






1、Elasticsearch的打分公式
Elasticsearch的默认打分公式是lucene的打分公式,主要分为两部分的计算,一部分是计算query部分的得分,另一部分是计算field部分的得分,下面给出ES官网给出的打分公式:
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q)
queryNorm(q):
对查询进行一个归一化,不影响排序,因为对于同一个查询这个值是相同的,但是对term于ES来说,必须在分片是1的时候才不影响排序,否则的话,还是会有一些细小的区别,有几个分片就会有几个不同的queryNorm值
queryNorm(q)=1 / √sumOfSquaredWeights
上述公式是ES官网的公式,这是在默认query boost为1,并且在默认term boost为1 的情况下的打分,其中
sumOfSquaredWeights =idf(t1)*idf(t1)+idf(t2)*idf(t2)+...+idf(tn)*idf(tn)
其中n为在query里面切成term的个数,但是上面全部是在默认为1的情况下的计算,实际上的计算公式如下所示:
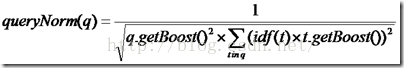
coord(q,d):
coord(q,d)是一个协调因子它的值如下:
coord(q,d)=overlap/maxoverlap
其中overlap是检索命中query中term的个数,maxoverlap是query中总共的term个数,例如查询词为“无线通信”,使用默认分词器,如果文档为“通知他们开会”,只会有一个“通”命中,这个时候它的值就是1/4=0.25
tf(t in d):
即term t在文档中出现的个数,它的计算公式官网给出的是:
tf(t in d) = √frequency
即出现的个数进行开方,这个没什么可以讲述的,实际打分也是如此
idf(t):
这个的意思是出现的逆词频数,即召回的文档在总文档中出现过多少次,这个的计算在ES中与lucene中有些区别,只有在分片数为1的情况下,与lucene的计算是一致的,如果不唯一,那么每一个分片都有一个不同的idf的值,它的计算方式如下所示:
idf(t) = 1 + log ( numDocs / (docFreq + 1))
其中,log是以e为底的,不是以10或者以2为底,这点需要注意,numDocs是指所有的文档个数,如果有分片的话,就是指的是在当前分片下总的文档个数,docFreq是指召回文档的个数,如果有分片对应的也是在当前分片下召回的个数,这点是计算的时候与lucene不同之处,如果想验证是否正确,只需将分片shard的个数设置为1即可。
t.getboost():
对于每一个term的权值,没仔细研究这个项,个人理解的是,如果对一个field设置boost,那么如果在这个boost召回的话,每一个term的boost都是该field的boost
norm(t,d):
对于field的标准化因子,在官方给的解释是field越短,如果召回的话权重越大,例如搜索无线通信,一个是很长的内容,但都是包含这几个字,但是并不是我们想要的,另外一个内容很短,但是完整包含了无线通信,我们不能因为后面的只出现了一次就认为权重是低的,相反,权重应当是更高的,其计算公式如下所示:
其中d.getboost表明如果该文档权重越大那么久越重要


f.getboost表明该field的权值越大,越重要
lengthnorm表示该field越长,越不重要,越短,越重要,在官方文档给出的公式中,默认boost全部为1,在此给出官方文档的打分公式:
norm(d) = 1 / √numTerms
以上的是理论上的,看看实际例子
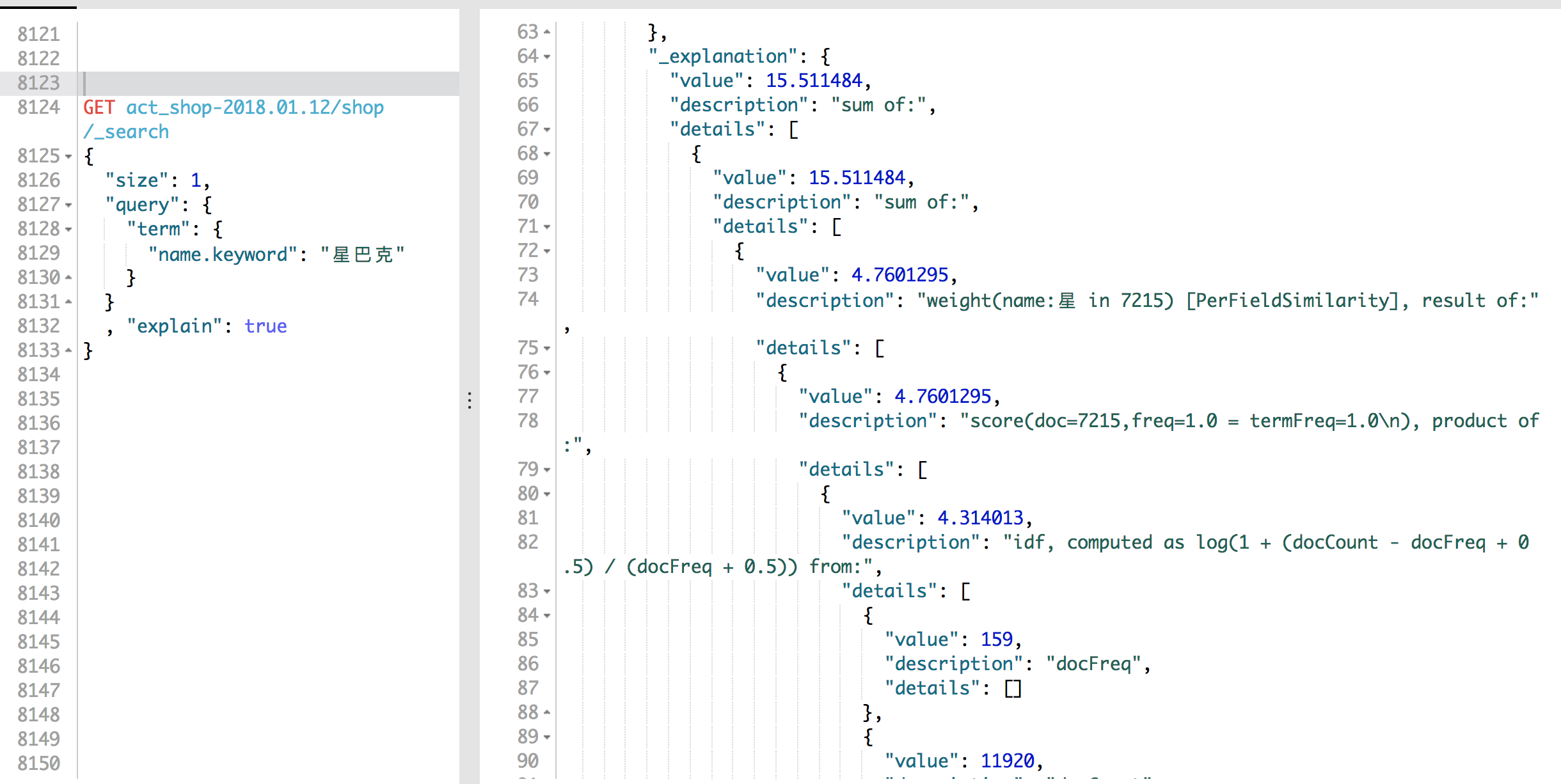
GET act_shop-2018.01.12/shop/_search
{
"size": 1,
"query": {
"term": {
"name.keyword": "星巴克"
}
}
, "explain": true
}
结果是
{
"took": 25,
"timed_out": false,
"_shards": {
"total": 150,
"successful": 150,
"failed": 0
},
"hits": {
"total": 127667,
"max_score": 15.511484,
"hits": [
{
"_shard": "[act_shop-2018.01.12][80]",
