






spark依赖环境
1. jdk 1.8
2. scala 2.11
3. hadoop 2.7(本文用mongodb取代Hadoop HDFS,不需要安装)
安装JDK
略。。
安装Scala
Scala官网地址:http://www.scala-lang.org
选择2.11版本下载
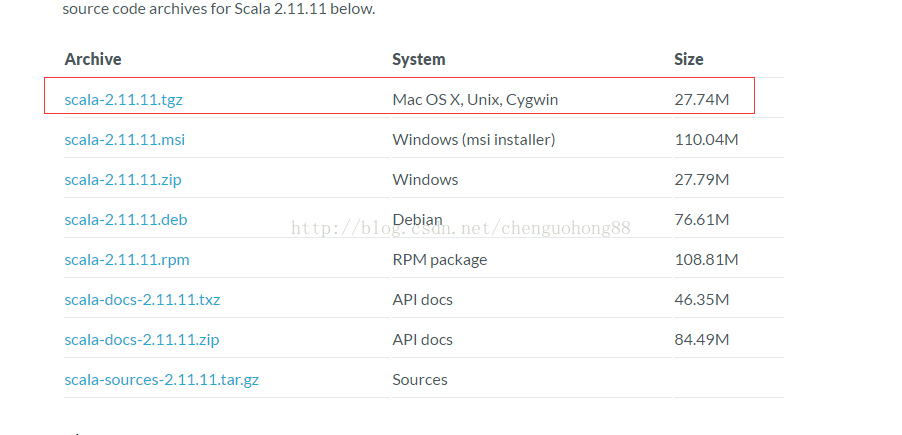
解压:
tar -zxf scala-2.11.11.tgz
配置环境变量:
vim /etc/profile
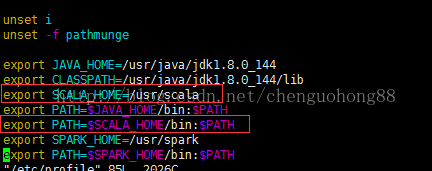
使配置生效:
source /etc/profile
验证是否安装成功:
scala -version

安装spark
spark 下载地址: http://spark.apache.org/downloads.html
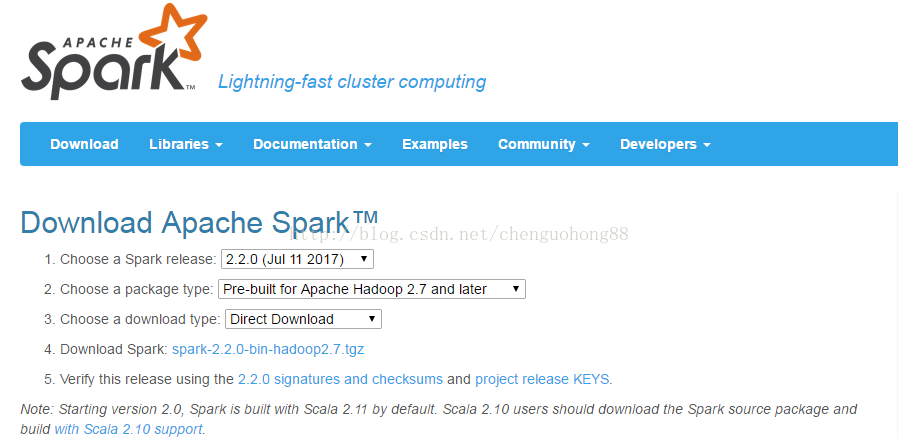
这里可以看到spark默认构建于Scala2.11,依赖Hadoop2.7
安装过程与Scala类似,解压缩:
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
配置环境变量:

配置spark:
进入spark安装目录conf, 执行命令:
1. cp spark-env.sh.template spark-env.sh
2. vim spark-env.sh
在文件最后加入jdk, scala环境变量

启动spark:
进入spark安装目录sbin,执行命令:
./start-all.sh
验证:

