










 HashDB是一个简单的Key-value存储系统,提供基本的<key,value>数据存储与读取功能,适用于大数据量的去重和打包。它采用了hashtable、bloomfilter等数据结构,支持在内存与磁盘之间的数据交换。
HashDB是一个简单的Key-value存储系统,提供基本的<key,value>数据存储与读取功能,适用于大数据量的去重和打包。它采用了hashtable、bloomfilter等数据结构,支持在内存与磁盘之间的数据交换。
HASHDB:一个简单的Key-value的存储系统原型
1、HashDB是什么?
HashDB是一个简单的KeyValue存储系统原型,提供基本的<key, value>二元组的数据存储与读取功能,亦即当前被广为推崇的NoSQL存储系统。最初想到设计这个小系统,完全是出于偶然。本人维护着一个轻量级的开源重复数据删除小工具deduputil,它基于块级对文件目录进行数据去重并进行打包,支持定长和变长数据分块算法,并支持数据块压缩。deduputil使用hash数据指纹来区分和识别重复数据块,数据块指纹采用hashtable进行存储和查找,并完全置于内存中。假设,数据块平均大小为4KB,数据块对象属性描述约需40字节,则存储8TB数据的指纹大约需要80GB内存,如此庞大的内存需求使得deduputil很难工作于普通的PC或服务器。因此决定对deduputil进行重构,支持在内存有限的环境下进行大数据量的去重和打包,思想是让指纹数据在内存与磁盘之间进行交换。最初想直接采用类似Tokyo Cabinet的NoSQL系统,后来发现这些系统远远比deduputil复杂,使用它们真是大材小用,而且使得deduputil对第三方软件产生了依赖。于是产生了设计一个简单的KeyValue存储系统的念头,经过几个晚上的奋战,HashDB原型系统完成并成功应用于deduputil上,代码量不到1000行,非常非常轻量级。HashDB以较小的内存消耗达到支持超大hashtable,数据持久化存储于文件中,并在内存与文件之间进行交换。HashDB主要采用了hashtable, bloom filter, set-assocaite cache, file layout, btree等数据结构与算法,初步性能测试结果表明HashDB的性能基本还算不错,已经比较接近Tokyo Cabinet的性能。HashDB源码包含在deduputil中,可以从http://sourceforge.net/projects/deduputil/获得。
2、基本原理
HashDB以hashtable方式组织数据,桶数组长度在创建时指定,同样以后不可修改。bucket array会远远小于记录总数,一般平均桶长在10以上。通常情况下,桶中以链表方式组织产生冲突的记录,查找时遍历链表,当桶较长时顺序查找效率较低。HashDB桶中的记录采用btree结合二次hash方法来组织,这点参考了Tokyo Cabinet。Btree实现简单,查找时间复杂度为log(h),但可能会发生二叉树极度为平衡的情况,而平衡树(如RB, B*, B-, B+树)实现则较为复杂。二次hash方法,先比较hash值再比较关键字key,从而获得较为平衡的btree。实践表明,btree结合二次hash的方法非常有效,可以大大提高检索效率。Bucket array中记录中对应桶的btree根结点偏移,以它为Root可以遍历搜索整个hash桶。
Hash entries区域部分存储了所有的KeyValue记录,出于简化设计实现考虑,每个记录的大小固定,Key和Value都有最大长度限制,记录以Append方式增加,支持修改Key对应的Value值,目前没有支持删除操作。同一个桶中的记录以btree方式组织,入口地址保存在bucket array中对应桶节点中。HashDB设计了Cache系统来提升性能,缓存的记录数量通常约为总记录数的10%,这也是采纳了热点数据的常见比率。Cache管理算法采用类似计算机高速Cache的组相联(Set-associative)算法,以hash为基础进行记录的换入和换出,即同一个桶中的记录会被cache到相同的cache项中。
HashDB中,header, bloom filter, bucket array, hash entries四个部分持久化存储于文件中,运行时header, bloom filter, bucket array完全缓存在内存中,cache则仅在运行时存在,这部分内存空间消耗是可以估算的。假设,总记录数tnum=1000万,hash桶数bnum=100万,缓存记录数量cnum=100万,每条记录固定大小为1KB,则内存消耗=1000万/8 + 100万*8 + 100万*1KB = 1.25MB + 8MB + 1GB。HashDB加载时,header, bloom filter, bucket array将从文件中读取并载入内存,并读取每个hash桶的第一个记录对cache进行预热。HashDB关闭时,内存中的所有脏数据将被写回文件,记录数庞大时,这个过程会比较耗时。
