








船长今天晚上加班到很晚,拖着疲惫的身体到家,本想今天偷个懒一天,但是想到我那些个可爱的粉丝以及那些将要关注我的小可爱,所以我就肝了个集合【List、Set、Map】,分开来讲解集合,一篇太太太长了,容易给大家引起视觉疲劳。
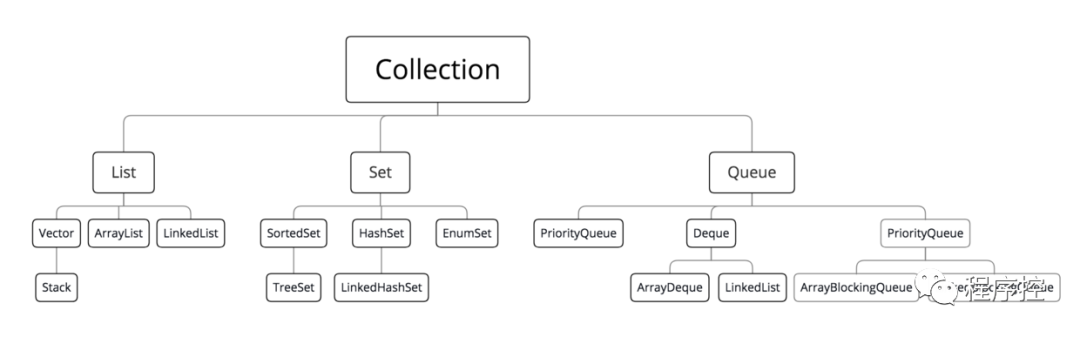
先给大家看下Collection接口,下面有List和Set接口继承于集合Collection接口(Map接口和Collection接口没关系哦)
由于船长想给大家贴些源码来分析,所以一篇文章肯定肝不完,这一篇主要肝ArrayList,下面继续肝~

无论是工作中还是面试中,集合可以说是最最常见的了,我就不信你在校招时没被问过集合,我就不信你在工作中用不到集合,就是不信。\
了解
Collection和Map是两个高度抽象的接口:
- Collection抽象的是集合,包含了集合的基本操作和属性,Collection主要包含List和Set两大分支。
- List是有序的链表,允许存储重复的元素,List的主要实现类有LinkedList, ArrayList, Vector, Stack。
- Set是不允许存在重复元素的集合,Set的主要实现类有HastSet和TreeSet(依赖哈希实现,后面介绍)。
集合是Java中用来存储多个对象的一个容器,我们知道容器数组,数组长度不可变,且只能存储同样类型的元素,可以存储基本类型或者引用类型。而集合长度可变,可以存储不同类型元素(但是我们一般不这么干),集合只能存储引用类型(基本类型会变成包装类)。
集合的fail-fast机制和fail-safe机制:
- fail-fast快速失败机制,一个线程A在用迭代器遍历集合时,另个线程B这时对集合修改会导致A快速失败,抛出ConcurrentModificationException 异常。在java.util中的集合类都是快速失败的。
- fail-safe安全失败机制,遍历时不在原集合上,而是先复制一个集合,在拷贝的集合上进行遍历。在java.util.concurrent包下的容器类是安全失败的,建议在并发环境下使用这个包下的集合类。
fail-fast快速失败是通过在遍历过程中使用一个modCount变量,每次遍历之前会检查modCount变量是否和预期的值一样,是的话遍历,不一样抛出异常,终止遍历。
List接口
public interface List<E> extends Collection<E> { }
上面是定义,继承Collection接口,是集合的一种。
List的特点是可存储重复元素,存储有序(存储顺序和取出顺序一致)
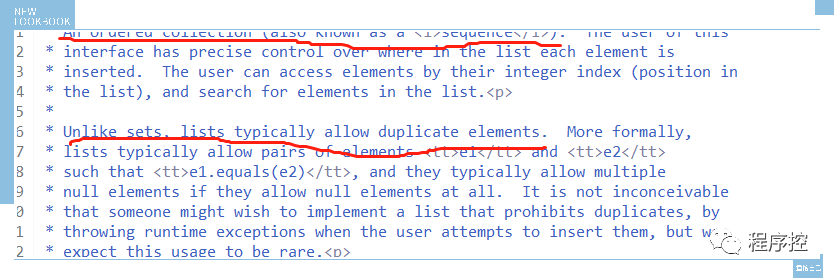
List集合常用子类:
-
ArrayList:底层是数组,线程不安全;
-
LinkedList:底层是双向链表,线程不安全;
-
Vector:底层是数组,线程安全
-
Stack:底层是数组,继承于Vector,线程安全;
Arraylist
ArrayList定义:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable { }
ArrayList简介:
-
ArrayList是实现List接口的可变数组,并允许null在内的重复元素;
-
底层数组实现,扩容时将老数组元素拷贝到新数组中,每次扩容是其容量的1.5倍,操作代价高;
-
采用了Fail-Fast机制,面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险;\
-
ArrayList是线程不安全的,所以在单线程中才使用ArrayList,而在多线程中可以选择Vector或者CopyOnWriteArrayList。\
-

