






第一次写博客,自己其实是一知半懂,写下来便于记录自己学习的过程,便于以后回顾温习,有许多不完善的地方,也遇到了许多的问题,希望大神们多多指教
1.环境: Python3 +Selenium2+Pyunit+Chrome
2.主要实现 1.登入,2异常截图,3生成报表,4发送邮件
实现步骤;
1.目录;
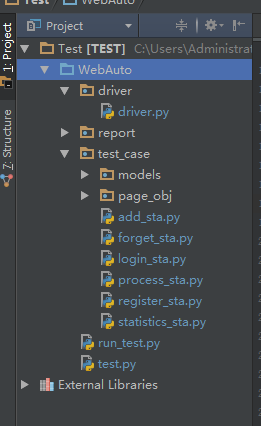
test_case中 models 中放一些功能函数,如截图,数据库操作等
page_obj 中主要放页面元素定位
XXX_sta.py 主要是是基于pyunit 的实现类,如login_sta主要是登入方法,具体后面会讲到
report中主要是report文件。
2.简单的更登入
page_obj 中存放登入界面的元素信息。
1.新建 class login(Page),用By.ID,By.NAME,By.LINK_TEXT,By.XPATH等方式定位各个元素,代码如下。
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
import sys
sys.path.append("C:\\Users\\uni-ubi\\PycharmProjects\\TEST\\WebAuto\\test_case\\page_obj")
from base import Page
from time import sleep
class login(Page):
"""用户登录界面
"""
url ="/"
# Action
login_username_loc= (By.NAME,"email")
login_password_loc=(By.ID,"password")
login_button_loc=(By.LINK_TEXT,"登录")
login_verify_loc=(By.ID,"captcha")
welcome_back_loc=(By.XPATH,"//form[@id='login_form']/div")
# 用户名登入
def login_username(self,username):
self.find_element(*self.login_username_loc).send_keys(username)
# 登入密码
def login_password(self,password):
self.find_element(*self.login_password_loc).send_keys(password)
#鼠标点击用户名
def login_username_click(self):
self.find_element(*self.login_username_loc).click()
#鼠标点击密码
def login_password_click(self):
self.find_element(*self.login_password_loc).click()
#输入验证码
def login_verify(self):
self.find_element(*self.login_verify_loc).send_keys("qqqq")
# 点击登入按钮
def login_button(self):
self.find_element(*self.login_button_loc).click()
#定义统一登入入口
def user_login(self,username="222",password="222"):
"""获取用户名密码登入"""
#登入界面的欢迎回来字样
def welcome_back(self):
return self.find_element(*self.welcome_back_loc).text
def login(self,username,password):
# self.open()
self.login_username(username)
self.login_password(password)
sleep(10)
#self.login_verify()
self.login_button()
sleep(2)
其中发现login集成Page,Page中主要是封装了定位方法。代码如下
class Page(object):
""""页面基础类,用作所有页面的操作"""
bbs_url= "http://XXX/SmartStage-Web/home/"
def __init__(self,selenium_driver,base_url=bbs_url, parent=None):
self.base_url=base_url
self.driver= selenium_driver
self.timeout=30
self.parent=parent
def open(self,url):
url=self.base_url+url
self.driver.get(url)
assert self.on_page(), "Did not land on %s" %url
def find_element(self,*loc):
return self.driver.find_element(*loc)
def find_elements(self, *loc):
return self.driver.find_elements(*loc)
def open(self):
self._open(self.url)
def on_page(self):
return self.driver.current_url == (self.base_url+self.url)
def script(self,src):
return self.driver.execute_script(src)
其实page中还可以优化,可以加入EC中的元素判断和显性等待来减少不必要的时间浪费和出现脚步不稳定的情况。
接下来,我们既然知道了如何获取页面元素,就可以实现登入功能,登入功能我们要结合Pyunit来进行,先看一段代码
import unittest, random ,sys
sys.path.append('C:\\Users\\uni-ubi\\PycharmProjects\\TEST\\WebAuto\\test_case\\')
sys.path.append("./page_obj")
sys.path.append("./models")
sys.path.append("./WebAuto")
from page_obj import base
from page_obj.loginPage import login
from models import myunit,function
class loginTest(myunit.MyTest):
"""登录界面"""
# 测试用户登入
def user_login_verify(self,username,password):
login(self.driver).user_login(username,password)
def test_login1(self):
"""登入 账号为username 密码为password"""
user_login_verify(self,"username","password")
function.insert_img(self.driver,"1.2.8 password_correct05.jpg")
loginTest继承myunit.MyTest,MyTest 继承unittest.TestCase,重写setUp()和tearDown()方法,在Pyunit中 ,执行test_case之前都会先执行setUp(),setUp中实现打开firefox然后登入URL, tearDown在test_case执行后执行,用quit实现退出。
from selenium import webdriver
import sys
sys.path.append("C:\\Users\\uni-ubi\\PycharmProjects\\TEST\\WebAuto\\driver")
from driver import browser
import unittest
import time
import os
class MyTest(unittest.TestCase):
def setUp(self):