HashDB目前还是一个很简单的原型系统,没有提供锁机制,只能应用于单进程/线程模式。HashDB也没有提供常驻系统服务(Daemon),仅提供如下几个API进行访问。详细信息请参考hashdb.h & hashdb.c,简单描述如下:
HASHDB *hashdb_new(uint64_t tnum, uint32_t bnum, uint32_t cnum, hashfunc_t hash_func1, hashfunc_t hash_func2);
创建一个新的HashDB对象,参数分别为总记录数、hash桶数、缓存记录数、两个hash函数。
int hashdb_open(HASHDB *db, const char *path);
使用HashDB对象打开文件,路径由path指定。如果HashDB文件已经存在,则将header, bloom filter, bucket array载入内存,然后预读记录进行cache预热;如果是新建HashDB,则根据hashdb_new输入参数计算header结构各项参数值,然后在文件中为header, bloom filter, bucket array预分配空间。
int hashdb_close(HASHDB *db, int flash);
关闭HashDB,将缓存数据中的所有脏数据与加文件,并释放内存空间。
int hashdb_set(HASHDB *db, char *key, void *value, int vsize);
设置(写入或更新)KeyValue记录,参数分别为关键字、值以及value长度。pos = hash_func1(key) % cnum,计算出key对应的cache位置,如果该位置已经缓存记录但不是当前记录,则将该记录换出内存(缓存状态设置为未缓存);如果没有缓存并bloom filter判断记录存在,则查找记录并换入内存。然后,设置缓存记录结构各项数据,对于新记录需要设置bloom filter位状态和缓存状态。
int hashdb_get(HASHDB *db, char *key, void *value, int *vsize);
读取KeyValue记录,参数分别为关键字、值缓冲区和值长度。pos = hash_func1(key) % cnum,计算出key对应的cache位置,如果bloom filter判断该记录不存在,则直接返回。如果该位置缓存记录但不是当前记录,则将该记录换出内存;如果没有缓存,则查找记录并换入内存,然后复制key对应的记录值和值长度。
3、核心数据结构与算法
HashDB的核心数据结构由HASHDB结构体来描述,这些信息完整描述如头文件hashdb.h所示。
hashdb_swapout算法
函数原型:int hashdb_swapout(HASHDB *db, uint32_t hash1, uint32_t hash2, HASH_ENTRY *he)
(1)如果he为空,或者he未缓存,直接返回0;
(2)如果he->off == 0,则he未曾被写回文件,需要先确定he->offset和父节点;
2.1 计算桶位置pos = hash1 % db->header.bnum,起始查询节点入口root = db->bucket[pos].off;
2.2 如果root==0则转到2.4,否则从文件root偏移处读取数据hebuf,并获取hentry, hkey, kvalue指针,将patent指向hentry;
2.3 基于hash2和key比较记录,如果hentry大,则root = hentry->left,否则root = hentry->right,跳转到2.2;
2.4 将文件末尾位置即为he->off,如果db->bucket[pos].off == 0,则将he->off设置为桶起始偏移;
2.5 如果parent.off有效,则根据比较大小结果将he设置为其左节点或右节点;
(3)定位文件至he->off处,写回记录数据;
(4)释放he->key和he->value,并将he->off, left, right, cached全部设置为0。
hashdb_swapin算法
函数原型:int hashdb_swapin(HASHDB *db, char *key, uint32_t hash1, uint32_t hash2, HASH_ENTRY *he)
(1)计算桶位置pos = hash1 % db->header.bnum,起始查询节点入口root = db->bucket[pos].off;
(2)如果root==0则转到5,否则从文件root偏移处读取数据hebuf,并获取hentry, hkey, kvalue指针;