ArrayList核心函数:
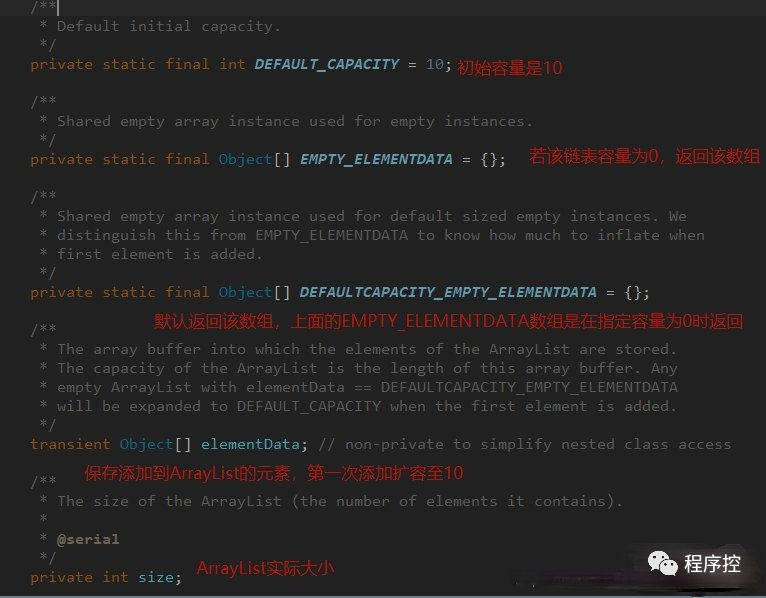
我们先来看下内部属性~
(看上面水印修图,不要怀疑我不是原创,只是P图较烂)
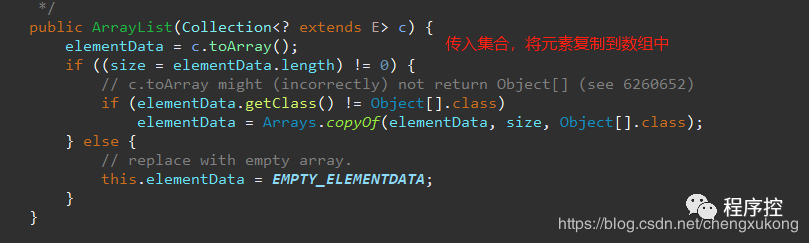
构造函数(了解即可)

