






一、测试的能给我们带来什么?
1、测试的价值
- 帮我们找出程序中的的缺陷和错误
- 帮助我们修改代码的设计以适应实际的使用
- 通过明确需要的行为帮助我们避免类似“镀金”的代码
- 测试最大的价值不是得到测试的结果,而是我们在写测试的过程中的领悟
2、影响程序员生产力的因素
下图展示了一部分我们能想到的影响开发生产力的因素。
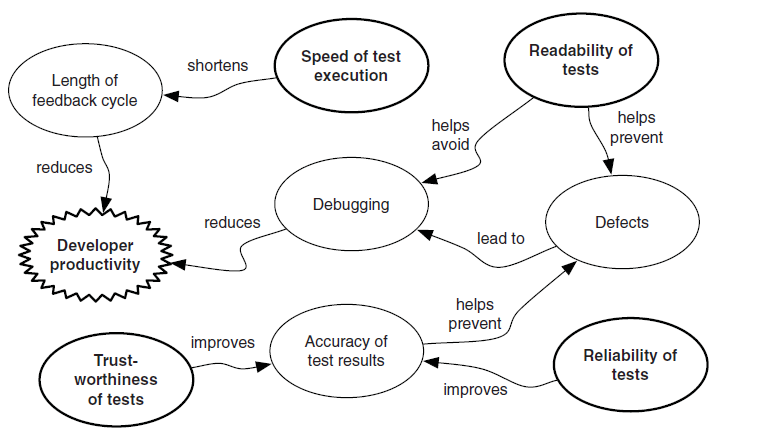
由图可知,影响调试代码和我们得到反馈的时间是影响程序员生产力的直接因素。追溯到根源,测试执行的速度,测试代码的可读性、可靠性以及可依赖性对开发生产力有着根本的影响。
为什么得到反馈的时间和代码调试会影响程序开发生产力呢?由我们经验可知,实际上,许多程序员大部分的时间是在调试代码,而这部分时间其实是在做重复的工作,
但是如果我们写的代码能够得到足够快并且足够明确的反馈,我们是不需要那么频繁地调试代码的,生产力也就提高了。
谷歌2009年发布了一条关于修复一个bug的预算代价的报告,当程序员刚写完代码就发现了一个代码缺陷,修复它的预算是$5,而当这个代码缺陷逃过了程序员的眼睛在构建系统
时才被发现,则修复它的预算为$50,而当这个bug进入集成测试时,修复它则预计为$500,最后,当这个bug非常“侥幸”地到了系统测试的时候,找出并修复它的预算费用为$5000,
从这儿也可以看出一个bug能被越快暴露出来是越好的,这也从说明了一个问题被发现的越早,对整个团队的影响越小。
3、将测试作为一个设计工具
TDD:test-driven development的核心思想是:在写生产代码之前,一定要先写出对应的暂时不能通过的测试代码以验证你要写的代码的正确性。
通过先写测试,你可以获得如下好处:
代码变得更有用:你可以站在一个设计者而非代码实现者的高度,使设计和接口更适应于你要去实现的场景的需要
代码变得更简洁:你的代码都是为了实现你预先设计的场景,不会去做“多余”的事情,导致实现过于复杂
二、什么样的测试代码才是好的测试代码?
1、可能想到的评判测试代码好坏的标准
我们应该将测试代码与生产代码置于一个相对平等的地位,你重视它,它才有可能回报你更多。这样,我们可以评判编写生产代码的标准作为一个参考依据。
能想到的一些因素如下:
- 测试代码的可读性和可维护性
- 测试代码是如何组织的,如测试代码的结构
- 一个测试用例是用来测试什么场景的是否明确
- 测试用例能否可靠地重复执行
- 测试代码是如何使用测试复制(stub、mock等)的
2、为什么以上因素可以影响测试代码的质量
- 易读的代码才会更容易维护。试想一段代码我们很难读懂或者根本读不懂,怎么维护它?