(3)基于hash2和key比较记录,如果hentry大,则root = hentry->left,如果hentry小,则root = hentry->right,跳转到2;
(4)找到指定记录,复制数据至he,设置缓存状态he->cached = 1,释放分配空间,并返回成功0;
(5)释放分配空间,返回未找到指定记录-2。
hashdb_set算法
函数原型:int hashdb_set(HASHDB *db, char *key, void *value, int vsize)
(1)检查条件,如果非法则返回错误-1;
(2)计算hash值,hash1 = db->hash_func1(key), hash2 = db->hash_func2(key), pos = hash1 % db->header.cnum;
(3)如果db->cache[pos]缓存但不是key对应记录,则将该记录换出;
(4)如果db->cache[pos]未被缓存,且bloom filter中判断记录存在,则进行换入操作;
(5)如果key和value长度超过最大限制,则返回错误-1;
(6)设置缓存记录的各个数据项,如果是新记录,则将对应的off, left, right设置为0,设置bloom filter位状态和cache状态位。
hashdb_get算法
函数原型:int hashdb_get(HASHDB *db, char *key, void *value, int *vsize)
(1)检查条件,如果非法则返回错误-1;
(2)计算hash值,hash1 = db->hash_func1(key), hash2 = db->hash_func2(key);
(3)检查bloom filter,如果判断记录不存在,则返回不存在-2;
(4)计算pos = hash1 % db->header.cnum,如果db->cache[pos]缓存但不是key对应记录,则将该记录换出;
(5)如果db->cache[pos]未被缓存,则进行换入操作;
(6)复制记录数据至value,并设置值长度。
4、初步性能测试
hashdb.c中实现了简单的性能测试代码,使用gcc -o hashdb bloom.c hashdb.c -DHASHDB_TEST编译生成测试程序。我的Desktop是普通的PC机(4GB内存),运行结果如下。其中,第一个测试用例是创建一个新的hashdb文件,设置和读取100百万条记录分别耗时1.146602和1.254793秒;第二个测试用例对前面创建的hashdb文件进行加载并读取100万条记录,耗时0.726538秒。这个性能已经非常接近于Tokyo Cabinet,当然本测试程序相当简单,只能作为初步的性能测试。测试程序中tnum, bnum, cnum的值均设置为1000万,Key和Value的最大长度均设置为64。对于这个性能测试结果,已经达到初步的设计目标,能够满足deduputil的数据指纹存储和查询需求,后续将对原型作进一步的性能优化。
root@Aigui-Desktop:~# ./hashdb /tmp/hashdb 1000000 set ver del
the value of #1000000 is not set
used time for set records = 1.146602 seconds
used time for get records = 1.254793 seconds
root@Aigui-Desktop:~# ./hashdb /tmp/hashdb 1000000 get ver del
the value of #1000000 is not set
used time for set records = 0.000000 seconds
used time for get records = 0.726538 seconds
5、Roadmap
HashDB后续Roadmap还未作过多考虑,初步想法主要有以下几个着手点。
(1)记录删除支持
(2)不定长记录
(3)异步Cache writeback
(4)Cache管理算法
(5)多线程并发访问
(6)多进程并发访问
(7)Daemon服务
(8)分布式集群化
