






最近,文章分享了很多使用技术指标构建的通常交易策略的回测,今天,羊羊看到一篇关于剥皮策略的文章,我们尝试一下这个策略,并在 Python 中进行了回测。
在本文中,我们将介绍如何使用 Python 实现的策略以及如何开发一个策略。因此,我们将首先了解我们的交易策略的一些背景知识,然后我们将进入代码部分,我们将使用 FinancialModelingPrep (FMP) API 获取历史和日内数据,并在 Python 中回测我们的策略。
在深入研究我们的交易策略机制之前,有必要首先对剥头皮交易的概念有一些很好的了解。
剥头皮交易
剥头皮交易是一种非常规的交易方法,交易者旨在从小幅价格变动中获利。例如,跟随剥头皮交易的交易者将以 170 美元的价格购买大量苹果 (AAPL) 股票,并打算以 170.5 美元或 171 美元等非常小的价格卖出股票。
**以小幅价格变化快速卖出股票的原因是每笔交易涉及大量资金。**只有当以巨额资金完成剥头皮交易时,才能看到可观的利润。
交易策略
因此,剥头皮交易的基本思想是从小的价格变化中获利。显然,我们不能将其用作我们的策略,因为它太生硬了,但我们可以做的是将其作为我们交易策略的基础,我们在此基础上创建有效的剥头皮策略。
以下是我们交易策略的机制:
进入市场条件:市场开盘价较前一天收盘价上涨1%。
退出市场条件:股票价格比当天的开盘价买入价上涨 1%。如果股票未能达到其价格的 1% 涨幅,我们将在交易日结束时以收盘价退出。
重要的事情,我们说三遍:我们的目的是:**建一个简单的策略来理解剥头皮交易的本质,而不是依靠这个策略赚钱!(三遍!)
第一步也是最重要的一步是将所有必需的包导入到我们的 Python 环境中。在本文中,我们将使用四个包,它们是:
-
Pandas — 用于数据格式化、清除、操作和其他相关目的
-
Matplotlib — 用于创建图表和不同类型的可视化
-
请求 — 用于进行 API 调用以提取数据
-
Termcolor — 自定义 Jupyter 笔记本中显示的标准输出
-
数学 — 用于各种数学函数和运算
-
NumPy — 用于数值和高级数学函数
以下代码将上述所有包导入到我们的 Python 环境中:
import requests
import pandas as pd
import matplotlib.pyplot as plt
from termcolor import colored as cl
import numpy as np
import math
请确保这些库都正确的进行了安装。
获取股票的历史数据对于回测过程非常重要。为了数据的准确性和可靠性,我们将使用 FinancialModelingPrep (FMP) 的历史数据端点,该端点允许提取任何特定股票的日终数据。我们将对特斯拉股票的剥头皮策略进行回测,以下代码提取了 2014 年初的历史数据:
api_key = 'YOUR API KEY'
tsla_json = requests.get(f'https://financialmodelingprep.com/api/v3/historical-price-full/TSLA?from=2014-01-01&apikey={api_key}').json()
tsla_df = pd.DataFrame(tsla_json['historical']).drop('label', axis = 1)
tsla_df = tsla_df.set_index('date')
tsla_df = tsla_df.iloc[::-1]
tsla_df.index = pd.to_datetime(tsla_df.index)
tsla_df
代码非常简单。我们首先将 API 密钥存储在变量中。请确保替换为您的秘密 API 密钥,您可以在创建 FMP 开发人员帐户后获得该密钥。