- 良好的代码结构可以让我们更好地看清它在干些什么。如果我们将所有的逻辑都放到一个java文件里,会怎么样?没有人愿意去读那些又臭又长的类,当需要
哪怕一丁点儿的改变时,我们都要费尽九牛二虎之力去找到应该要到哪儿去修改,我们可以说这样的代码"封装"的不好,或者不符合"单一职责原则"。 
- 拥有良好代码结构的测试可以带来如下好处:
1)能很快找到与你手头的工作相关的测试类
2)能很快从很多的测试类中识别出想要的测试方法
3)能从测试方法中理解类的生命周期。 - 不要让测试代码去测试"错误"的东西。如果我们的测试方法测试的东西与其方法名字并不完全相符,那会怎么样?不能根据方法名判断一个测试用例在做什么,我们
就必须费尽脑细胞去理清其逻辑。 - 独立性强的测试代码更容易运行,而不需要额外的支持。我们写测试时会遇到很多情况,如果遇到不依赖于测试环境的因素或情况比较复杂时应怎么办?如:时间、随机数、
并发、基础构件、预存的数据、持久化、网络等。我们不能保证运行测试时的时间如我们所预期,不能保证生产代码里的随机数是多少,也不能为每个单元测试的运行搭建一个
数据库,还有网络问题等等。如下是一些可行的解决方案:
1)将第三方类库包装在一层薄薄的适配层中,这样就可以将复杂的与第三方类库结合的情况限制在了一小块可以单独测试代码中,然后使用“测试复制”代替这一个适配层。
2)使测试代码与其使用的资源放在一起
3)让测试自己建立自己的上下文,不要依赖其它测试的结果或副作用。
4)使用在集成测试时使用“内存数据库”代替真实的数据库。这样不光能很简单地就提供一个空的数据库,而且启动也非常快。
5)将同步与异步的测试代码分开,所有的逻辑没有了异步的干扰会更加容易测试,最后集中精力去搞复杂的仅剩的异步逻辑。
这样我们就不需要依赖于外部环境,测试随时随处可以运行。 - 只有可靠的测试才靠得住。
你能找到如下这段代码的问题吗?@Test
public void shouldRefuseNegativeEntries() {
int total = record.total();
try {
record.add(-1);
} catch (IllegalArgumentException expected) {
assertEquals(total, record.total());
}
}
这段测试代码的本意是,如果向record添加-1,就会抛出IllegalArgumentException异常。但是这段代码永远不会发出错误警告,即使recored.add(-1)没有抛出异常。
-
三、测试复制
1、测试复制能为我们带来什么?
测试复制,顾名思义是测试中对象的复制品,它们有着和原始对象一样的接口,但是其行为却受我们的控制。如test stub、mock object等,这可以为我们带诸多好处:
- 在测试时分离代码
当我们编写测试代码时,系统中的代码一共有两类,需要测试的代码和与这些需要测试的代码有相互作用代码。测试复制可以让我们分离被测试代码和与其相关的代码,这样我们就可以
集中精力注意被测试的的行为,而不受其他因素的干扰。 - 提高测试代码的执行速度
//TODO - 让测试的执行结果具有确定性
//TODO - 模拟特殊的情况
//TODO - 能够访问一些隐藏信息
//TODO -
2、测试复制的分类
-
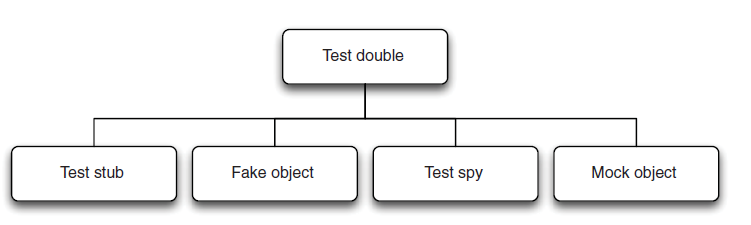
-
如上图所示,测试复制共分四类:test stub、fake object、test spy、mock object。
1)test stub:中文意思是测试桩,桩很小很轻,它基本上什么也不做。
例如有一个记录日志的类Logger,它有一个方法public void log(LogLevel lever, String message),则此类的桩可以定义为这样:
public class LoggerStub implements Logger {
public void log(LogLevel level, String message) { }
}桩很简单,简单到方法里一行代码都没有。
如果方法有返回值怎么办?直接硬编码返回一个固定值就可以了。
public class LoggerStub implements Logger {
public void log(LogLevel level, String message) {
}
public LogLevel getLogLevel() {
return LogLevel.WARN; // hard-coded return value
}
}有些人会想返回一个固定值会不会有问题,大多数情况下没有问题,因为我们使用test stub的原因如下:
- 我们根本不关心被测试的代码是否正在记日志
- 如果我们需要一个日志服务器,而它并不能为我们的测试所用,如果没有test stub,测试就肯定不会成功
- 我们并不希望测试会打印很多很多的日志在控制台,更不要说是打印到日志文件里了。
-
2)fack object
相较于test stub,fack object是一个更精细的测试复制,它可以根据方法的输入参数做一些简单的判断,但是不会产生
任何副作用。fack object就像是一个相较于真实对象非常轻小的对象,可以根据场景做出正确的反应,但是这些反应不会真实发生。
比如现在有一个可以实现用户操作的用户仓库类UserRepository:
public interface UserRepository {
void save(User user);
User findById(long id);
User findByUsername(String username);
}我们不希望这个类真实地操作数据库,这样就不需要依赖于外部的数据库了。相应的fack object实现如下:
public class FakeUserRepository implements UserRepository {
private Collection<User> users = new ArrayList<User>();
public void save(User user) {
if (findById(user.getId()) == null) {users.add(user);
}
}
public User findById(long id) {
for (User user : users) {
if (user.getId() == id) return user;
}
return null;
}
public User findByUsername(String username) {
for (User user : users) {
if (user.getUsername().equals(username)) {
return user;
}
}
return null;
}
}因为这个类很简单,我们可以这样简单地处理,使用java的容器来充当这个数据库。fack object可以有真实的操作,但是
却比真实的操作更快,使用的外部组件更少。
3)test spy
test spy,“测试间谍”,它可以窃取对象的秘密。
试想这段代码应该怎么测?