HashDB是一个简单的KeyValue存储系统原型,提供基本的<key, value>二元组的数据存储与读取功能,亦即当前被广为推崇的NoSQL存储系统。最初想到设计这个小系统,完全是出于偶然。本人维护着一个轻量级的开源重复数据删除小工具deduputil,它基于块级对文件目录进行数据去重并进行打包,支持定长和变长数据分块算法,并支持数据块压缩。deduputil使用hash数据指纹来区分和识别重复数据块,数据块指纹采用hashtable进行存储和查找,并完全置于内存中。假设,数据块平均大小为4KB,数据块对象属性描述约需40字节,则存储8TB数据的指纹大约需要80GB内存,如此庞大的内存需求使得deduputil很难工作于普通的PC或服务器。因此决定对deduputil进行重构,支持在内存有限的环境下进行大数据量的去重和打包,思想是让指纹数据在内存与磁盘之间进行交换。最初想直接采用类似Tokyo Cabinet的NoSQL系统,后来发现这些系统远远比deduputil复杂,使用它们真是大材小用,而且使得deduputil对第三方软件产生了依赖。于是产生了设计一个简单的KeyValue存储系统的念头,经过几个晚上的奋战,HashDB原型系统完成并成功应用于deduputil上,代码量不到1000行,非常非常轻量级。HashDB以较小的内存消耗达到支持超大hashtable,数据持久化存储于文件中,并在内存与文件之间进行交换。HashDB主要采用了hashtable, bloom filter, set-assocaite cache, file layout, btree等数据结构与算法,初步性能测试结果表明HashDB的性能基本还算不错,已经比较接近Tokyo Cabinet的性能。HashDB源码包含在deduputil中,可以从http://sourceforge.net/projects/deduputil/获得。
2、基本原理
HashDB采用哈稀表数据结构组织数据,以文件形式对数据进行持久化存储,文件数据布局如下图所示,由header, bloom filter, bucket array, hash entries四个部分组成。Header记录HashDB的一些全局信息,比如总的记录数、hash桶数、缓存记录数以及它们在文件中的偏移位置。Header持久化存储在HashDB文件头部,加载时需要首先读取它,然后据此加载其他组成部分数据。Bloom filter是一个空间效率很高的数据结构,它由一个位数组和一组hash映射函数组成。Bloom filter可以用于检索一个元素是否在一个集合中,它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。这里主要利用bloom filter来快速判断给定Key是否存在于HashDB中,如果不存在则直接返回,存在则再进行文件I/O读写和Key精确查找,从而节省大量的I/O和检索开销。bloom filter长度由最大支持记录数决定,在创建HashDB时指定并保存在header中,一旦创建不可修改,下次启动时从header中读取并加载。
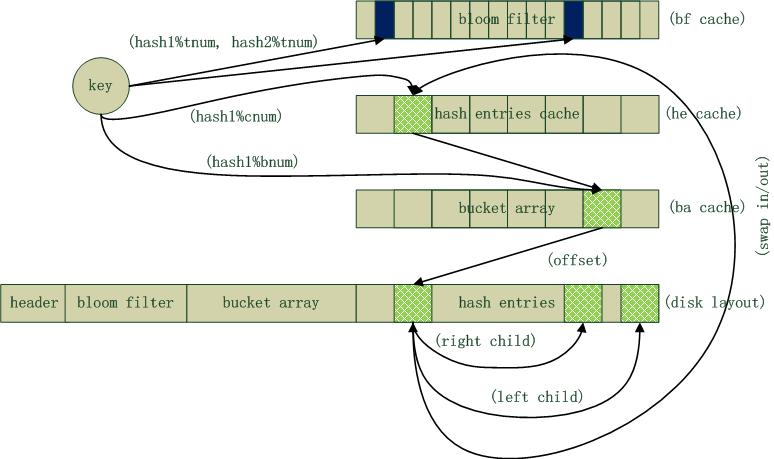
HashDB以hashtable方式组织数据,桶数组长度在创建时指定,同样以后不可修改。bucket array会远远小于记录总数,一般平均桶长在10以上。通常情况下,桶中以链表方式组织产生冲突的记录,查找时遍历链表,当桶较长时顺序查找效率较低。HashDB桶中的记录采用btree结合二次hash方法来组织,这点参考了Tokyo Cabinet。Btree实现简单,查找时间复杂度为log(h),但可能会发生二叉树极度为平衡的情况,而平衡树(如RB, B*, B-, B+树)实现则较为复杂。二次hash方法,先比较hash值再比较关键字key,从而获得较为平衡的btree。实践表明,btree结合二次hash的方法非常有效,可以大大提高检索效率。Bucket array中记录中对应桶的btree根结点偏移,以它为Root可以遍历搜索整个hash桶。
Hash entries区域部分存储了所有的KeyValue记录,出于简化设计实现考虑,每个记录的大小固定,Key和Value都有最大长度限制,记录以Append方式增加,支持修改Key对应的Value值,目前没有支持删除操作。同一个桶中的记录以btree方式组织,入口地址保存在bucket array中对应桶节点中。HashDB设计了Cache系统来提升性能,缓存的记录数量通常约为总记录数的10%,这也是采纳了热点数据的常见比率。Cache管理算法采用类似计算机高速Cache的组相联(Set-associative)算法,以hash为基础进行记录的换入和换出,即同一个桶中的记录会被cache到相同的cache项中。
HashDB中,header, bloom filter, bucket array, hash entries四个部分持久化存储于文件中,运行时header, bloom filter, bucket array完全缓存在内存中,cache则仅在运行时存在,这部分内存空间消耗是可以估算的。假设,总记录数tnum=1000万,hash桶数bnum=100万,缓存记录数量cnum=100万,每条记录固定大小为1KB,则内存消耗=1000万/8 + 100万*8 + 100万*1KB = 1.25MB + 8MB + 1GB。HashDB加载时,header, bloom filter, bucket array将从文件中读取并载入内存,并读取每个hash桶的第一个记录对cache进行预热。HashDB关闭时,内存中的所有脏数据将被写回文件,记录数庞大时,这个过程会比较耗时。