"_node": "6vfIeV95QOK1vAcLdx6CEA",
"_index": "act_shop-2018.01.12",
"_type": "shop",
"_id": "187672",
"_score": 15.511484,
"_routing": "36341",
"_parent": "36341",
"_source": {
"status": 1,
"city": {
"id": 2084,
"name": "虹口区"
},
"update_time": "2017-10-23 15:23:00.329000",
"tel": [
"021-65200108"
],
"name": "星巴克(凉城店)",
"tags": [
"餐饮服务",
"咖啡厅",
"咖啡厅"
],
"tags_enrich": {
"name": "美食",
"id": 10
},
"id": 187672,
"label": "have_act",
"create_time": "2017-01-11 14:59:43.950000",
"city_enrich": {
"region": "华东地区",
"name": "上海",
"level": 1
},
"address": "车站南路330弄2号、6号第一、二层的4839F01059",
"coordinate": {
"lat": 31.29496,
"lon": 121.475442
},
"brand": {
"id": 490,
"name": "星巴克"
}
},
"_explanation": {
"value": 15.511484,
"description": "sum of:",
"details": [
{
"value": 15.511484,
"description": "sum of:",
"details": [
{
"value": 4.7601295,
"description": "weight(name:星 in 6914) [PerFieldSimilarity], result of:",
"details": [
{
"value": 4.7601295,
"description": "score(doc=6914,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 4.314013,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 159,
"description": "docFreq",
"details": []
},
{
"value": 11920,
"description": "docCount",
"details": []
}
]
},
{
"value": 1.103411,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 9.224329,
"description": "avgFieldLength",
"details": []
},
{
"value": 7.111111,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
},
{
"value": 5.0423846,
"description": "weight(name:巴 in 6914) [PerFieldSimilarity], result of:",
"details": [
{
"value": 5.0423846,
"description": "score(doc=6914,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 4.5698156,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 123,
"description": "docFreq",
"details": []
},
{
"value": 11920,
"description": "docCount",
"details": []
}
]
},
{
"value": 1.103411,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 9.224329,
"description": "avgFieldLength",
"details": []
},
{
"value": 7.111111,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