# self.driver = browser()
self.driver=webdriver.Firefox()
self.driver.implicitly_wait(10)
self.driver.maximize_window()
self.driver.get("http://XXXXX/SmartStage-Web/admin/employee/index")
def tearDown(self):
time.sleep(2)
self.driver.quit()
再转过来看 loginTest中test_login1,user_login_verify(self,"username","password")主要是调用page_obj.loginPage中的login方法实现输入用户名,密码和点击确认按钮,然后function.insert_img(self.driver,"1.2.8 password_correct05.jpg") 主要是实现截图功能,代码如下:
from selenium import webdriver
import os
def insert_img(driver, file_name):
base_dir= os.path.dirname(os.path.dirname(__file__))
base_dir=str(base_dir)
base_dir=base_dir.replace("\\","/")
base= base_dir.split("/test_case")[0]
file_path=base+"/report/image/"+file_name
print(file_path)
driver.get_screenshot_as_file(file_path)
os.path.dirname(__file__)表示当前目录如
C:\\Users\\uni-ubi\\PycharmProjects\\TEST\\WebAuto\\test_case\\models
os.path.dirname(os.path.dirname(__file__)) 表示当前目录的上一级目录,如
C:\\Users\\uni-ubi\\PycharmProjects\\TEST\\WebAuto\\test_case\\
file_path= C:/Users/uni-ubi/PycharmProjects/TEST/WebAuto/test_case/ +/report/image/
最后存放截图
driver.get_screenshot_as_file(file_path)
这就是先了截图然后存放指定路径的功能,现在的截图截的图不分是正确的截图还是异常的截图,后期慢慢优化通过装饰实现异常截图存放。
总体的流程大致写完,接下来就是跑case生成报表,然后发送邮件。先看代码 然后慢慢解释
from email.mime.multipart import MIMEMultipart
from HTMLTestRunner import HTMLTestRunner
from email.mime.text import MIMEText
from email.header import Header
import smtplib
import time
import unittest
import os
import sys
sys.path.append("C:\\Users\\uni-ubi\\PycharmProjects\\TEST\\WebAuto\\test_case\\")
import add_sta
#==========定义发送邮件=========
def send_mail(new_file):
print(new_file)
f = open(new_file,"rb")
mail_body = f.read()
f.close()
msg =MIMEText(mail_body,"html","utf-8")
# msg["Content-Type"]='application/octet-stream'
# msg["Content-Disposition"]='attachment,filename="uni-ubi.html"'
# msgRoot=MIMEMultipart('related')
# subject="登录界面自动化测试报告"
# msg["Subject"]=subject
msg["Subject"]=Header("登录界面自动化测试报告","utf-8")
# msgRoot.attach(msg)
msg['From'] = "自动化<qq741562314@126.com>"
msg['To'] = "741562314@qq.com"
smtp=smtplib.SMTP()
smtp.connect("smtp.126.com")
smtp.starttls()
print("126邮箱登入前")
smtp.login("qq741562314@126.com","XXXX")
print("126邮箱登入成功")
smtp.sendmail("qq741562314@126.com","741562314@qq.com",msg.as_string())
print("126发送邮件成功")
smtp.quit()
print("mail has send out")
#=====================查找测试报告目录,找到最新生产的测试报告文件====================
def new_report(testreport):
lists=os.listdir(testreport)
lists.sort(key=lambda fn:os.path.getatime(testreport + "\\" +fn))
file_new=os.path.join(testreport,lists[-1])
print(testreport)
print(file_new)
return file_new
if __name__=="__main__":
now= time.strftime("%Y-%m-%d %H_%M_%S")
file_name="./report/" + now + "result.html"
fp= open(file_name,"wb")
runner =HTMLTestRunner(stream=fp,title="UniUbi登入测试报告",description="环境:W8,浏览器:firefox")
# discover=unittest.defaultTestLoader.discover("./test_case/",pattern="*_sta.py")
#
# runner.run(discover)
#单个测试用例运行
suite= unittest.TestSuite()
suite.addTest(add_sta.addTest("test_add1"))
runner.run(suite)
fp.close()
file_path=new_report("./report/")
send_mail(file_path)
先从if __name__=="__main__": 这边开始,这个就像java 中的main方法一样是入口,file_name 再./report/下按时间给报表赋名称,用HTMLTestRunner 来生成报表样式,discover 代表按搜索执行用例,规则是./test_case/文件下,*_sta.py以_sta.py结尾的用例都跑起来,执行成功后会在./report/下生成报表,然后通过new_report获取目录下最新的报表,最后send_mail(file_path)发送mail。
总体实现了1.登入,2异常截图,3生成报表,4发送邮件, 但是代码还需要持续优化,
1.登入数据不需要通过手动输入,通过excel,txt,数据库等导入
2.提取系统参数配置xml文件中,以便于修改,如数据库参数等
3.加入日志判断机制,以便获取异常
4.加入装饰函数获取每次异常截图
5.多线程或者用Gird实现firefox,chrome等并行。
6.配置持续集成一遍自动执行
7。等等等等等需要优化的东西















 3441
3441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









