






java中io流主要有两大类,分别是字节流和字符流,字节流主要是以字节形式来读取数据,理论上来将字节流可以读取任意形式的文件。这一节就来介绍字节流
输入字节流父类InputStream
InputStrem是是一个抽象类,所以需要使用子类来进行实例化,下面介绍常用的子类。
直接子类FileInputStream
- A FileInputStream从文件系统中的文件获取输入字节。 什么文件可用取决于主机环境。
- FileInputStream用于读取诸如图像数据的原始字节流。 要阅读字符串,请考虑使用FileReader。
read()方法
read()方法每一次读取一个字节
package top.Stream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class ioDemo1 {
public static void main(String[] args) throws IOException {
InputStream inputStream = new FileInputStream("xxx.txt");
int i;
i = inputStream.read();
System.out.println(i);
i = inputStream.read();
System.out.println(i);
i = inputStream.read();
System.out.println(i);
i = inputStream.read();
System.out.println(i);
}
}
其中这里xxx.txt是在当前项目根目录下:里面内容为ab,输出结果如下:
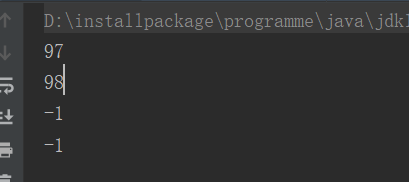
这里可以看到最后两次都是返回-1,是因为已经读到了文件末尾。当没有文件内容的时候返回的就是-1。
为什么read()方法返回的是int类型而不是byte类型呢
上面可以看到read()方法返回的是int类型,而不是byte类型,但是读取的却是按照字节来读取,这是由于文件结束标志为-1导致的。,比如现在读取的是一个视频,如果每次返回的是byte类型,那么读到内容为 11111111(-1的补码)时就会以为是读完了,实际上这可能是正常的内容,此时就会出现文件读到一半就不再读取的问题,所以返回时都是使用int类型,比如读到了11111111, 返回int时就是返回 00000000 00000000 00000000 11111111(一共四个字节),然后在使用OutputStream去写入的时候会自动将前面的三个字节去掉。这样就不会出现问题。
read(byte[])
上面是一个字节一个字节的读取,这样速度会比较慢,而read(byte[])方法则可以一次性读取多个字节,依然是上面的例子“
public class ioDemo1 {
public static void main(String[] args) throws IOException {
InputStream inputStream = new FileInputStream("xxx.txt");
int i;
byte[] arr = new byte[4];
i = inputStream.read(arr);
System.out.println(i);
System.out.println(arr[0]);
}
}
这里输出结果是2 97,因为我们的文件内容是ab,只有两个字节,所以read(byte[])方法的返回值是读取到的有效字节数,arr是读取到的内容。
输出字节流父类OutPutStream
- 这个抽象类是表示字节输出流的所有类的超类。 输出流接收输出字节并将其发送到某个接收器。
- 需要定义OutputStream子类的应用OutputStream必须至少提供一个写入一个字节输出的方法。
直接子类FileOutputStream
- FileOutputStream用于写入诸如图像数据的原始字节流。 对于写入字符流,请考虑使用FileWriter 。
package top.Stream;
import java.io.*;
public class ioDemo1 {
public static void main(String[] args) throws IOException {
FileInputStream inputStream = new FileInputStream("xxx.txt");
FileOutputStream outputStream = new FileOutputStream("aaa.txt");
int i;
while((i = inputStream.read()) != -1){
outputStream.write(i);
}
inputStream.close();
outputStream.close();
}
}
write(int)方法
writer()方法是与read方法相对应的,read是每一次读取一个字节,write是每一次写入一个字节,所以这里可以边读编写,读取到的值为-1的时候结束。