public String concat(String first, String second) { ... }
应该很快能想到直接验证返回的结果是否如预期那样,那么接下来的这段代码呢?
public void filter(List<?> list, Predicate<?> predicate) { ... }
这个方法没有返回结果,但是我们可以通过验证list是否如预期那样来测试这段代码,并不需要测试复制。
但是,接下来呢?
public class DLog {
private final DLogTarget[] targets;
public DLog(DLogTarget... targets) {
this.targets = targets;
}
public void write(Level level, String message) {
for (DLogTarget each : targets) {
each.write(level, message);
}
}
}
public interface DLogTarget {
void write(Level level, String message);
}targets是一个包含分布式日志记录对象的数组,当调用DLog的write方法时,应该调用targets中的所有对象的write方法,但是并没有任何一个日志对象有一个方法来显示
其write方法被调用了,怎么确定所有的target中的对象的write方法都被调用了呢?使用test spy。如下所示:
public class DLogTest {
@Test
public void writesEachMessageToAllTargets() throws Exception {
SpyTarget spy1 = new SpyTarget();
SpyTarget spy2 = new SpyTarget();
DLog log = new DLog(spy1, spy2);
log.write(Level.INFO, "message");
assertTrue(spy1.received(Level.INFO, "message"));
assertTrue(spy2.received(Level.INFO, "message"));
}
private class SpyTarget implements DLogTarget {
private List<String> log = new ArrayList<String>();
@Override
public void write(Level level, String message) {
log.add(concatenated(level, message));
}boolean received(Level level, String message) {
return log.contains(concatenated(level, message));
}
private String concatenated(Level level, String message) {
return level.getName() + ": " + message;
}
}
}SpyTarget是DLogTarget的一个test spy实现,它提供了recieve方法,用来验证是否被调用了write方法。
4)mock object
mock object是一种特殊的test spy,可以被配置为在特定的场景下执行特定的行为。mock object相当于一个受程序员控制的机器人,它只会执行任何你向它下达的特定的命令(特定的方法和特定的参数)。
现在有很多的第三方类库可以创建mock object,例如mockito、JMock、EasyMock等,各个类库做的事情都差不多。
下面使用mockito作为例子:
@RunWith(MockitoJUnitRunner.class)
public class TestTranslator {
@Mock
private Internet internet;
@Test
public void usesInternetForTranslation() throws Exception {
when(internet.get(ENGLISH)).thenReturn("kukka")
Translator t = new Translator(internet);
String translation = t.translate("flower", ENGLISH, FINNISH);
assertEquals("kukka", translation);
}
...
}当调用mock oject internet的get(String str)方法时,当且仅当传递参数"langpair=en%7Cfi"时会返回字符串"kukka",而且还可以规定get方法应该被执行多少次。
3、使用测试复制的一些指导方针
1)使用正确的测试复制类型
- 如果你关心两个对象之间以方法调用形式发生交互的一个确定的情况,那么你应该使用mock object
- 如果你决定使用mock object,但是你的测试代码最后却看起来不那么地优雅,那么你应该试试简单的,手工制作的test spy是否能让代码更漂亮点
- 如果你只需要有一个合作对象的存在,并且返回一个此测试可控制的值,应该使用test stub
-
如果你想测试一个依赖于不可得或者不可用的服务或者组件来测试一个比较复杂的场景,并且当你尝试执行编写的测试代码时会响应很慢或者测试代码会很乱以至于很难去阅读和维护的时候,你应该考虑实现一个fake object来代替
-
如果以上情况都不是,那就自己决定,没那么严格。
如果你觉得上面的建议太多太难记,可以记住一个简单的口诀:查询用stub,执行动作用mock。
-
2)合理安排测试代码结构----arrange,act, assert
相对于编码习惯,测试也有经过实践总结的经验,即,先组织测试使用的对象,然后执行相应的动作,最后断言结果。如之前的一个例子:
@RunWith(MockitoJUnitRunner.class)
public class TestTranslator {
@Mock
private Internet internet;
@Test
public void usesInternetForTranslation() throws Exception {
when(internet.get("langpair=en%7Cfi")).thenReturn("kukka")
Translator t = new Translator(internet);
String translation = t.translate("flower", ENGLISH, FINNISH);
assertEquals("kukka", translation);
}
...