HashDB目前还是一个很简单的原型系统,没有提供锁机制,只能应用于单进程/线程模式。HashDB也没有提供常驻系统服务(Daemon),仅提供如下几个API进行访问。详细信息请参考hashdb.h & hashdb.c,简单描述如下:
HASHDB *hashdb_new(uint64_t tnum, uint32_t bnum, uint32_t cnum, hashfunc_t hash_func1, hashfunc_t hash_func2);
创建一个新的HashDB对象,参数分别为总记录数、hash桶数、缓存记录数、两个hash函数。
int hashdb_open(HASHDB *db, const char *path);
使用HashDB对象打开文件,路径由path指定。如果HashDB文件已经存在,则将header, bloom filter, bucket array载入内存,然后预读记录进行cache预热;如果是新建HashDB,则根据hashdb_new输入参数计算header结构各项参数值,然后在文件中为header, bloom filter, bucket array预分配空间。
int hashdb_close(HASHDB *db, int flash);
关闭HashDB,将缓存数据中的所有脏数据与加文件,并释放内存空间。
int hashdb_set(HASHDB *db, char *key, void *value, int vsize);
设置(写入或更新)KeyValue记录,参数分别为关键字、值以及value长度。pos = hash_func1(key) % cnum,计算出key对应的cache位置,如果该位置已经缓存记录但不是当前记录,则将该记录换出内存(缓存状态设置为未缓存);如果没有缓存并bloom filter判断记录存在,则查找记录并换入内存。然后,设置缓存记录结构各项数据,对于新记录需要设置bloom filter位状态和缓存状态。
int hashdb_get(HASHDB *db, char *key, void *value, int *vsize);
读取KeyValue记录,参数分别为关键字、值缓冲区和值长度。pos = hash_func1(key) % cnum,计算出key对应的cache位置,如果bloom filter判断该记录不存在,则直接返回。如果该位置缓存记录但不是当前记录,则将该记录换出内存;如果没有缓存,则查找记录并换入内存,然后复制key对应的记录值和值长度。
3、核心数据结构与算法
HashDB的核心数据结构由HASHDB结构体来描述,这些信息完整描述如头文件hashdb.h所示。
- #ifndef _HASHDB_H
- #define _HASHDB_H
- #include <stdint.h>
- #include "bloom.h"
- #define HASHDB_KEY_MAX_SZ 256
- #define HASHDB_VALUE_MAX_SZ 256
- #define HASHDB_DEFAULT_TNUM 10000000
- #define HASHDB_DEFAULT_BNUM 10000000
- #define HASHDB_DEFAULT_CNUM 10000000
- typedef struct hash_entry {
- uint8_t cached; /* cached or not */
- char *key; /* key of <key, value> */
- void *value; /* value of <key, value> */
- uint32_t ksize; /* size of the key */
- uint32_t vsize; /* size of the value */
- uint32_t tsize; /* total size of the entry */
- uint32_t hash; /* second hash value */
- uint64_t off; /* offset of the entry */
- uint64_t left; /* offset of the left child */
- uint64_t right; /* offset of the right child */
- } HASH_ENTRY;
- #define HASH_ENTRY_SZ sizeof(HASH_ENTRY)
- typedef struct hash_bucket {
- uint64_t off; /* offset of the first entry in the bucket */
- } HASH_BUCKET;