使用追加的方式
上面write方法去写的时候每一次都是先将内容清空(文件已存在则是清空,如果要写入的文件不存在则是创建文件),但是如果想要以追加的方式来写入的话就需要修改FileOutputStream的构造方法。
FileOutputStream outputStream = new FileOutputStream("aaa.txt", true);
这里是使用两个参数的构造方法,第二个参数为true表示以追加的形式来写入。
文件拷贝
原始方法:使用read()和write()
public static void main(String[] args) throws IOException {
FileInputStream inputStream = new FileInputStream("11.mp3");
FileOutputStream outputStream = new FileOutputStream("copy.mp3");
int i;
while((i = inputStream.read()) != -1){
outputStream.write(i);
}
inputStream.close();
outputStream.close();
}
上面是使用read()方法每次读取一个字节,写入一个字节,这种方式虽然也是可以完成读取和写入的功能,但是效率会很低。
理想方式:使用available()与write(int)
- 返回从此输入流中可以读取(或跳过)的剩余字节数的估计值,而不会被下一次调用此输入流的方法阻塞
package top.Stream;
import java.io.*;
public class ioDemo1 {
public static void main(String[] args) throws IOException {
FileInputStream inputStream = new FileInputStream("11.mp3");
FileOutputStream outputStream = new FileOutputStream("copy.mp3");
int i;
i = inputStream.available();
outputStream.write(i);
inputStream.close();
outputStream.close();
}
}
- available()方法可以一次性获取文件有多少个字节,也就是说读取其实就一次。
- write(int)方法是将指定的字节写入,由于【是一次性读取出来的,所以写入其实也就是一次。这种方式很快,因为读取和写入磁盘各只有一次,但是这种方式也是有问题的,因为读取内容要放入内存,如果读取的文件太大,内存空间不足也就不行,所以这种方式不是理性的方式。
折中方式:定义小数组拷贝(标准方式)
package top.Stream;
import java.io.*;
public class ioDemo1 {
public static void main(String[] args) throws IOException {
FileInputStream inputStream = new FileInputStream("11.mp3");
FileOutputStream outputStream = new FileOutputStream("copy.mp3");
byte[] arr = new byte[1024];
int len;
while((len = inputStream.read(arr)) != -1) {
outputStream.write(arr, 0, len);
}
inputStream.close();
outputStream.close();
}
}
read(byte[] b)
- 从该输入流读取最多 b.length个字节的数据为字节数组。 上面拷贝读取时使用的方法是read(byte[] b),该方法是读取与定义的字节数组大小相等的字节数,返回值是读取的有效的内容的长度,读取的内容放入到定义的数组中,若返回-1表示读取到文件末尾。
write(byte[] b, int off, int len)
- 将 len字节从位于偏移量 off的指定字节数组写入此文件输出流 输出时使用的是上面的方法,而不是直接使用write(int)。
BufferedInputStream与BufferedOutputStream
- BufferedInputStream是FilterInputStream的子类,这是一个使用缓冲区的类。
- BufferedOutputStreamFilterOutputStream的子类,也是一个使用缓冲区的类。
package top.Stream;
import java.io.*;
public class ioDemo1 {
