






拼音搜索目前在中文搜索领域应用非常广泛。看了一些同行的文章,基本上是做n-gram算法切分子串,然后根据同义词的原理,搜索相关的词。这样在保证查全率的同时,在精度上有不小的损失。个人的理解是这样,在建立索引的阶段,用拼音组件将汉字转换成拼音,然后用正则去完成拼音字符的提取。比如zhangsanfeng,提取出三个词,zhang,san,feng;在查询的阶段,首先判断用户的输入符合不符合拼音的规则,如果符合,则进行正则的提取,如果不符合,则直接用IK分词器进行常规的分词。
一个让人措手不及的问题是,在Lucene当中,分词器进行分词,是通过Reader流进行处理的,如果要判断用户的输入符合不符合拼音规则,则需要完整的读完整个Reader的内容。比如zhangsanfeng是符合拼音规则的,而zhangsf则不符合,一个需要使用PatternTokenizer来处理,一个需要使用IKTokenizer来处理,同时进行Reader的复位(reset)。不幸的是,Lucene中内部使用的ReusableStringReader类是final类型的,reset()并没有重载,也就是不支持复位的功能。当然,可以使用BufferedReader来进行包装。而且,更关键的问题是,在Lucene当中,不止Reader是复用的,Analyzer也是复用的,createComponents()方法则在初始化时调用一次,把正则的处理放在createComponents()里并不合适,而Analyzer的很多方法都是final的,也就是没有办法进行覆盖。总之单纯写一个Analyzer并不合适。
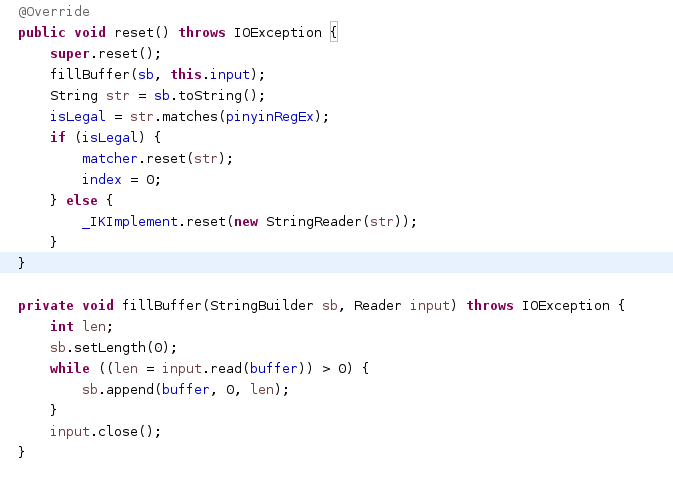
因此仿照IKTokenizer,自己写了一个PinyinTokenizer类,在reset()方法中完成Reader的读取,拼音正则的判断。
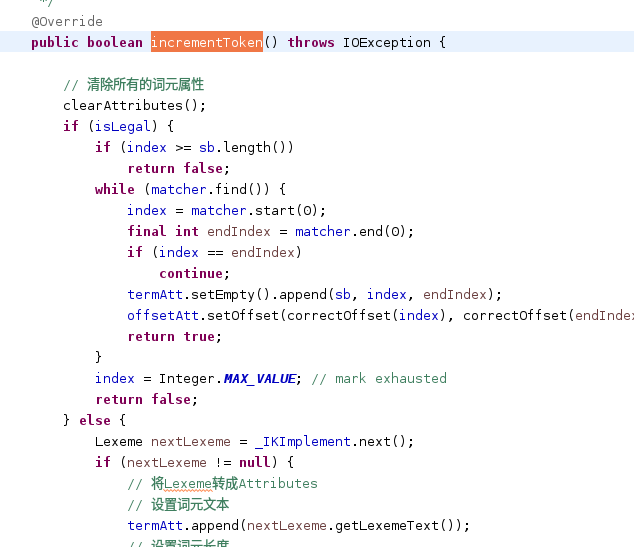
在incrementToken方法中,完成词元属性的设置、拼音分词,IK常规分词等操作。
完整的PinYinAnalyzer类
public class PinYinAnalyzer extends Analyzer {
/**
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName, final Reader input) {
return new TokenStreamComponents(new PinYinTokenizer(input));
}
}完整的PinYinTokenizer类
public class PinYinTokenizer extends Tokenizer {
// IK分词器实现
private IKSegmenter _IKImplement;
// 词元文本属性
private final CharTermAttribute termAtt;
// 词元位移属性
private final OffsetAttribute offsetAtt;
// 词元分类属性(该属性分类参考org.wltea.analyzer.core.Lexeme中的分类常量)
private final TypeAttribute typeAtt;
// 记录最后一个词元的结束位置
private int endPosition;
private final StringBuilder sb = new StringBuilder();
private final char[] buffer = new char[8192];
private boolean isLegal;
private int index;
private Matcher matcher;
private Pattern pattern;
public String pinyinSegRegEx = "[^aoeiuv]?h?[iuv]?(ai|ei|ao|ou|er|ang?|eng?|ong|a|o|e|i|u|ng|n)?";
public String pinyinRegEx = "(a[io]?|ou?|e[inr]?|ang?|ng|[bmp](a[io]?|[aei]ng?|ei|ie?|ia[no]|o|u)|pou|me|m[io]u|[fw](a|[ae]ng?|ei|o|u)|fou|wai|[dt](a[io]?|an|e|[aeio]ng|ie?|ia[no]|ou|u[ino]?|uan)|dei|diu|[nl](a[io]?|ei?|[eio]ng|i[eu]?|i?ang?|iao|in|ou|u[eo]?|ve?|uan)|nen|lia|lun|[ghk](a[io]?|[ae]ng?|e|ong|ou|u[aino]?|uai|uang?)|[gh]ei|[jqx](i(ao?|ang?|e|ng?|ong|u)?|u[en]?|uan)|([csz]h?|r)([ae]ng?|ao|e|i|ou|u[ino]?|uan)|[csz](ai?|ong)|[csz]h(ai?|uai|uang)|zei|[sz]hua|([cz]h|r)ong|y(ao?|[ai]ng?|e|i|ong|ou|u[en]?|uan)|\\s)+";