- #define HASH_BUCKET_SZ sizeof(HASH_BUCKET)
- typedef struct hashdb_header {
- uint32_t magic; /* magic number */
- uint32_t cnum; /* number of cache items */
- uint32_t bnum; /* number of hash buckets */
- uint64_t tnum; /* number of total items */
- uint64_t boff; /* offset of bloom filter */
- uint64_t hoff; /* offset of hash buckets */
- uint64_t voff; /* offset of hash values */
- } HASHDB_HDR;
- #define HASHDB_HDR_SZ sizeof(HASHDB_HDR)
- #define HASHDB_MAGIC 20091209
- typedef uint32_t (*hashfunc_t)(const char *);
- typedef struct hashdb
- {
- char *dbname; /* hashdb filename */
- int fd; /* hashdb fd */
- HASHDB_HDR header; /* hashdb header */
- BLOOM *bloom; /* bloom filter */
- HASH_BUCKET *bucket; /* hash buckets */
- HASH_ENTRY *cache; /* hash item cache */
- hashfunc_t hash_func1; /* hash function for hash bucket */
- hashfunc_t hash_func2; /* hash function for btree in the hash bucket */
- } HASHDB;
- #define HASHDB_SZ sizeof(HASHDB)
- HASHDB *hashdb_new(uint64_t tnum, uint32_t bnum, uint32_t cnum, \
- hashfunc_t hash_func1, hashfunc_t hash_func2);
- int hashdb_open(HASHDB *db, const char *path);
- int hashdb_close(HASHDB *db, int flash);
- int hashdb_set(HASHDB *db, char *key, void *value, int vsize);
- int hashdb_get(HASHDB *db, char *key, void *value, int *vsize);
- int hashdb_unlink(HASHDB *db);
- #endif
HASHDB核心算法主要包括缓存换出、缓存换入、记录设置、记录读取,分别对应hashdb.c源码中的函数hashdb_swapout(), hashdb_swapin(), hashdb_set(), hashdb_get(),详细算法描述如下。
hashdb_swapout算法
函数原型:int hashdb_swapout(HASHDB *db, uint32_t hash1, uint32_t hash2, HASH_ENTRY *he)
(1)如果he为空,或者he未缓存,直接返回0;
(2)如果he->off == 0,则he未曾被写回文件,需要先确定he->offset和父节点;
2.1 计算桶位置pos = hash1 % db->header.bnum,起始查询节点入口root = db->bucket[pos].off;
2.2 如果root==0则转到2.4,否则从文件root偏移处读取数据hebuf,并获取hentry, hkey, kvalue指针,将patent指向hentry;
2.3 基于hash2和key比较记录,如果hentry大,则root = hentry->left,否则root = hentry->right,跳转到2.2;
2.4 将文件末尾位置即为he->off,如果db->bucket[pos].off == 0,则将he->off设置为桶起始偏移;
2.5 如果parent.off有效,则根据比较大小结果将he设置为其左节点或右节点;
(3)定位文件至he->off处,写回记录数据;
(4)释放he->key和he->value,并将he->off, left, right, cached全部设置为0。
hashdb_swapin算法