接下来我们看add方法(重点),加入链表元素
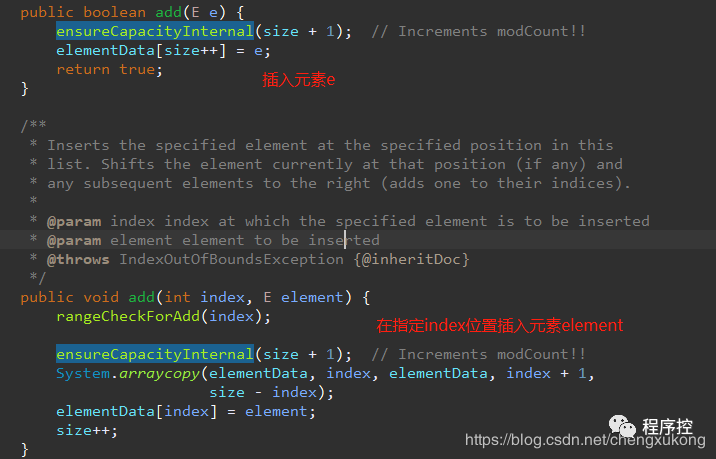
先来分析第一个函数****add(E e) ****:

我们进去****ensureCapacityInternal() ****看:
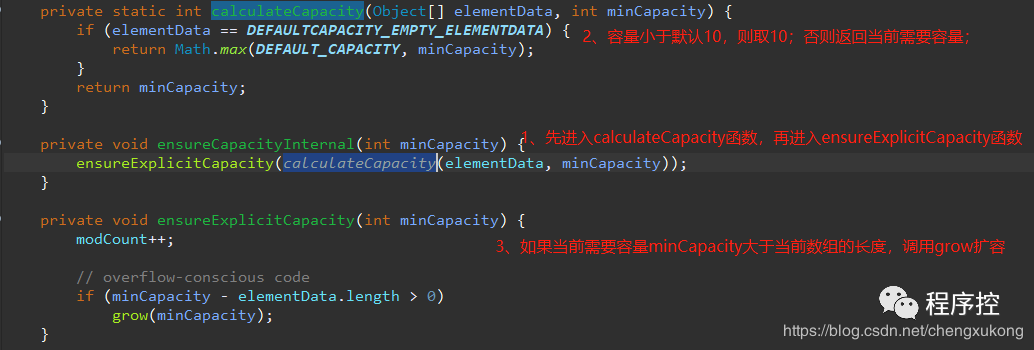
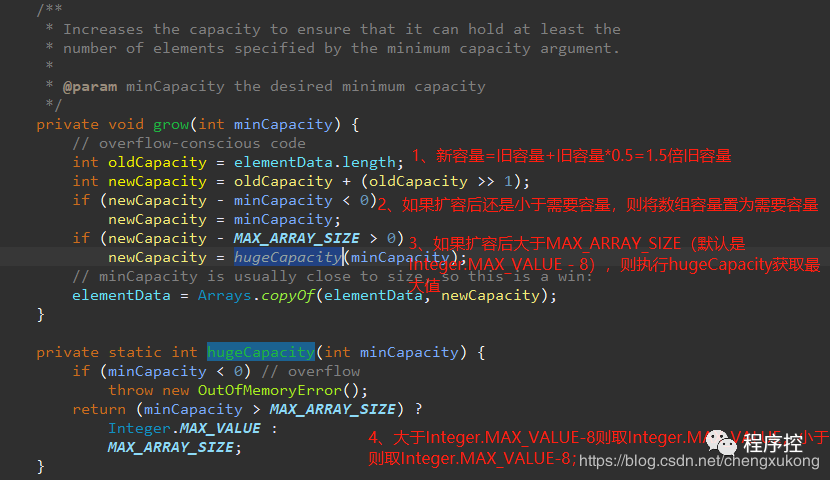
执行完第三步,如果需要******扩容******,则进入grow()方法:
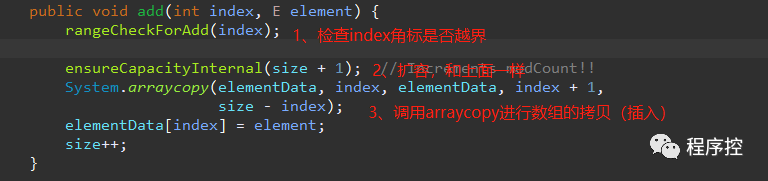
再来分析第二个******add(int index,E element):******
总结:在add函数中调用函数ensureCapacityInternal,此函数为确保elementData数组有合适的大小,如果需要容量小于10,则数组容量为10;如果需要扩容,则正常每次以1.5倍旧容量扩容,第一次扩容后,如果容量还是小于minCapacity,就将容量扩充为minCapacity。特殊情况下(新扩展数组大小已经达到了最大值)则只取最大值(一般用不到那么大)。
set()方法,在特定位置设置元素,看源码

