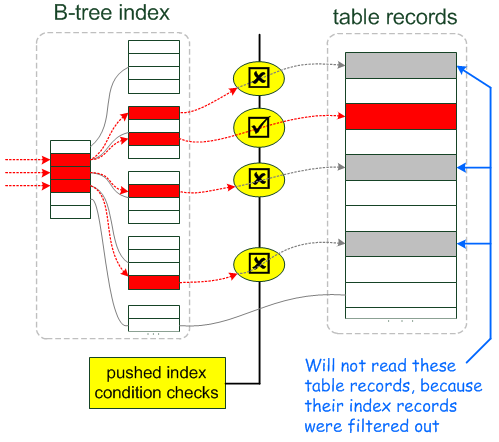
下面我们来看看案例吧,在sakila数据库的表rental上,在字段`rental_date`,`inventory_id`,`customer_id`上建有唯一索引rental_date,那么在开启ICP时,
Extra会出现Using index condition,
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.6.41 |
+-----------+
1 row in set (0.00 sec)
mysql> set optimizer_switch='index_condition_pushdown=on';
Query OK, 0 rows affected (0.00 sec)
mysql> explain
-> select * from rental
-> where rental_date = '2006-02-14 15:16:03'
-> and customer_id >= 300
-> and customer_id <= 400;
+--+-----------+------+-----+-------------------+-----------+--------+-------+------+----------------------+
|id|select_type|table| type | possible_keys | key |key_len |ref | rows | Extra |
+--+-----------+------+-----+-------------------+-----------+--------+-------+------+----------------------+
|1 |SIMPLE |rental| ref |rental_date,idx_… |rental_date| 5 | const | 181 | Using index condition
+--+-----------+------+-----+-------------------------------+--------+-------+-------+------+--------------+
1 row in set (0.00 sec)
mysql> set optimizer_switch='index_condition_pushdown=off';
Query OK, 0 rows affected (0.00 sec)
mysql> explain
-> select * from rental
-> where rental_date = '2006-02-14 15:16:03'
-> and customer_id >= 300
-> and customer_id <= 400;
+----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+
| 1 | SIMPLE | rental | ref | rental_date,idx_fk_customer_id | rental_date | 5 | const | 181 | Using where |
+----+-------------+--------+------+--------------------------------+-------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql>
ICP的一些使用限制:
1. 当SQL需要全表访问时,ICP的优化策略可用于range, ref, eq_ref, ref_or_null类型的访问数据方法 。
2. 支持InnoDB和MyISAM表。
3. ICP只能用于二级索引,不能用于主索引。
4. 并非全部WHERE条件都可以用ICP筛选,如果WHERE条件的字段不在索引列中,还是要读取整表的记录到Server端做WHERE过滤。
5. ICP的加速效果取决于在存储引擎内通过ICP筛选掉的数据的比例。
6. MySQL 5.6版本的不支持分表的ICP功能,5.7版本的开始支持。
7. 当SQL使用覆盖索引时,不支持ICP优化方法。
参考资料:
https://mariadb.com/kb/en/library/index-condition-pushdown/
http://www.cnblogs.com/gomysql/p/3657395.html
https://wenku.baidu.com/view/dab46f72f46527d3240ce065.html
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









