






什么是二叉查找树?
前面写了一篇介绍二叉树的文章 https://my.oschina.net/u/1587638/blog/834842
二叉树的问题: 二叉树中的节点数据没有任何任何规律, 导致在二叉树中查找数据的时候效率比较低. 于是出现了二叉查找树. 那什么是二叉查找树呢? 用自己的话说: 二叉查找树是一种特殊的二叉树, 二叉查找树的每个节点都大于其左子树节点, 小于其右子树节点.
代码实现
二叉查找树节点
public class BSTNode<T> {
T data;
BSTNode<T> left;
BSTNode<T> right;
BSTNode<T> parent;
public BSTNode(T data, BSTNode<T> left, BSTNode<T> right, BSTNode<T> parent) {
this.data = data;
this.left = left;
this.right = right;
this.parent = parent;
}
}这和前面介绍的二叉树一样, 不同的是树中数据的排序方式.
前序遍历
// 前序遍历
private void preOrder(BSTNode<T> node) {
if (node != null) {
System.out.print(node.data+" ");
preOrder(node.left);
preOrder(node.right);
}
}
public void preOrder() {
preOrder(root);
}中序遍历
// 中序遍历
private void inOrder(BSTNode<T> node) {
if (node != null) {
inOrder(node.left);
System.out.print(node.data + " ");
inOrder(node.right);
}
}
public void inOrder() {
inOrder(root);
}后序遍历
// 后序遍历
private void postOrder(BSTNode<T> node) {
if (node != null) {
postOrder(node.left);
postOrder(node.right);
System.out.print(node.data + " ");
}
}
public void postOrder() {
postOrder(root);
}到此为止, 与前面的二叉树都没有什么区别, 下面开始介绍二叉查找树.
查找
在一般的二叉树中, 我们想实现查找的话只能通过遍历树来实现, 但是这样的做的效率太低了, 由于二叉树满足一定的规律, 利用这个规律, 可以减少遍历的次数.
递归实现
// 查找
private BSTNode<T> contains(BSTNode<T> node, T data) {
if (node == null) {
return null;
}
int cmp = data.compareTo(node);
if (cmp < 0) {
return contains(node.left, data);
} else if (cmp > 0) {
return contains(node.right, data);
} else {
return node;
}
}
public BSTNode<T> contains(T data) {
return contains(root, data);
}非递归实现
// 非递归实现
private BSTNode<T> iterativeContains(BSTNode<T> node, T data) {
while (node != null) {
int cmp = data.compareTo(node.data)
if (cmp < 0) {
node = node.left;
} else if (cmp > 0) {
node = node.right;
} else {
return node;
}
}
return node;
}
public BSTNode<T> iterativeContains(T data) {
return iterativeContains(root, data);
}
查找最大值
// 最大值
private BSTNode<T> findMax(BSTNode<T> node) {
if (node == null) {
return null;
}
while (node.right != null) {
node = node.right;
}
return node;
}
public T findMax() {
BSTNode<T> node = findMax(root);
if (node != null) {
return node.data;
}
return null;
}查找最小值
// 最小值
private BSTNode<T> findMin(BSTNode<T> node) {
if (node == null) {
return null;
}
while (node.left != null) {
node = node.left;
}
return node;
}
public T findMin() {
BSTNode<T> node = findMax(root);
if (node != null) {
return node.data;
}
return null;
}前驱和后继
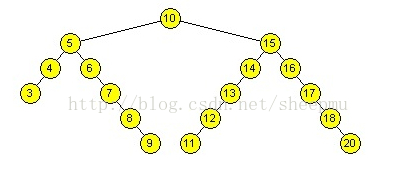
首先来解释一下什么是前驱, 什么是后继.
首先将树中所有的节点按照从小到大排序, 某个节点的前驱就是排在它前面一个的节点, 后继就是排在它后面的节点.
在二叉查找树中, 节点的前驱就是该节点左子树的最大值; 节点的后继就是该节点右子树的最小值.
查找前驱
// 查找前驱
public BSTNode<T> predecessor(BSTNode<T> node) {
// 如果节点为空
if (node == null) {
return null;
}
// 如果该节点有左子树, 那么前驱就是左子树的最大值
if (node.left != null) {
return findMax(node.left);
}
// 如果该节点没有左子树, 那么有2种情况
// 1. 如果node是一个右孩子, 那么node的前驱是它的父节点
// 2. 如果node是一个左孩子, 由二叉查找树的性质可以知道,
// 其前驱一定是其最近的父节点, 且node在这个前驱节点的右子树上(大家思考一下是不是这样的?)