}代码中间故意加了一些间隙,就是为了区分测试代码的这三个部分。
这个结构可以让我们更加的专注于要测试的点,如果这三部分中的任何一部分太大,那么就应该想想这段测试是不是做的太多了,我们应该更专注才对。
3) 测试行为,而不是实现
对于我们刚开始使用mock类库的程序员来说,很容易犯一些错误,就是在使用mock对象的时候过分在意实现细节,尤其是一个方法中使用的几乎所有对象都是Mock出来的对象的时候,这样写代码的话会给我们一种哪怕做一些与测试目的不相关的改变都会影响到测试结果,造成这种现象的根本原因是我们太不“专注”了,我们应该要分清楚什么是我们想要的行为表现,什么是我们不太在意的行为表现,
对于我们想要的行为表现应该使用mock object,而不太在意的行为表现就应该使用test stub或者其它要求不太严格的mock对象,fake、spy等。
4)选择工具
java的mock object类库有很多,我们可以使用它们做差不多一样的事情,它们只是在接口定义上有一些轻微的差别,这也许会对我们的选择有一些影响。我们统一使用mockito。
5)注入你的依赖
为了能使用测试复制,我们需要用他们来替换真正的对象。建议不要在使用这些真正的对象的地方替换测试复制,因为为了能这样做,你可能需要把这个对象的修饰符修改为public或者使用反射来分配一个测试复制为private的域。更好的选择是使用依赖注入,从外部将测试复制传到对象内部,例如set方法或者构造器。
四、怎么编写可读的、可维护的、可信赖的测试代码
1、测试代码的可读性
通过前面的简单介绍大家应该对测试代码的可读性的影响有一个大概的认识,我们代码不应该读起来很困难,不应该让我们“费力”地去思考才能知道它做了什么。
- 基本类型断言
如下所示是一个有问题的例子:@Test
这个测试用例是用来测试一个grep工具类的,grep()方法用来输出哪一行有匹配的字符串。
public void outputHasLineNumbers() {
String content = "1st match on #1\nand\n2nd match on #3";
String out = grep.grep("match", "test.txt", content);
assertTrue(out.indexOf("test.txt:1 1st match") != -1);
assertTrue(out.indexOf("test.txt:3 2nd match") != -1);
}
但是,当我们读到最后两行的断言部分的时候,是不是觉得自己被绕进去了……明明是一个很简单的判断是否包含字符串的逻辑啊,怎么读起来这么费劲!
首先我们可能会很迷惑,这个断言到底是说index==1还是index!=1,下面我们做一个简单的修改:@Test
结合了Hamcrest之后是不是清晰多了,至少我们一眼望去就能看到,能很清晰的知道这个断言是在说index!=-1,但是还是要再稍微想一下才能知道这个断言是要判断out包含还是不包含指定的字符串,再修改一下:
public void outputHasLineNumbers() {
String content = "1st match on #1\nand\n2nd match on #3";
String out = grep.grep("match", "test.txt", content);
assertThat(out.indexOf("test.txt:1 1st match"), is(not(-1)));
assertThat(out.indexOf("test.txt:3 2nd match"), is(not(-1)));
}@Test
这样我们就能一眼看出来这是在判断是否包含字符串的逻辑了。
public void outputHasLineNumbers() {
String content = "1st match on #1\nand\n2nd match on #3";
String out = grep.grep("match", "test.txt", content);
assertThat(out, containsString("test.txt:1 1st match"));
assertThat(out, containsString("test.txt:3 2nd match"));
}
当我们看到==或者!=,尤其是==0或!=-1之类的测试代码时,就停下来想想你的表达是不是清晰了。之所以这样的代码会让人迷惑,是因为这此基本类型的抽象层面与我们写测试时的抽象层面不相符,
当使用较低层的抽象元素来描述较高层的抽象情景时,就会出现这种情况了。所以为了能更清晰地表达自己的意图,思维不要那么跳跃,在一个抽象层面上思考问题! -
-
2、测试代码的可维护性
程序员应该都知道,改代码是最常见的事情了,代码不可能写完就放在那儿以后就再也不用管了,当需求改变了,当需求增加了,当一开始理解错了,当有了新的想法……我们就需要去维护变更代码。当代码量比较小时,维护成本可能会非常小,但是当代码量非常巨大,
尤其是我们这种企业级的开发,修改那些可维护性很差的代码可能会引发一个大灾难,不光是会浪费许多的时间,而且可能有让系统推倒重来的风险。因为测试代码与生产代码是一样的,它也需要被时常维护,你当然不会希望每次修改自己的测试代码都要绞尽脑汁,
甚至从头再来。
- 代码重复
代码重复应该算得上程序员最痛恨的代码坏味道之一了,它不仅使代码总量大幅增加,而且让人不容易从整体理解代码逻辑,更重要的是,它会极大地增加代码的可维护性,因为一旦有东西要修改,你需要找到系统中所有的相同的代码,逐个修改,不仅浪费时间,
还会因为漏掉一两段代码而引起不必要的问题,而测试代码与生产代码面临着同样的问题。下面是一个有代码重复坏味道的例子:public class TemplateTest {
@Test
public void emptyTemplate() throws Exception {
assertEquals("", new Template("").evaluate());
}@Test
大家看以上这段代码有没有重复的代码?
