






摘要
我们将一条查询SQL提交给MySQL之后,MySQL在进行真正的查询操作之前通常会经历两个阶段:SQL解析和查询优化。在SQL解析过程中,MySQL会将SQL解析为一个树状结构,而在查询优化阶段,MySQL会决定以什么方式进行查询,那么MySQL以什么方式进行查询的抉择依据是什么呢?答案就是这篇文章要介绍的MySQL统计信息,因为我厂的MySQL实际使用的是Percona分支,因此本文相关的实验知识是基于Percona分支的。
带着问题
MySQL统计的信息包括什么内容?是用来做什么的?
MySQL统计信息基于表和索引,表和索引是要变化的,那么MySQL是如何保证数据的时效性的?
MySQL的统计机制有什么问题?统计策略如何选择?
MySQL统计信息
存储方式
MySQL获取统计信息之后如何放在那儿呢?统计信息的保存方式有两种,一种是容失性保存,另一种是持久化保存。
持久化存储
innodb_stats_persistent参数用于控制采样信息是否持久化,innodb_stats_persistent=ON的时候,MySQL会将统计信息进行持久化存储,这样当机器数据库重启之后,统计信息依然有效,对于InnoDB存储引起来说,统计信息分别存储在mysql库的下面两张表中:
- innodb_table_stats
- innodb_index_stats
innodb_table_stats存储表维度的统计信息,innodb_index_stats存储索引维度的统计信息。在持久化存储的情况下,当设置为自动更新统计信息的时候且表中有超过10%的数据被更新的时候会执行统计信息的重新计算,而且重新统计不是立即执行的,而是等了一段时间,这个值在MySQL中被定义为MIN_RECAL_INTERVAL=10(秒)。
易失性存储
当innodb_stats_persistent=OFF的时候,MySQL统计信息存储在内存之后,很显然当重启数据库的时候,这些信息会丢失。在易失性存储的情况下,统计信息重新计算的时机和持久化存储方式是不同的,我们来看看哪些条件会触发该情况下统计信息的重新计算:
- 执行ANALYZE TABLE命令
- 执行如下命令:SHOW TABLE STATUS, SHOW INDEX。
- 在innodb_stats_on_metadata选项开启的情况下查询INFORMATION_SCHEMA.TABLES表或INFORMATION_SCHEMA.STATISTICS表
- 通过--auto-rehash参数开启客户端连接,--auto-rehash参数导致InnoDB表被打开,InnoDB表被打开导致统计信息被重新计算
- 表被第一次打开
- 距离上次统计之后,表的1/16的数据被更新
了解在什么方式下统计信息会被重新计算对于数据库的使用优化是有帮助的,比如我们可以破坏一些条件而让事情向着对我们有力的一面发展。
统计内容
MySQL统计信息包括哪些内容呢?MySQL分别从表维度和索引维度构建统计信息。
表统计信息
innodb_table_stats表存储的是表维度的统计信息,innodb_table_stats表有6个字段,他们的各字段相关定义以及含义如下表所示:
| 字段名 | 字段类型 | 字段含义 |
|---|---|---|
| database_name | verchar(64) | 统计信息所属表的数据库名 |
| table_name | verchar(64) | 统计信息所属的表名 |
| last_update | timestamp | 统计信息最后一次更新的时间 |
| n_rows | bigint(20) unsigned | 表所包含的行数 |
| clustered_index_size | bigint(20) unsigned | 聚集索引的页的数量 |
| sum_of_other_index_size | bigint(20) unsigned | 其他索引所占的页的数量 |
我找了一张我们现存的表测试一下:

如上图所示,CL_CommunityNavStatInfo表当前的记录数为5281。

上面我们看到表中实际有5281行数据,但是统计出来的是5228行数据,这是因为什么呢?这个问题留在精度问题部分进行讨论。
索引统计信息
innidb_index_stats表存储的是索引维度的统计信息,innodb_index_stats表有8个字段,他们的各字段相关定义以及含义如下表所示:
| 字段名 | 字段类型 | 字段含义 |
|---|---|---|
| database_name | varchar(64) | 统计信息所属表的数据库名 |
| table_name | varchar(64) | 统计信息所属表名 |
| index_name | varchar(64) | 统计信息所属索引名 |
| last_update | timestamp | 统计信息更新的时间 |
| stat_name | varchar(64) | 统计信息名称 |
| stat_value | bigint(20) unsigned | 统计值 |
| sample_size | bigint(20) unsigned | 采样大小 |
| stat_description | varchar(64) | 统计描述信息 |
我们依然使用上面测试用到的CL_CommunityNavStatInfo表进行测试,先看看CL_CommunityNavStatInfo表的索引定义:

CL_CommunityNavStatInfo表建立了三个索引,我们通过innodb_index_stats表来看看这三个索引的统计信息:
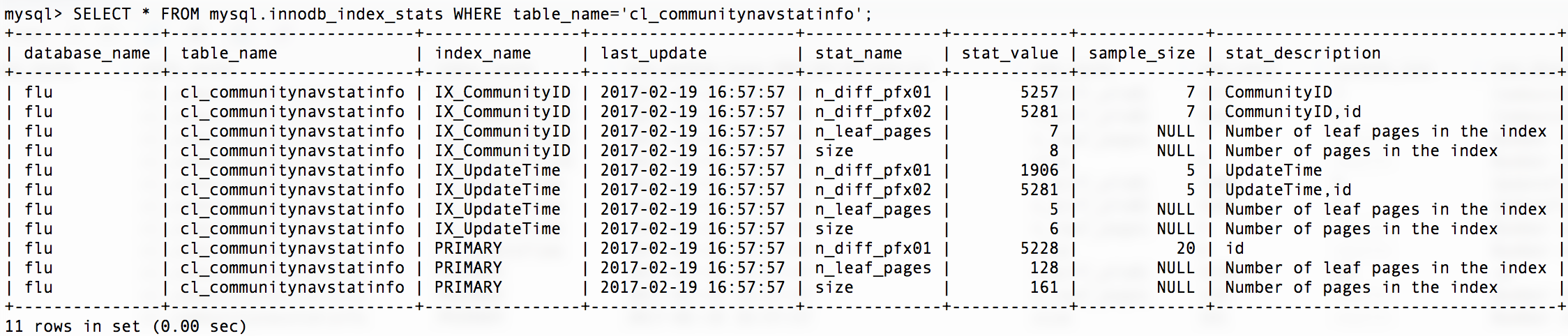
上图为表CL_CommunityNavStatInfo所有索引的统计信息,比如最后一行,size代表主键聚集所以所占页数大小为161,叶子节点所占空大小为128页,id的区分度为5228,这个数字其实也是统计的表的行数,sample_size为20表示采样页数。
精度问题
采样大小
上面提到了sample_size这个数字,其实MySQL的统计数据是基于采样数据估算的,而采样的大小是用户可控的,默认值为20,我们可以通过修改采样大小来控制统计信息的精确性,同时这也会影响性能。比如我们用下面命令将采样大小调整为200:
|
|
200是我们随表挑的一个大于所有数据页数的数字,这样保证统计信息基于全量数据统计,通过ANALYZE TABLE CL_CommunityNavStatInfo;命令重新统计之后,再来看看统计信息:

是不是无比的准确?再继续看看索引的统计信息:
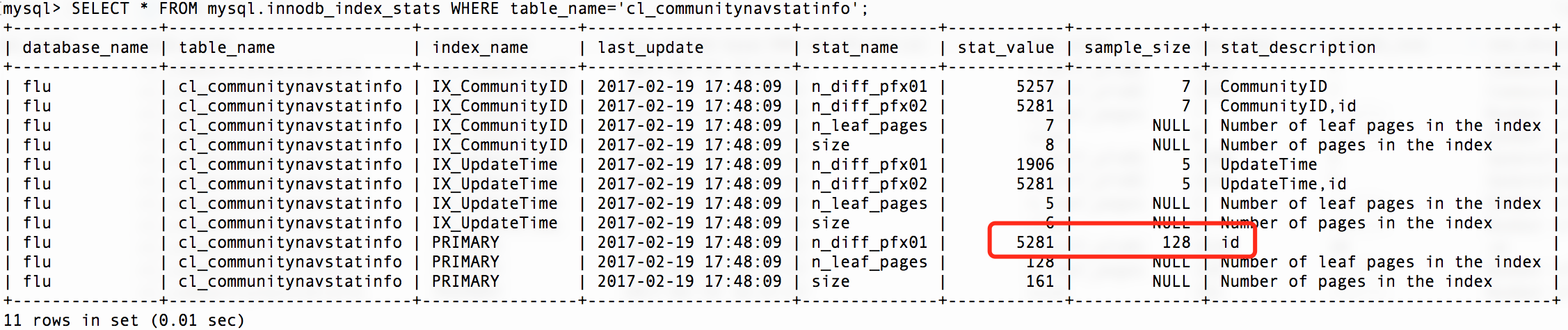
现在的统计信息已经是基于全量的数据统计了,虽然数据准确了,但是我们同时也损失了一部分的性能。
统计时机
定时轮训
统计时机关心的是什么时候进行统计信息的更新。innodb_stats_auto_recalc参数用于控制是否让MySQL自行在需要的时候更新统计信息,当它的值为ON的时候,统计信息的重新计算是异步的,MySQL有一个线程专门用来做这个事情,这个线程每隔10秒钟回去看看要不要进行统计,否则我们需要使用ANALYZE TABLE命令来保证统计信息的时效性。那么我们是选择将统计信息的更新权利完全霸占还是将其授权给MySQL让它自行更新呢?这个问题留给读者思考。
总结
本文分别从MySQL统计信息的存储、内容、精度和统计时机方面对MySQL统计信息进行了一定的学习,了解了MySQL统计信息的相关知识,我认为我们至少可以解决一些实际问题了。比如:
- 我们当前应用的数据源MySQL关于统计方面的配置有没有问题?
- 我们是否可以试着通过调整采样大小来控制统计信息的精确度?从而影响SQL优化器的决策?
- 我们是否可以通过统计信息来估算表中数据所占用的存储空间?
- ……
等等。















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