BSTNode<T> parent = node.parent;
while((parent != null) && (node == parent.left)) {
node = parnet;
parent = parent.parent;
}
return parent;
}查找后继
// 查找后继
public BSTNode<T> successor(BSTNode<T> node) {
if (node == null) {
return null;
}
// 如果该节点有右子树, 那么后继就是右子树的最小值
if (node.right != null) {
findMin(node.right);
}
// 如果该节点没有右子树, 那么有2种情况:
// 1. 如果node是一个左孩子, 那么后继就是node的父节点
// 2. 如果node是一个右孩子, 由二叉查找树的性质可以知道
// 其前驱一定是其最近的父节点, 且node在这个前驱节点的左子树上(大家思考一下是不是这样的?)
BSTNode<T> parent = node.parent;
while((parent != null) && parent.right == node) {
node = parent;
parent = parent.parent;
}
return parent;
}插入
- 若当前的二叉查找树为空,则插入的元素为根节点
- 若插入的元素值小于根节点值,则将元素插入到左子树中
- 若插入的元素值不小于根节点值,则将元素插入到右子树中。首先找到插入的位置,要么向左,要么向右,直到找到空结点,即为插入位置,如果找到了相同值的结点,插入失败。
// 插入
public void insert(T data) {
// 新建节点
BSTNode<T> node = new BSTNode<T>(data,null,null,null);
if (node != null)
root = insert(root, node);
}
/**
* 递归版
*/
private BSTNode<T> insert(BSTNode<T> node, BSTNode<T> insert) {
if (node == null) {
node = insert;
}
int cmp = insert.data.compareTo(node.data);
if (cmp < 0) {
node.left = insert(node.left, insert);
node.left.parent = node;
} else if(cmp > 0) {
node.right = insert(node.right, insert);
node.right.parent = node;
}
return node;
}
// 非递归版
private void insert(BSTNode<T> node, BSTNode<T> insert) {
if (root == null) {
root = insert;
return;
}
int cmp = 0;
// 记录父节点
BSTNode<T> p = null;
while (node != null) {
p = node;
cmp = insert.data.compareTo(node.data);
if (cmp < 0) {
node = node.left;
} else if (cmp > 0) {
node = node.right;
} else {
return;
}
}
insert.parent = p;
if (cmp < 0) {
p.left = insert;
}else if (cmp > 0) {
p.right = insert;
}
}删除
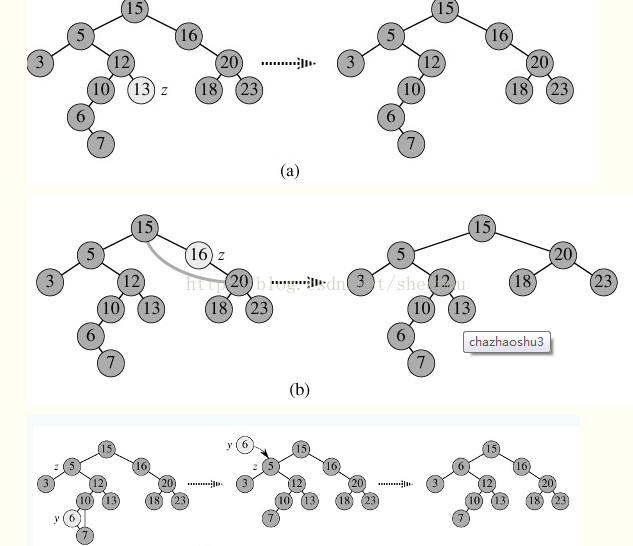
二叉查找树的删除,分三种情况进行处理:
- p为叶子节点,直接删除该节点,再修改其父节点的指针(注意分是根节点和不是根节点),如图a。
- p为单支节点(即只有左子树或右子树)。让p的子树与p的父亲节点相连,删除p即可;(注意分是根节点和不是根节点);如图b。
- 有两个孩子的情况,当前结点与左子树中最大的元素交换,然后删除当前结点。左子树最大的元素一定是叶子结点,交换后,当前结点即为叶子结点,删除参考没有孩子的情况。另一种方法是,当前结点与右子树中最小的元素交换,然后删除当前结点。如图c。
public void remove(T data) {
remove(root, data);
}
// 递归实现
private BSTNode<T> remove(BSTNode<T> node, T data) {
if (node == null) {
return null;
}
int cmp = data.compareTo(node.data);
if (cmp < 0) {
node.left = remove(node.left, data);
} else if (cmp > 0) {
node.right = remove(node.right, data);
} else if (node.left != null && node.right != null) {
node.data = findMin(node.right).data;
node.right = remove(node.right, node.data);
} else {
BSTNode<T> p = node.parent;
if (node.left != null) {
node = node.left;
} else {
node = node.right;
}
node.parent = p;
}
return node;
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