函数原型:int hashdb_swapin(HASHDB *db, char *key, uint32_t hash1, uint32_t hash2, HASH_ENTRY *he)
(1)计算桶位置pos = hash1 % db->header.bnum,起始查询节点入口root = db->bucket[pos].off;
(2)如果root==0则转到5,否则从文件root偏移处读取数据hebuf,并获取hentry, hkey, kvalue指针;
(3)基于hash2和key比较记录,如果hentry大,则root = hentry->left,如果hentry小,则root = hentry->right,跳转到2;
(4)找到指定记录,复制数据至he,设置缓存状态he->cached = 1,释放分配空间,并返回成功0;
(5)释放分配空间,返回未找到指定记录-2。
hashdb_set算法
函数原型:int hashdb_set(HASHDB *db, char *key, void *value, int vsize)
(1)检查条件,如果非法则返回错误-1;
(2)计算hash值,hash1 = db->hash_func1(key), hash2 = db->hash_func2(key), pos = hash1 % db->header.cnum;
(3)如果db->cache[pos]缓存但不是key对应记录,则将该记录换出;
(4)如果db->cache[pos]未被缓存,且bloom filter中判断记录存在,则进行换入操作;
(5)如果key和value长度超过最大限制,则返回错误-1;
(6)设置缓存记录的各个数据项,如果是新记录,则将对应的off, left, right设置为0,设置bloom filter位状态和cache状态位。
hashdb_get算法
函数原型:int hashdb_get(HASHDB *db, char *key, void *value, int *vsize)
(1)检查条件,如果非法则返回错误-1;
(2)计算hash值,hash1 = db->hash_func1(key), hash2 = db->hash_func2(key);
(3)检查bloom filter,如果判断记录不存在,则返回不存在-2;
(4)计算pos = hash1 % db->header.cnum,如果db->cache[pos]缓存但不是key对应记录,则将该记录换出;
(5)如果db->cache[pos]未被缓存,则进行换入操作;
(6)复制记录数据至value,并设置值长度。
4、初步性能测试
hashdb.c中实现了简单的性能测试代码,使用gcc -o hashdb bloom.c hashdb.c -DHASHDB_TEST编译生成测试程序。我的Desktop是普通的PC机(4GB内存),运行结果如下。其中,第一个测试用例是创建一个新的hashdb文件,设置和读取100百万条记录分别耗时1.146602和1.254793秒;第二个测试用例对前面创建的hashdb文件进行加载并读取100万条记录,耗时0.726538秒。这个性能已经非常接近于Tokyo Cabinet,当然本测试程序相当简单,只能作为初步的性能测试。测试程序中tnum, bnum, cnum的值均设置为1000万,Key和Value的最大长度均设置为64。对于这个性能测试结果,已经达到初步的设计目标,能够满足deduputil的数据指纹存储和查询需求,后续将对原型作进一步的性能优化。
root@Aigui-Desktop:~# ./hashdb /tmp/hashdb 1000000 set ver del
the value of #1000000 is not set
used time for set records = 1.146602 seconds
used time for get records = 1.254793 seconds
root@Aigui-Desktop:~# ./hashdb /tmp/hashdb 1000000 get ver del
the value of #1000000 is not set
used time for set records = 0.000000 seconds
used time for get records = 0.726538 seconds
5、Roadmap
HashDB后续Roadmap还未作过多考虑,初步想法主要有以下几个着手点。
(1)记录删除支持
(2)不定长记录
(3)异步Cache writeback
(4)Cache管理算法
(5)多线程并发访问
(6)多进程并发访问
(7)Daemon服务
(8)分布式集群化















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