然后,使用 Requests 包提供的功能,我们进行 API 调用以获取 TSLA 的历史数据。最后,我们将提取的 JSON 响应转换为可行的 Pandas 数据帧以及一些数据操作。

根据交易策略,如果当天的开盘价比前一天的收盘价高1%,我们就会进入市场。为此,我们首先需要借助获得的历史数据计算价格的百分比变化。以下代码执行相同的操作:
tsla_df['pclose_open_pc'] = np.nan
for i in range(1, len(tsla_df)):
diff, avg = (tsla_df.close[i-1] - tsla_df.open[i]) , (tsla_df.close[i-1] + tsla_df.open[i])/2
pct_change = (diff / avg)*100
tsla_df['pclose_open_pc'][i] = pct_change
tsla_df = tsla_df.dropna().drop(['change', 'changePercent', 'changeOverTime'], axis = 1)
tsla_df = tsla_df[tsla_df.pclose_open_pc > 1]
tsla_df
首先,我们将创建一个新列,用于存储百分比变化值。然后是for循环。这个for循环背后的主要思想是复制Pandas提供的函数的功能。
在for循环的帮助下,我们在这里所做的唯一更改是计算两个不同变量之间的百分比变化。即,当天的开盘价和前一天的收盘价是不可能的,这允许计算单个变量的当前值和旧值之间的百分比变化。
之后,我们删除一些列,并使用一个条件对数据帧进行切片,该条件选择百分比变化大于 1 的行,即当天的开盘价比前一天的收盘价高 1%。
这是所有处理后的最终数据帧:
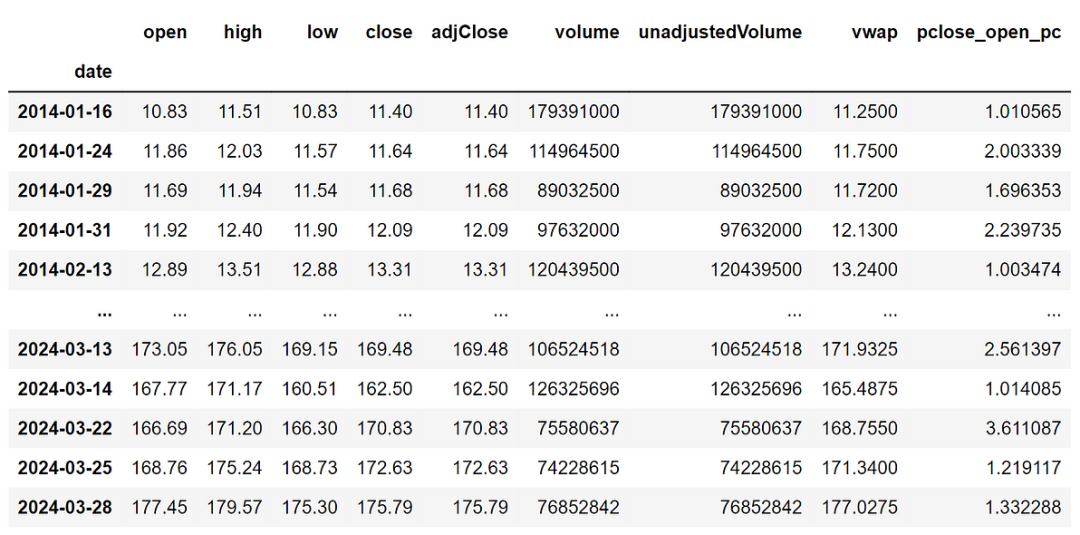
现在我们已经准备好了数据,是时候实际构建和测试我们的剥头皮交易策略了。我们已经到达了本文中最重要和最有趣的步骤之一。现在我们知道了交易策略的来龙去脉,让我们构建它并在 Python 中对其进行回测。为了简单起见,我们将遵循一个非常基本和直接的回溯测试系统。以下代码对剥头皮策略进行了回测:
investment = 100000
equity = investment
earning = 0
earnings_record = []
for i in range(len(tsla_df)):
# EXTRACTING INTRADAY DATA
date = str(tsla_df.index[i])[:10]
intra_json = requests.get(f'https://financialmodelingprep.com/api/v3/historical-chart/1min/TSLA?from={date}&to={date}&apikey={api_key}').json()
intra_df = pd.DataFrame(intra_json)
intra_df = intra_df.set_index(pd.to_datetime(intra_df.date)).iloc[::-1]
# ENTERING POSITION
open_p = tsla_df.iloc[i].open
no_of_shares = math.floor(equity/open_p)
equity -= (no_of_shares * open_p)
# EXITING POSITION
intra_df['p_change'] = np.nan
for i in range(len(intra_df)):
diff, avg = (intra_df.close[i] - open_p), (intra_df.close[i] + open_p)/2
pct_change = (diff / avg)*100
intra_df['p_change'][i] = pct_change