get()方法,获得指定位置元素

indexOf()方法,从首位置开始查找数组中是否存在指定元素,并返回位置下标。
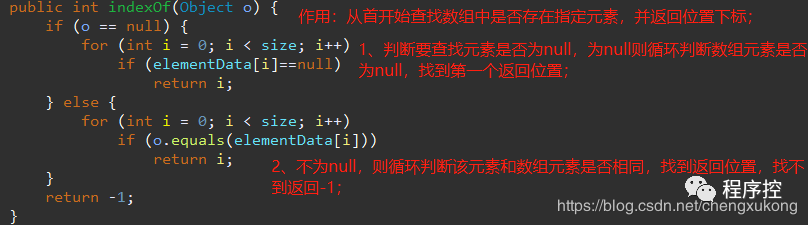
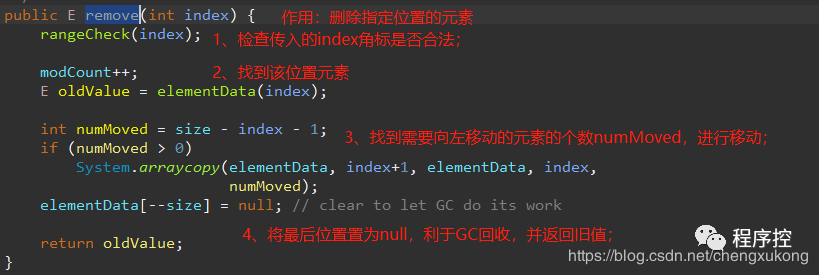
remove()方法,删除指定位置元素。
重点关注问题:
ArrayList默认大小(为什么是这个?),扩容机制?
ArrayList的默认******初始化大小是10******(在新建的时候还是空,只有当放入第一个元素的时候才会变成10),若知道ArrayList的大致容量,可以在初始化的时候指定大小,可以在适当程度减少扩容的性能消耗(看下一个问题解析)。
至于为何是10,据说是因为sun的程序员对一系列广泛使用的程序代码进行了调研,结果就是10这个长度的数组是最常用的最有效率的。
也有说就是随便起的一个数字,8个12个都没什么区别,只是因为10这个数组比较的圆满而已。
ArrayList的扩容机制是:
当添加元素的时候数组是空的,则直接给一个10长度的数组。当需要长度的数组大于现在长度的数组的时候,通过新=旧+旧>>1(即******新=1.5倍******的旧)来扩容,当扩容的大小还是不够需要的长度的时候,则将数组大小直接置为需要的长度(这一点切记!)。
ArrayList特点访问速度块,为什么?插入删除一定慢吗?适合做队列吗?
ArrayList从结构上来看属于数组,也就是内存中的一块连续空间,当我们get(index)时,可以直接根据数组的首地址和偏移量计算出我们想要元素的位置,我们可以直接访问该地址的元素,所以查询速度是O(1)级别的。
我们平时会说ArrayList插入删除这种操作慢,查询速度快,其实也不是绝对的。
当数组很大时,插入删除的位置决定速度的快慢,假设数组当前大小是一千万,我们在数组的index为0的位置插入或者删除一个元素,需要移动后面所有的元素,消耗是很大的。
但是如果在数组末端index操作,这样只会移动少量元素,速度还是挺快的(插入时如果在加上数组扩容,会更消耗内存)。
个人觉得不太适合做队列,基于上面的分析,队列会涉及到大量的增加和删除(也就是移位操作),在ArrayList中效率还是不高。
ArrayList 底层实现就是数组,访问速度本身就很快,为何还要实现 RandomAccess ?
RandomAccess是一个空的接口, 空接口一般只是作为一个标识, 如Serializable接口.。
JDK文档说明RandomAccess是一个标记接口(Marker interface), 被用于List接口的实现类, 表明这个实现类支持快速随机访问功能(如ArrayList). 当程序在遍历这中List的实现类时, 可以根据这个标识来选择更高效的遍历方式。
ArrayList是线程不安全的,为什么?怎么办?