public static void main(String[] args) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("11.mp3"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.mp3"));
int len;
while((len = bis.read()) != -1) {
bos.write(len);
}
bis.close();
bos.close();
}
}
上面是使用了BufferedInputStream的read()方法和BufferedOutputStream的write(int len)的方法,这两个方法与inputStream和outputStream里面的对应的方法含义是相同的。不同的是使用带有缓冲区的类的时候默认定义了需要读取的内容的大小: 
BufferedInputStream的构造方法有两个:

如果我们没有给定一个大小那么使用的就是默认的大小,如果给定了就是使用我们给定的大小。 所以上面的read()方法看起来是没有给参数,好像是一次读取一个字节,其实不是的,如果没有给读取的长度那么一次读取的就是8192个长度的字节数。这也是为什么使用缓冲区的输入流比较快的原因。
定义字节数组与使用bufferedInputStream的比较
上面使用了定义数组的拷贝形式,也使用了带有缓冲器的BufferedInputStream的读取方式,那么哪一种方式更快呢?如果定义的字节数组的长度也是8192的话,那么肯定是定义字节数组要快一点点,至于这里说的快一点点可以看下下面的图:
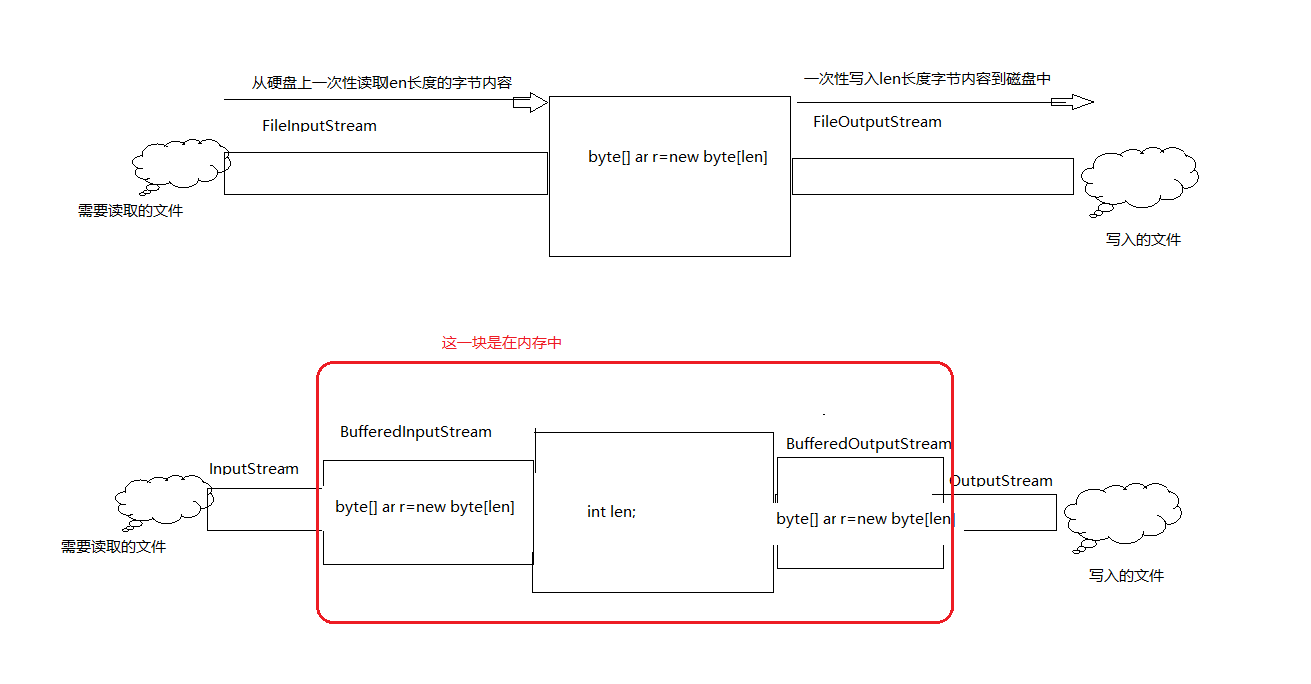
可以看到使用了缓冲区,其实是对原始的输入流和输出流进行了增强,也就是一次性读取的比较多,读取到缓冲区后再从缓冲器写入,而不是直接用开始的流进行读取和写入,那为什么使用8192字节的数组去读取的时候要比使用缓冲器更快一点点呢,这是因为如果从硬盘上读取的长度是一样的时候,缓冲区中还需要将读取的内容往int中放,然后拿出来给到写入缓冲区,这多出来的读取和写入是在内存中完成的,所以速度是很快的,但是肯定会比没有这个步骤的时候要慢一点点。
blush()与close()
- blush()方法是刷新缓冲区
- close()方法是关闭流 先看一个例子
package top.Stream;
import java.io.*;
public class ioDemo1 {
public static void main(String[] args) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("11.mp3"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.mp3"));
int len;
while((len = bis.read()) != -1) {
bos.write(len);
}
bis.close();
}
}
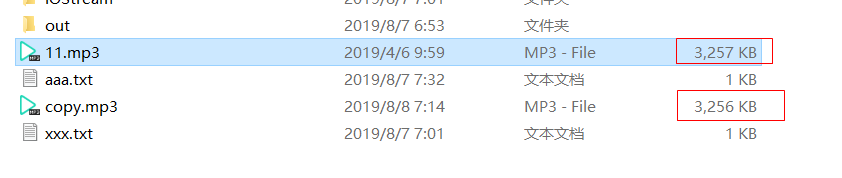
上面的代码中没有关闭输出流,看到拷贝的文件中比原始文件要小,这是因为使用了带有缓冲区的流,使用缓冲区的时候,缓冲区是有大小的,只有缓冲区满了才会自动往硬盘中写入数据,如果没有满就不会往硬盘里面写入数据,所以读取到最后一次的时候可能就会有问题,因为读取到的内容不一定刚刚与缓冲区内容大小相同,所以最后一部分可能就没有写入到硬盘中,此时就需要使用flush()方法
flush()
该方法是用来将缓冲区的内容强制写入到硬盘中
package top.Stream;
import java.io.*;
public class ioDemo1 {
public static void main(String[] args) throws IOException {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("11.mp3"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.mp3"));
int len;
while((len = bis.read()) != -1) {
bos.write(len);
// bos.flush();
}
bos.flush();
bis.close();
}
}
如果是将flush()方法放入到循环里面,那么每一次读取后都是写入,这样缓冲区的内容即使没有满也是要写入,这种就相当于没有使用缓冲区,放在循环外面就是将最后一次的内容写入到磁盘中,具体使用哪种方式需要看具体需求,如果需要即时写入的就读取后刷新缓冲区。
但是之前也没有使用flush()方法,而且读取出来的内容与原始内容也是没有区别的,这是因为之前输出流关闭了,在关闭输出流的时候是会将缓冲区的内容先写入到磁盘中的。















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