public PinYinTokenizer(Reader in) {
super(in);
pattern = Pattern.compile(pinyinSegRegEx);
matcher = pattern.matcher("");
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
_IKImplement = new IKSegmenter(input, true);
}
/*
* (non-Javadoc)
*
* @see org.apache.lucene.analysis.TokenStream#incrementToken()
*/
@Override
public boolean incrementToken() throws IOException {
// 清除所有的词元属性
clearAttributes();
if (isLegal) {
if (index >= sb.length())
return false;
while (matcher.find()) {
index = matcher.start(0);
final int endIndex = matcher.end(0);
if (index == endIndex)
continue;
termAtt.setEmpty().append(sb, index, endIndex);
offsetAtt.setOffset(correctOffset(index), correctOffset(endIndex));
return true;
}
index = Integer.MAX_VALUE; // mark exhausted
return false;
} else {
Lexeme nextLexeme = _IKImplement.next();
if (nextLexeme != null) {
// 将Lexeme转成Attributes
// 设置词元文本
termAtt.append(nextLexeme.getLexemeText());
// 设置词元长度
termAtt.setLength(nextLexeme.getLength());
// 设置词元位移
offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition());
// 记录分词的最后位置
endPosition = nextLexeme.getEndPosition();
// 记录词元分类
typeAtt.setType(nextLexeme.getLexemeTypeString());
// 返会true告知还有下个词元
return true;
}
// 返会false告知词元输出完毕
return false;
}
}
/*
* (non-Javadoc)
*
* @see org.apache.lucene.analysis.Tokenizer#reset(java.io.Reader)
*/
@Override
public void reset() throws IOException {
super.reset();
fillBuffer(sb, this.input);
String str = sb.toString();
isLegal = str.matches(pinyinRegEx);
if (isLegal) {
matcher.reset(str);
index = 0;
} else {
_IKImplement.reset(new StringReader(str));
}
}
private void fillBuffer(StringBuilder sb, Reader input) throws IOException {
int len;
sb.setLength(0);
while ((len = input.read(buffer)) > 0) {
sb.append(buffer, 0, len);
}
input.close();
}
@Override
public final void end() {
int finalOffset = correctOffset(this.endPosition);
offsetAtt.setOffset(finalOffset, finalOffset);
}















 3623
3623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