public void plainTextTemplate() throws Exception {
assertEquals("plaintext", new Template("plaintext").evaluate());
}
}
很明显的是第一个测试的两个空字符串、第二个测试的两个"plaintext"字符串分别是重复的,那我们应该处理这些重复代码:public class TemplateTest {
@Test
public void emptyTemplate() throws Exception {
String template = "";
assertEquals(template , new Template(template ).evaluate());
}@Test
public void plainTextTemplate() throws Exception {
String template = "plaintext";assertEquals(template , new Template(template ).evaluate());
}
}
当处理完这种字面量的重复代码之后,很快就能发现又多了一项重复,两个测试都使用template字符串做同一个操作, new Template(template ).evaluate(),这种代码重复叫做结构重复,再做一下修改:public class TemplateTest {
@Test
public void emptyTemplate() throws Exception {
assertTemplateRendersAsItself("");
}
@Test
public void plainTextTemplate() throws Exception {
assertTemplateRendersAsItself("plaintext");
}
private void assertTemplateRendersAsItself(String template) {
assertEquals(template, new Template(template).evaluate());
}
}
这样就消除了代码重复了,要修改代码的话只需要修改一处,也有利于代码语义的理解。 -
条件逻辑
写测试一部分原因是为了减少回归bug的产生,我们依赖测试理清以及理解生产代码的行为,但是测试代码中条件逻辑的存在会阻碍我们理解生产代码的这些行为。当进行代码重构时,如果跑测试的过程中,有些测试稀里糊涂就失败了,或者测试没有出现失败,而回归bug却产生了。那可能就是条件逻辑导致的问题。以下是一个例子:
public class DictionaryTest {
@Test
public void returnsAnIteratorForContents() throws Exception {
Dictionary dict = new Dictionary();
dict.add("A", new Long(3));
dict.add("B", "21");
for (Iterator e = dict.iterator(); e.hasNext();) {
Map.Entry entry = (Map.Entry) e.next();
if ("A".equals(entry.getKey())) {
assertEquals(3L, entry.getValue());
}
if ("B".equals(entry.getKey())) {
assertEquals("21", entry.getValue());
}
}
}
}
这个例子测试的是数据字典的功能,调用iterator()方法产生一个能够遍历字典内所有元素的迭代器,然后在for循环中断言每个元素是不是都存在。但是应该能看到这段代码有问题,
因为即使for循环不执行,测试仍然会通过,而且我们会把注意力过分集中到这些复杂的循环判断逻辑中,而让测试的本来目的变得不那么明确了,这种情况应该避免。
处理复杂代码时第一个想到的应该就是把复杂的代码分离出去,然后给那段复杂的代码起个好名字,原来的代码就可以化繁为简了,上面这段代码最复杂的要数for循环了,那我们展示一下改进的版本:
@Test
public void returnsAnIteratorForContents() throws Exception {
Dictionary dict = new Dictionary();
dict.add("A", new Long(3));
dict.add("B", "21");
assertContains(dict.iterator(), "A", 3L);
assertContains(dict.iterator(), "B", "21");
}
private void assertContains(Iterator i, Object key, Object value) {
while (i.hasNext()) {
Map.Entry entry = (Map.Entry) i.next();
if (key.equals(entry.getKey())) {
assertEquals(value, entry.getValue());
return;
}
}
fail("Iterator didn't contain " + key + " => " + value);
}
通过改进,单元测试的主体部分应该很明确了,而且被抽离的for循环方法跟之前相比有一点不同,在遍历完迭代器时,如果没有找到相应的元素,现在会让测试失败。
条件分支结构在生产代码中非常常见,但是在测试代码中不一样,条件分支结构会增加代码的复杂性,使测试的目的变得模糊不清,一旦在测试中发现像if、for、while和switch等关键字时应该停下来想想增加这些逻辑到底值不值得。 -
3、测试代码的可依赖性
测试代码是被写来验证生产代码的正确性的,它必须能够明确地、正确地、迅速地指出程序中出现的回归bug,它的可依赖性的重要性不言而喻,如果我们连自己的测试都不能信任的话,那写这些测试还有什么意义呢?