ArrayList线程不安全的表现是在多个线程进行add操作时可能会导致elementData数组越界。
发生在什么情况呢?
我们可以想象,一个线程A调用add()方法,获取到size大小是9,调用ensureCapacityInternal方法进行容量判断,此时线程B也进入add()方法,也一样获取到9并进行容量判断。线程A发现不需要扩容返回,此时线程B也返回不需要容纳返回。线程A如果先进行插入元素之后,线程B如果再执行 elementData[size++] = e便会出现数组越界的现象。
如何解决呢?
- 使用synchronized关键字,锁起来,效率较低。(也可以自己实现ArrayList的子类,并进行同步操作)
- 使用Vector,内部函数基本都是通过synchronized关键字实现,所以是线程安全的。这种方式严重影响效率,所以并不推荐使用Vector。
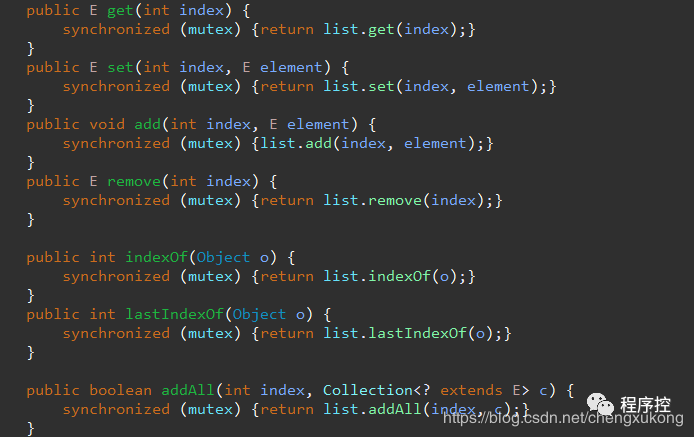
- 使用Collections.synchronizedList(new ArrayList()) ;下图是部分截图,可以很多函数是通过加synchronized关键字+mutex原子锁实现的,效率还行。
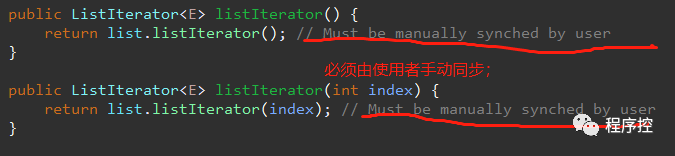
使用Collections.synronizedList还存在一些小问题,就是使用迭代器的时候需要手动同步,因为在整个迭代的过程中如果在循环外面不加同步代码,在一次次迭代之间,其他线程对于这个容器的add或者remove会影响整个迭代的预期效果,所以需要用户在整个循环外面加上Synchronized(list)。
- 使用CopyOnWriteArrayList(属于Java的并发包下面的工具),运用的是一种“写时复制”的思想。
通俗的理解就是当我们需要修改(增/删/改)列表中的元素时,不直接进行修改,而是先将列表Copy,然后在新的副本上进行修改,修改完成之后,在将引用从原列表指向新列表。
这样做的好处是读/写是不会冲突的,可以并发进行,读操作还是在原列表,写操作在新列表。仅仅当有多个线程同时进行写操作时,才会进行同步。
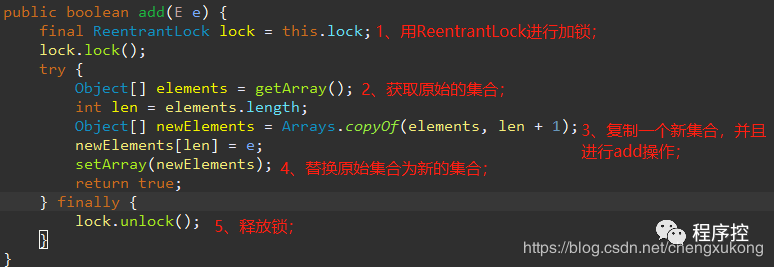
如上面的add操作,使用了ReentrantLock独占锁,保证同时只有一个线程对集合进行修改操作(支持重入)。
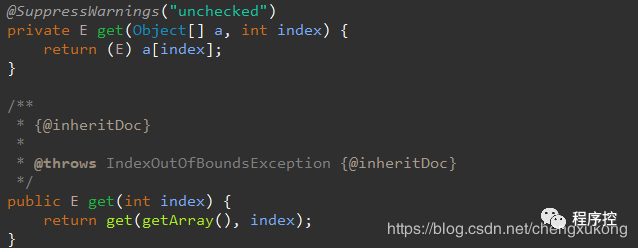
看上图的get操作,获取元素并没有加锁,这样做的好处是,在高并发情况下,读取元素时就不用加锁,写数据时才加锁,大大提升了读取性能。
CopyOnWriteArrayList 在使用迭代器时底层是一种安全失败机制,不过迭代器获取的数据取决于迭代器创建的时候,而不是迭代器迭代的时候,接下来我们来看看为何。