},
{
"value": 5.70897,
"description": "weight(name:克 in 6914) [PerFieldSimilarity], result of:",
"details": [
{
"value": 5.70897,
"description": "score(doc=6914,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 5.173929,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 67,
"description": "docFreq",
"details": []
},
{
"value": 11920,
"description": "docCount",
"details": []
}
]
},
{
"value": 1.103411,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 9.224329,
"description": "avgFieldLength",
"details": []
},
{
"value": 7.111111,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
]
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "_type:shop, product of:",
"details": [
{
"value": 1,
"description": "boost",
"details": []
},
{
"value": 1,
"description": "queryNorm",
"details": []
}
]
}
]
}
]
}
}
]
}
}详细说明一下
1、在 "_shard": "[act_shop-2018.01.12][80]"这个分片里,按照es的标准分词,当match'星巴克'的时候,然后会分词为'星','巴','克'这三个词。每个词的得分为:
'星':4.7601295
'巴':5.0423846
'克':5.70897
总的得分:4.7601295+5.0423846+5.70897=15.511484
2、然后每个词是怎么得分的,这里详细说一下,以'星'为例:
sorce'星'=idf.tfNorm(也就是词频*逆向词频)
idf计算如下:
{
"value": 4.7601295,
"description": "score(doc=6914,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 4.314013,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 159,
"description": "docFreq",
"details": []
},
{
"value": 11920,
"description": "docCount",
"details": []
}
]
}docFreq:在这个分片里,击中'星'的文档数量:159
docCount:在这个分片里,包括总的文档数量:11920
公式:log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))=4.314013
tfNorm计算如下
tf可以理解为,这个'星',在某个文档里出现的次数的一些占比
{
"value": 1.103411,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 9.224329,
"description": "avgFieldLength",
"details": []
},
{
"value": 7.111111,
"description": "fieldLength",
"details": []
}
]
}tfNorm=(freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength))=1.103411
所以sorce'星'=idf.tfNorm=4.314013*1.103411=4.7601295















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