intra_df = intra_df.dropna()
greater_1 = intra_df[intra_df.p_change > 1]
if len(greater_1) > 0:
sell_price = greater_1.iloc[0].close
equity += (no_of_shares * sell_price)
else:
sell_price = intra_df.iloc[-1].close
equity += (no_of_shares * sell_price)
# CALCULATING TRADE EARNINGS
investment += earning
earning = round(equity-investment, 2)
earnings_record.append(earning)
if earning > 0:
print(cl('PROFIT:', color = 'green', attrs = ['bold']), f'Earning on {date}: ${earning}; Bought ', cl(f'{no_of_shares}', attrs = ['bold']), 'stocks at ', cl(f'${open_p}', attrs = ['bold']), 'and Sold at ', cl(f'${sell_price}', attrs = ['bold']))
else:
print(cl('LOSS:', color = 'red', attrs = ['bold']), f'Loss on {date}:
基本上,代码可以分为四个部分(从代码的注释中可以看出):
-
第一个是使用 FMP 的日内数据端点提取我们进入市场时的日内数据。
-
第二部分是我们通过以当天的开盘价买入股票来进入我们的头寸。
-
第三部分是退出头寸的代码,我们首先计算价格变化的百分比,然后在价格上涨 1% 时立即平仓。
-
第四部分专门用于计算每笔交易的收益并将结果打印在输出终端中。
该程序进行了很多交易,虽然不可能显示其中之一,但以下是已执行交易的一瞥:
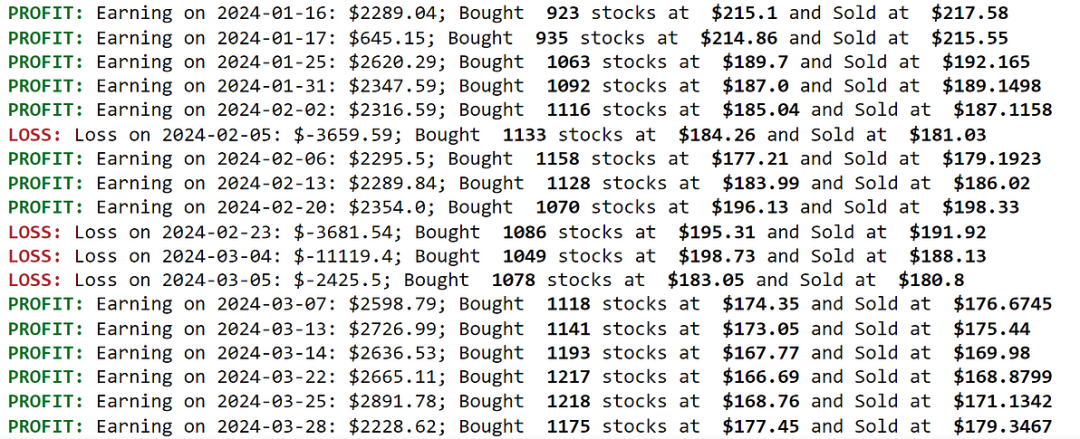
输出包括所有必要的详细信息,例如股票数量、买入价、卖出价、日期和收益。虽然有一些亏损的交易,但大多数是盈利的交易,收益合理。
在本节中,我们将深入探讨该策略的绩效。让我们从策略回报和投资回报率的基本指标开始。以下代码计算策略的总收益和 ROI:
print(cl(f'TSLA BACKTESTING RESULTS:', attrs = ['bold']))
print(' ')
strategy_earning = round(equity - 100000, 2)
roi = round(strategy_earning / 100000 * 100, 2)
print(cl(f'EARNING: ${strategy_earning} ; ROI: {roi}%', attrs = ['bold']))
代码非常简单。我们只是实施了计算总收益和投资回报率 (ROI) 的数学公式,以得出最终数字,这是最终输出:

因此,我们的剥头皮交易策略在十年(2014-2024 年)期间产生了 110 美元的总收入和 110% 的投资回报率。这还不错。
现在让我们使用一些基本指标来评估我们的交易策略。但是为了计算这些指标,让我们首先创建和处理数据:
earnings_df = pd.DataFrame(columns = ['date', 'earning'])
earnings_df.date = tsla_df.index
earnings_df.earning = earnings_record
earnings_df.tail()
此代码的主要目的是创建一个数据帧,其中包含每个交易日策略产生的收益的详细信息。借助我们在回测代码中创建的用于记录收益数据的列表,我们可以轻松地从中创建一个 Pandas 数据帧,这正是我们在代码中所做的。