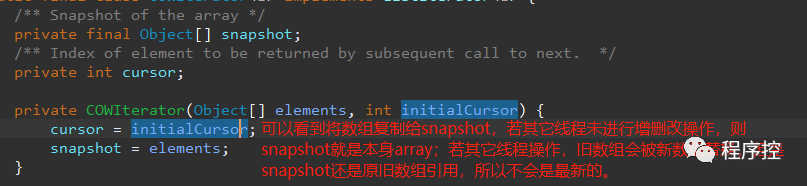
ArrayList中的elementData为何要加transient关键字修饰?
为何要加transient关键字修饰,transient关键字的作用来表示一个域不是对象序列化的一部分,当一个对象被序行化的时候,transient修饰的变量的值是不包括在序行化的表示中的。
但是ArrayList本身是可以序列化的,elementData是存放ArrayList中具体元素的成员数据,那是不是意味着反序列化之后ArrayList丢失了元素?
玄机在writeObject和readObject两个方法中,我们一起看看:

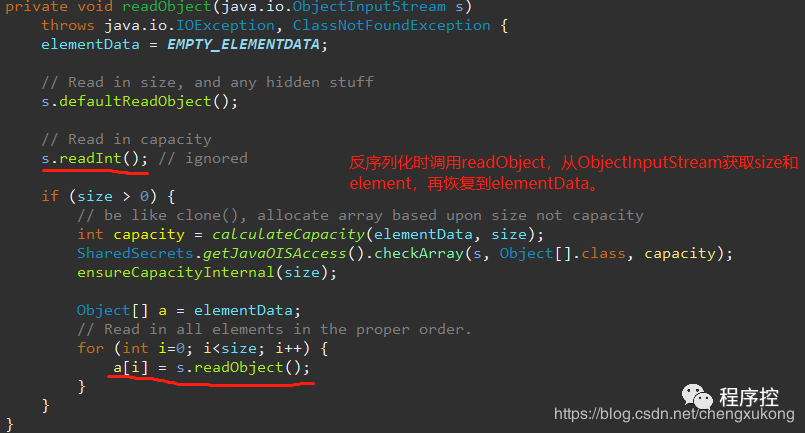
ArrayList在序列化的时候会调用writeObject,直接将size和element写入ObjectOutputStream;反序列化时调用readObject,从ObjectInputStream获取size和element,再恢复到elementData。
为什么不直接用elementData来序列化,而采用上诉的方式来实现序列化呢?
原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
ArrayList的遍历?迭代时不允许修改?
1、for循环遍历:
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
for (int i = 0; i < list.size(); i++) {
if ("1".equals(list.get(i))) {
list.add("4");
list.add("5");
list.remove("1");
}
System.out.println(list.get(i));
}
结果:不报错,打印2 3 4 5;
2、使用 foreach 遍历:
List<String> list2 = new ArrayList<>();
list2.add("1");
list2.add("2");
list2.add("3");
for (String s : list2){
if ("1".equals(s)){
list2.add("4");
list2.remove("1");
}
System.out.println(s);
}
结果:抛出 java.util.ConcurrentModificationException异常;
3、使用 Iterator 迭代器:
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
if ("1".equals(iterator.next())) {
//iterator.remove();
list.add("4");
list.remove("1");
} }
结果:抛出 java.util.ConcurrentModificationException异常;