- 使人误导的注释
不得不说,注释是个好东西,它可以更清楚更详细地说出代码干了什么以及为什么这样干,但是任何一个好东西被过分使用或者使用不当,其对代码的伤害也会非常大。以下是一个滥用注释的例子:@Test
public void pastDueDateDebtFlagsAccountNotInGoodStanding() {// create a basic account
Customer customer = new Customer();
DeliquencyPlan deliquencyPlan = DeliquencyPlan.MONTHLY;
Account account = new CorporateAccount(customer, deliquencyPlan);
// register a debt that has a due date in the future
Money amount = new Money("EUR", 1000);
account.add(new Liability(customer, amount, Time.fromNow(1, DAYS)));
// account should still be in good standing
assertTrue(account.inGoodStanding());
// fast-forward past the due date
Time.moveForward(1, DAYS);
// account shouldn't be in good standing anymore
assertFalse(account.inGoodStanding());
}这个例子是说创建一个基础的帐户,然后注册一个在未来有到期时间的贷款,然后判断帐户应该是正常,然后当帐户过期时,帐户应该会变得不正常。
也许有人会说这段代码写的很清楚,至少注释写的很详细,一看就能看明白。注释是个好东西,但是不要用的太多了,当仔细看看这个测试的代码实现时,
会注意到第一行注释其实是有一点问题的,注释说是要创建一个基础帐户,而实际上是创建了一个公司帐户。还有倒数第二个注释fast-forward past the due date,
这可能是一个笔误,但是也容易造成误导fast-forward on the due date和fast-forward past the due date还是有点区别的。
我们的理念应该是少写注释,也许有人会反对,可能以前或者什么时候有人给你说过,写代码一定要写注释,没注释的代码不是好代码,但是前提是你能写好写准确注释,
而且也没有必要在方法体里写那么多注释。不用注释,应该怎么办呢?
1)使用一个拥有很好命名的变量或者方法来代替注释
2)将注释说明的那段代码抽取成一个拥有良好命名的方法,用这个方法替换注释以及相关的代码。
当然,并不说不要写注释,注释是很重要的,注释更多地应该是记录作者当时写这段代码的想法,或者对这段代码的一个特殊说明,去掉一些不必要的注释,注释的作用才会更突出。 - 永远都不会失败的测试
如果一个测试怎么跑都会通过,它的存在也就没有什么意义了。@Test
public void includeForMissingResourceFails() {
try {
new Environment().include("somethingthatdoesnotexist");
} catch (IOException e) {
assertThat(e.getMessage(),
contains("somethingthatdoesnotexist"));
}
}
以上这段代码有什么问题呢?它永远也不会失败。@Test
public void includeForMissingResourceFails() {
try {
new Environment().include("somethingthatdoesnotexist");
fail();
} catch (IOException e) {
assertThat(e.getMessage(), contains("somethingthatdoesnotexist"));
}
}@Test(expected = IOException.class)
public void includingMissingResourceFails() {
new Environment().include("somethingthatdoesnotexist");
}上面是两种修改方式,第二种较第一种更简洁,但是没有第一种功能强大,第一种方式可以断言异常的一些更详细的信息。
- 条件测试
条件测试不光使代码不易维护,它还会隐藏测试的目的,让测试不可信。@Test
public void multipleArgumentsAreSentToShell() throws Exception {
File dir = createTempDirWithChild("hello.txt");
String[] cmd = new String[] { "ls", "-1", dir.getAbsolutePath() };
Process process = new Process(cmd).runAndWait();
if (process.exitCode() == 0) {
assertEquals("hello.txt", process.output().trim());
}
}@Test
public void multipleArgumentsAreSentToShell() throws Exception {
File dir = createTempDirWithChild("hello.txt");
String[] cmd = new String[] { "ls", "-1", dir.getAbsolutePath() };
Process process = new Process(cmd).runAndWait();
assertEquals(0, process.exitCode());
assertEquals("hello.txt", process.output().trim());
}@Test
public void returnsNonZeroExitCodeForFailedCommands() {
String[] cmd = new String[] { "this", "will", "fail" };
Process process = new Process(cmd).runAndWait();
assertThat(process.exitCode(), is(greaterThan(0)));
} - 断言过度
断言是我们在写测试的时必需的一种工具,但是不要让它管的太宽了。public class LogFileTransformerTest {
private String expectedOutput;
private String logFile;
@Before
public void setUpBuildLogFile() {
StringBuilder lines = new StringBuilder();
appendTo(lines, "[2005-05-23 21:20:33] LAUNCHED");
appendTo(lines, "[2005-05-23 21:20:33] session-id###SID");
appendTo(lines, "[2005-05-23 21:20:33] user-id###UID");
appendTo(lines, "[2005-05-23 21:20:33] presentation-id###PID");
appendTo(lines, "[2005-05-23 21:20:35] screen1");
appendTo(lines, "[2005-05-23 21:20:36] screen2");
appendTo(lines, "[2005-05-23 21:21:36] screen3");
appendTo(lines, "[2005-05-23 21:21:36] screen4");
appendTo(lines, "[2005-05-23 21:22:00] screen5");
appendTo(lines, "[2005-05-23 21:22:48] STOPPED");
logFile = lines.toString();
}
@Before
public void setUpBuildTransformedFile() {
StringBuilder file = new StringBuilder();