现在我们有了所需的数据,我们现在可以继续计算评估我们的交易策略的必要指标。在此之前,以下是我们将用于评估的指标列表:
-
最大损失:最差交易的收益
-
最大利润:最佳交易的收益
-
总交易:策略生成的交易总和
-
胜率:策略成功的概率
-
每月平均交易和每月平均收入
以下代码计算上述所有指标:
max_loss = earnings_df.earning.min()``max_profit = earnings_df.earning.max()``no_of_wins = len(earnings_df.iloc[np.where(earnings_df.earning > 0)[0]])``no_of_losses = len(earnings_df.iloc[np.where(earnings_df.earning < 0)[0]])``no_of_trades = no_of_wins+no_of_losses``win_rate = (no_of_wins/(no_of_wins + no_of_losses))*100``print(cl('MAX LOSS:', color = 'red', attrs = ['bold']), f'${max_loss};', `` cl('MAX PROFIT:', color = 'green', attrs = ['bold']), f'{max_profit};', `` cl('TOTAL TRADES:', attrs = ['bold']), f'{no_of_trades};',` `cl('WIN RATE:', attrs = ['bold']), f'{round(win_rate)}%;',` `cl('AVG. TRADES/MONTH:', attrs = ['bold']), f'{round(no_of_trades/120)};',` `cl('AVG. EARNING/MONTH:', attrs = ['bold']), f'${round(strategy_earning/120)}'` `)``plt.style.use('ggplot')``earnings_df.earning.hist()``plt.title('Earnings Distribution')``plt.show()``earnings_df = earnings_df.set_index('date')``earnings_df.earning.cumsum().plot()``plt.title('Strategy Cumulative Returns')``plt.show()
除了计算指标之外,代码中还涉及一些可视化,我们将在一分钟内讨论。这是输出:
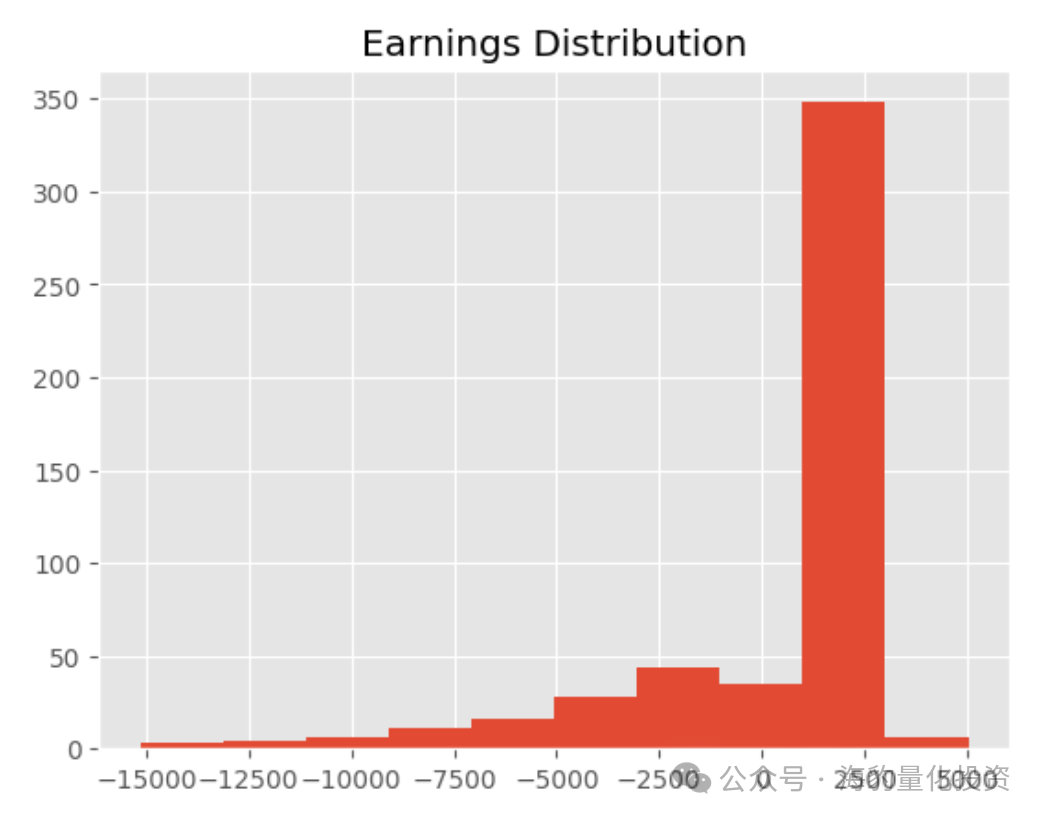

我们先来谈谈指标。最大损失为 $15.1k,而最大利润为 $5K。问题是,最大损失的绝对值总是小于最大利润的绝对值更好,因为它降低了策略的风险。
在十年的时间里,该策略产生的交易总数为 501 笔,一个月内执行的平均交易数量为 4 笔,这同样是合理的交易数量。每月的平均回报率为 923 美元,这是一个可靠的数字。
策略的胜率为74%。这意味着我们的策略有 74% 的机会执行有利可图的交易,胜率大于 50% 的策略被认为是有效且风险较小的。但是,如果没有适当的风险管理系统,这个数字仍然没有任何意义。单纯追求胜率毫无意义。
来到图表,在上面表示的输出中可以看到其中的两个。第一个是直方图,显示了我们策略的收益分布。可以看出,大多数交易产生的收益约为 1500-2500 美元。
第二张图表是折线图,显示我们交易策略的累积回报。首先可以注意到的是线路的不稳定运动。这表明该策略的收益波动很大,这意味着我们的策略在某些情况下是不稳定和有风险的。最好避免图表中可以看到的那些突然下跌。