安装mongodb
略..
mongo-spark
文本使用mongo官方的mongo-spark连接器,连接spark、mongodb。
mongo-spark github地址: https://github.com/mongodb/mongo-spark?jmp=hero。
mongo-spark使用非常简单,使用时将mongo-spark包引入即可。下面使用spark-shell测试连接是否成功。
spark连接mongodb
进入spark安装目录bin, 执行以下命令:
spark-shell
--conf "spark.mongodb.input.uri=mongodb://localhost:27017/dbName.collectionName?authSource=admin" //mongodb数据源
--conf "spark.mongodb.output.uri=mongodb://localhost:27017/dbName.collectionName?authSource=admin" //使用mongodb保存分析后的数据
--packages org.mongodb.spark:mongo-spark-connector_2.10:2.2.0 //引入mongo-spark包
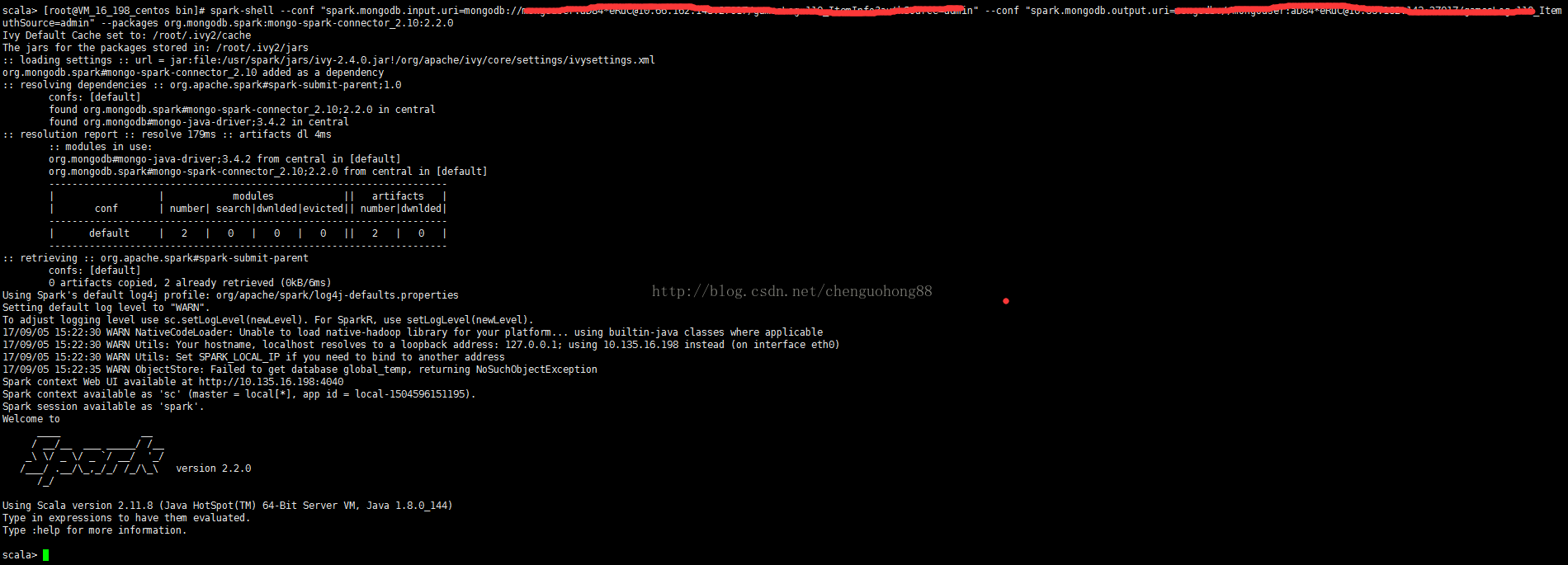
使用mongo-spark查询数据:
import com.mongodb.spark._
import org.bson.Document
MongoSpark.load(sc).take(10).foreach(println)

成功返回数据,说明spark连接mongodb成功。
本文到此结束。后续将继续研究基于spark+mongodb架构的大数据分析。















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