appendTo(file, "session-id###SID");
appendTo(file, "presentation-id###PID");
appendTo(file, "user-id###UID");
appendTo(file, "started###2005-05-23 21:20:33");
appendTo(file, "screen1###1");
appendTo(file, "screen2###60");
appendTo(file, "screen3###0");
appendTo(file, "screen4###24");
appendTo(file, "screen5###48");
appendTo(file, "finished###2005-05-23 21:22:48");
expectedOutput = file.toString();
}
@Test
public void transformationGeneratesRightStuffIntoTheRightFile()
throws Exception {
TempFile input = TempFile.withSuffix(".src.log").append(logFile);
TempFile output = TempFile.withSuffix(".dest.log");
new LogFileTransformer().transform(input.file(), output.file());
assertTrue("Destination file was not created", output.exists());assertEquals(expectedOutput, output.content());
}
// rest omitted for clarity
}这个例子看起来很长,但是它要测试的功能很简单----记录PPT演示的日志,并将其进行格式转换。但是当它失败时,我们并不能准确地说出来到底哪里出问题了,只能再仔细看代码细节。
第一个断言看起来很合理,但是它是不需要的,因为有没有这个断言结果是一样的,第二个断言是我们主要应该关注的地方,它管的太宽了。
我们写单元测试时应该有一条原则:一个测试应该只有一个引起它错误的原因。是不是很熟悉?这跟单一职责原则所描述的是一样的:一个类应该有且只有一个引起它变化的原因。
而上面这个测试并不是这样,它比较整个log文件的输出,这样许多原因都可能引起这个测试的失败。
下面是修改后的一个版本:public class LogFileTransformerTest {
private static final String END = "2005-05-23 21:21:37";
private static final String START = "2005-05-23 21:20:33";
private LogFile logFile;
@Before
public void prepareLogFile() {
logFile = new LogFile(START, END);
}
@Test
public void overallFileStructureIsCorrect()
throws Exception {
StringBuilder expected = new StringBuilder();
appendTo(expected, "session-id###SID");
appendTo(expected, "presentation-id###PID");
appendTo(expected, "user-id###UID");
appendTo(expected, "started###2005-05-23 21:20:33");
appendTo(expected, "finished###2005-05-23 21:21:37");
assertEquals(expected.toString(), transform(logFile.toString()));
}
@Test
public void screenDurationsGoBetweenStartedAndFinished()
throws Exception {
logFile.addContent("[2005-05-23 21:20:35] screen1");
String out = transform(logFile.toString());
assertTrue(out.indexOf("started") < out.indexOf("screen1"));
assertTrue(out.indexOf("screen1") < out.indexOf("finished"));
}
@Test
public void screenDurationsAreRenderedInSeconds()
throws Exception {
logFile.addContent("[2005-05-23 21:20:35] screen1");
logFile.addContent("[2005-05-23 21:20:35] screen2");
logFile.addContent("[2005-05-23 21:21:36] screen3");String output = transform(logFile.toString());
assertTrue(output.contains("screen1###0"));
assertTrue(output.contains("screen2###61"));
assertTrue(output.contains("screen3###1"));
}
// rest omitted for brevity
private String transform(String log) { ... }
private void appendTo(StringBuilder buffer, String string) { ... }
private class LogFile { ... }
}这个版本把之前的一个测试分解成了三个,screenDurationsGoBetweenStartedAndFinished和screenDurationsAreRenderedInSeconds分别测试记录PPT的播放的相对位置与时间是否正确,而我们使用LogFile当作待转换的日志的原始文件,
所以整个文件结构转换的完整性由overallFileStructureIsCorrect来保证。这样一旦运行测试出现问题,就可以很快定位问题的所在了。 - 测试用例中包含过多的细节
我们在写代码时都知道要将不同的逻辑放在不同的类或者方法中,通过对象方法的调用可以让代码结构以及逻辑更加清晰。写测试代码时也是一样,把过多的细节堆到一起,也会让测试的目的模糊。
下面的例子是验证保存Ruby对象的功能的一个测试,首先新建三个数字型的对象和一个字符串类型的对象,再分别将这四个对象存入objectSpace中,然后再分别取出来验证这个对象已经存在于objectSpace中了。这段逻辑对于绝大多数来说都很简单:public class TestObjectSpace {
private Ruby runtime;
private ObjectSpace objectSpace;
@Before
public void setUp() throws Exception {
runtime = Ruby.newInstance();
objectSpace = new ObjectSpace();
}
@Test
public void testObjectSpace() {
IRubyObject o1 = runtime.newFixnum(10);
IRubyObject o2 = runtime.newFixnum(20);
IRubyObject o3 = runtime.newFixnum(30);
IRubyObject o4 = runtime.newString("hello");
objectSpace.add(o1);
objectSpace.add(o2);
objectSpace.add(o3);
objectSpace.add(o4);
List storedFixnums = new ArrayList(3);
storedFixnums.add(o1);
storedFixnums.add(o2);
storedFixnums.add(o3);
Iterator strings = objectSpace.iterator(runtime.getString());