一个好的交易策略不仅应该能够产生有利可图的回报,而且必须足够有效,必须超越买入/持有策略。对于那些不知道买入/持有策略是什么的人来说,对于tlsa这样的牛股来说,只是持有就能获得非常不错的收益。
如果我们的策略击败了买入/持有策略,可以说我们提出了一个很好的交易策略。然而,如果它不能做到这一点,我们必须对策略进行相当多的改变。
以下代码实现买入/持有策略并计算回报:
max_loss = earnings_df.earning.min()
max_profit = earnings_df.earning.max()
no_of_wins = len(earnings_df.iloc[np.where(earnings_df.earning > 0)[0]])
no_of_losses = len(earnings_df.iloc[np.where(earnings_df.earning < 0)[0]])
no_of_trades = no_of_wins+no_of_losses
win_rate = (no_of_wins/(no_of_wins + no_of_losses))*100
print(cl('MAX LOSS:', color = 'red', attrs = ['bold']), f'${max_loss};',
cl('MAX PROFIT:', color = 'green', attrs = ['bold']), f'{max_profit};',
cl('TOTAL TRADES:', attrs = ['bold']), f'{no_of_trades};',
cl('WIN RATE:', attrs = ['bold']), f'{round(win_rate)}%;',
cl('AVG. TRADES/MONTH:', attrs = ['bold']), f'{round(no_of_trades/120)};',
cl('AVG. EARNING/MONTH:', attrs = ['bold']), f'${round(strategy_earning/120)}'
)
plt.style.use('ggplot')
earnings_df.earning.hist()
plt.title('Earnings Distribution')
plt.show()
earnings_df = earnings_df.set_index('date')
earnings_df.earning.cumsum().plot()
plt.title('Strategy Cumulative Returns')
plt.show()
在上面的代码中,我们再次使用 FMP 的历史数据端点提取 Tesla 的历史数据,因为我们对之前提取的数据进行了一些更改。经过一些数据操作,我们使用简单的数学来计算回报,这是最终的输出:

在比较买入/持有策略和我们的剥头皮交易策略的结果后,买入/持有策略的表现优于我们的,投资回报率相差 333%。这意味着在将剥头皮策略推向市场之前,我们必须在剥头皮策略上做很多工作。
文章提出了交易策略,使用FMP的API获取历史和日内数据,并对策略进行了回测,但我们仍然未能超越买入/持有策略。但本文的目的不是展示借助这些策略的任何赚钱方法,而是对剥头皮交易进行温和的介绍。
如果你真的想把这个策略变成一个高利润的策略,并将其部署到市场上,你可以做一些改进来实现这一目标。首先是调整策略参数。尝试调整进入和退出条件,并测试哪个是交易策略的最佳条件。其次是建立适当的风险管理系统。这是我们在本文中没有介绍的内容,但它非常关键,尤其是当您想将该策略推向现实世界市场时。最后最重要的当然是在A股市场进行模拟盘试盘,要知道大多数在美股看起来有效的策略,放在A股都和开玩笑一样。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