解释下:逻辑上讲,迭代时可以添加元素,但是一旦开放这个功能,很有可能造成很多意想不到的情况。
比如你在迭代一个 ArrayList,迭代器的工作方式是依次返回给你第0个元素,第1个元素,等等,假设当你迭代到第5个元素的时候,你突然在ArrayList的头部插入了一个元素,使得你所有的元素都往后移动,于是你当前访问的第5个元素就会被重复访问。
java 认为在迭代过程中,容器应当保持不变。
因此,java 容器中通常保留了一个域称为 modCount,每次你对容器修改,这个值就会加1。当你调用 iterator 方法时,返回的迭代器会记住当前的 modCount,随后迭代过程中会检查这个值,一旦发现这个值发生变化,就说明你对容器做了修改,就会抛异常。接下来我们通过Iterator迭代器简单分析下:
先看AbstractList中的iterator():

看Itr对象中的next()的实现:
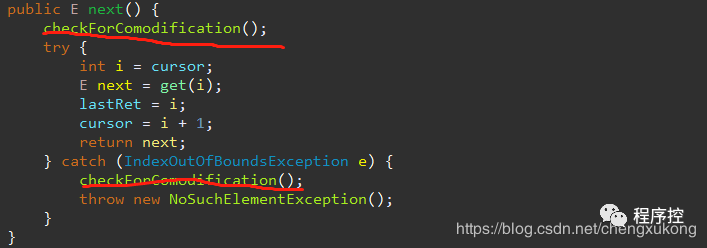
modCount表示集合的元素被修改的次数,每次增加或删除一个元素的时候,modCount都会加一,而expectedModCount用于记录在集合遍历之前的modCount,检查这两者是否相等就是为了检查集合在迭代遍历的过程中有没有被修改,如果被修改了,就会在运行时抛出ConcurrentModificationException这个RuntimeException,以提醒开发者集合已经被修改,这就说明了为什么在集合在使用Iterator进行遍历的时候不能使用集合的本身的add或者remove方法来增减元素。
但是使用Iterator的remove方法是可以的,感兴趣的可以继续去研究源码;
为什么arraylist的最大数组大小设置成Integer.MAX_VALUE - 8
官方解释是:数组作为一个对象,需要一定的内存存储对象头信息,对象头信息最大占用内存不可超过8字节。数组的对象头信息相较于其他Object,多了一个表示数组长度的信息。\
絮叨叨
你知道的越多,你不知道的也越多。
建议:Java基础集合是面试中的宠儿,也是我们工作中最常用的工具类了。很多同学可能会被各种集合以及底层原理搞懵逼,其实大家多用几遍,多看几遍源码,发现,不过如此~

船长希望有一天能够靠写作养活自己,现在还在磨练,这个时间可能会持续很久,但是,请看我漂亮的坚持
感谢大家能够做我最初的读者和传播者,请大家相信,只要你给我一份爱,我终究会还你们一页情的。

船长会持续更新技术文章,和生活中的暴躁文章,欢迎大家关注【Java贼船】,成为船长的学习小伙伴,和船长一起乘千里风、破万里浪
哦,对了!后续的更新文章我都会及时放到Java成神之路,欢迎大家点击观看,都是干货文章啊,建议收藏,以后随时翻阅查看















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