assertSame(o4, strings.next());
assertNull(strings.next());
Iterator numerics = objectSpace.iterator(runtime.getNumeric());
for (int i = 0; i < 3; i++) {
Object item = numerics.next();
assertTrue(storedFixnums.contains(item));
}
assertNull(numerics.next());
}
}但是,你需要多久能搞清楚这段代码的目的?经过分析,这段代码的主要逻辑是获取特定类型的迭代器,并且验证相应迭代器中确切含有相应的对象,而这段主要的逻辑却被其他一些不太相关的逻辑”淹没“了。
修改后的一个版本:
public class TestObjectSpace {
private Ruby runtime;
private ObjectSpace space;
private IRubyObject string;
private List<IRubyObject> fixnums;
@Before
public void setUp() throws Exception {
runtime = Ruby.newInstance();
space = new ObjectSpace();
string = runtime.newString("hello");
fixnums = new ArrayList<IRubyObject>() {{
add(runtime.newFixnum(10));add(runtime.newFixnum(20));
add(runtime.newFixnum(30));
}};
}
@Test
public void testObjectSpace() {
addTo(space, string);
addTo(space, fixnums);
Iterator strings = space.iterator(runtime.getString());
assertContainsExactly(strings, string);
Iterator numerics = space.iterator(runtime.getNumeric());
assertContainsExactly(numerics, fixnums);
}
private void addTo(ObjectSpace space, Object... values) { }
private void addTo(ObjectSpace space, List values) { }
private void assertContainsExactly(Iterator i, Object... values) { }
private void assertContainsExactly(Iterator i, List values) { }
}
这样再读一读这个测试,有没有清晰一点,至少我们在读的时候不用再在脑子里装太多不太相关的细节了,为什么同样的代码会出现这样的差异呢?因为将一些不相关的逻辑封装抽象到了私有方法或者setup方法中,我们可以将自己提升一个抽象的层面,关注的点少了,自然就更加清晰了。 - 一个测试用例中包含多个测试点
先举个例子:public class TestConfiguration {
这个例子是在测试解析命令行参数,来验证文件名、是否可以调试,是否能够发出警告,是否有详细信息,是否展示版本信息和空的配置的错误等。但是很明显这儿的判断有点多了,因为参数根本就没有那么多,这种时候就应该分离这些测试点,如下是修改的一个版本:
@Test
public void testParsingCommandLineArguments() {
String[] args = { "-f", "hello.txt", "-v", "--version" };
Configuration c = new Configuration();
c.processArguments(args);
assertEquals("hello.txt", c.getFileName());
assertFalse(c.isDebuggingEnabled());
assertFalse(c.isWarningsEnabled());
assertTrue(c.isVerbose());
assertTrue(c.shouldShowVersion());
c = new Configuration();
try {
c.processArguments(new String[] {"-f"});
fail("Should've failed");
} catch (InvalidArgumentException expected) {
// this is okay and expected
}
}
}public abstract class AbstractConfigTestCase {
看到上面这个版本你可能会想,怎么当初那么一点代码现在被改的变得这么多,不是更复杂更难读了吗?可能是变得有点复杂了,但是你仔细看看,它真的变得更难读了吗?
protected Configuration c;
@Before
public void instantiateDefaultConfiguration() {
c = new Configuration();
c.processArguments(args());
}
protected String[] args() {
return new String[] { };
}
}
public class TestDefaultConfigValues
extends AbstractConfigTestCase {
@Test
public void defaultOptionsAreSetCorrectly() {
assertFalse(c.isDebuggingEnabled());
assertFalse(c.isWarningsEnabled());
assertFalse(c.isVerbose());
assertFalse(c.shouldShowVersion());
}
}
public class TestExplicitlySetConfigValues
extends AbstractConfigTestCase {
@Override
protected String[] args() {
return new String[] {"-f", "hello.txt", "-v", "-d", "-w", "--version"};
}
@Test
public void explicitOptionsAreSetCorrectly() {
assertEquals("hello.txt", c.getFileName());
assertTrue(c.isDebuggingEnabled());
assertTrue(c.isWarningsEnabled());
assertTrue(c.isVerbose());
assertTrue(c.shouldShowVersion());
}
}
public class TestConfigurationErrors
extends AbstractConfigTestCase {
@Override
protected String[] args() {
return new String[] {"-f"};
}
@Test(expected = InvalidArgumentException.class)
public void missingArgumentRaisesAnError() { }
}
虽然最初的一个类变成了四个类,但是这使代码更加专注了,每个类的每个方法的测试点都非常明确,实际上这个测试变得简单了,因为当测试运行有问题时,我们可以很清晰地知道到底是哪儿出问题了。
如果觉得新建四个类实在太麻烦了,那么改成一个类三个方法代码量就会少很多了。
- 魔法数
魔法数应该是所有程序员都非常痛恨的东西,当在程序中看到它时,我们可能根本就不明白它在表达什么。比如当你看到程序中有一个数字37,你可能会想这儿为什么是37呢,可不可以改成其他数字比如38呢?
我们需要一个能表达魔法数的变量来代替魔法数。这样才能在测试中更加清晰地表达我们的意思。















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









