






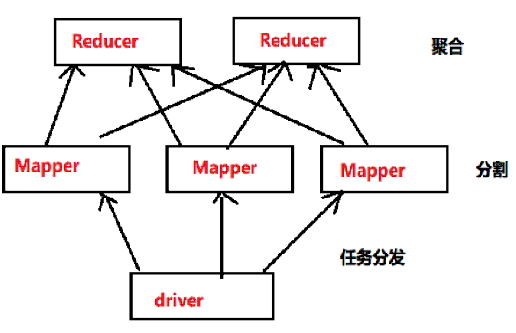
本程序功能是用MapperReducer思想对实时输入的字符串做单词统计。MapperReducer模型如下(图是自己用画图工具画的):
介绍:
Driver主要是用户调用MapperReducer机制的接口,用户将作业构建好调用MapperReducer进行分布式处理。
Mapper主要将作业分割,Reducer则是对分割的作业进行计算并汇聚。
程序说明:程序中有3个组件:Driver、Mapper和Reducer。每个组件即一个Actor,各个Actor之间采用进程间通信来模拟分布式通信。程序代码分5个文件,除三个组件各占一个文件外,还需要为Actor获取IP和端口建立个配置文件conf,另外三个组件间发布的作业任务构成一个文件Task。
代码
Task:
//定义Mapper的Task, 输入是line,即每行数据(String类型),Mfunc函数的功能是将每行的String转换为每个单词的元组类型
case class MapperTask(line:String ,Mfunc:(String)=>List[(String,Int)]) {
}
//定义Reducer的Task,将Mapper传入的每个元组(键值对)进行统计,rfunc功能是取每个键值对的value并累加计算
case class ReducerTask(kv:(String,Int),rfunc:(Int,Int)=>Int){}
Driver文件:
import akka.actor.ActorSystem
import com.typesafe.config.ConfigFactory
import akka.actor.Props
import akka.actor.Actor
import java.util.Scanner
class Driver extends Actor{
override def receive= {
case msg:String =>println(msg)
}
}
conf文件
trait conf {
def getconf (hostname:String,Port:String)={
val list =new java.util.ArrayList[String]()
list.add("akka.remote.netty.tcp");
val conf = new java.util.HashMap[String,Object]();
conf.put("akka.actor.provider", "akka.remote.RemoteActorRefProvider");
conf.put("akka.remote.enabled-transports", list);
conf.put("akka.remote.netty.tcp.hostname",hostname);
conf.put("akka.remote.netty.tcp.port",Port);
conf
}
}Driver文件
object Driver extends conf {
def main(args: Array[String]): Unit = {
//构建环境
val sys=ActorSystem("Driver",ConfigFactory.parseMap(getconf("127.0.0.1","3000")));
//注册
sys.actorOf(Props[Driver]);
val sc = new Scanner(System.in);//从键盘获取字符
val map = sys.actorSelection("akka.tcp://Mapper@127.0.0.1:3001/user/mapper")//连接到Mapper端
while (sc.hasNext())
{
val line =sc.nextLine();
//调用MapperTask,每行按空格来分割单词 MapperTask即Task中的样例类的构造函数
//(line:String)=>{line.split(" ").toList.map(x=>(x,1))即mfunc的实现,先按空格分割单词,然后将其转换为list类型
//再将每个单词转换为元组类型
val mapperTask= MapperTask(line,(line:String)=>{line.split(" ").toList.map(x=>(x,1))})
map ! mapperTask //调用作业
}
}
}Mapper文件:
import akka.actor.Actor
import akka.actor.ActorSystem
import com.typesafe.config.ConfigFactory
import akka.actor.Props
import akka.actor.ActorSelection
class Mapper extends Actor {
override def receive ={
case MapperTask(line ,mfunc)=>{
val result=mfunc(line);//mfunc对line操作,方法已在Driver中实现,result是List类型
//依次对元组中相同key的value累加
for(r<-result){
println(r)
//ReducerTask在Reducer端实现,(a,b)=>a+b是rfunc的实现
Mapper.getreducer() ! ReducerTask(r,(a,b)=>a+b)
}
}
}
}
object Mapper extends conf{
def getreducer()={
reducer
}
var reducer:ActorSelection=null;
def main(args: Array[String]): Unit = {
//构造环境
val sys=ActorSystem("Mapper",ConfigFactory.parseMap(getconf("127.0.0.1","3001")));
//注册
sys.actorOf(Props[Mapper],"mapper");//Driver需要连Mapper,需要对Mapper需要起个名字
//mapper地址:akka.tcp://Mapper@127.0.0.1:3001/user/mapper
//Mapper连接到Reducer
reducer=sys.actorSelection("akka.tcp://Reducer@127.0.0.1:3002/user/reducer")
}
}Reducer端:
import akka.actor.Actor
import akka.actor.ActorSystem
import com.typesafe.config.ConfigFactory
import akka.actor.Props
class Reducer extends Actor{
import scala.collection.mutable.Map
val combine=Map[String,Int]();
override def receive = {
// ReducerTask的实现
case ReducerTask((key,value),rfunc)=>{
//getOrElse判断combine中在否存在这个key,有就返回对应的value,没有就返回0
val v= combine.getOrElse(key,0);
combine+=key -> rfunc(v,value);//调用rfunc,进行累加
println(combine);
}
}
}
object Reducer extends conf{
def main(args: Array[String]): Unit = {
//构造环境
val sys = ActorSystem("Reducer",ConfigFactory.parseMap(getconf("127.0.0.1","3002")))
//注册
sys.actorOf(Props[Reducer],"reducer");
//Reducer 的访问地址:akka.tcp://Reducer@127.0.0.1:3002/user/reducer
}
}启动时先启动Reducer,再启动Mapper,最后启动Driver。
启动后在Driver端的控制台里输入字符串,如”hello world“,可以在mapper端控制台看到Mapper已经对字符串的单词进行了分割并分组,在reducer端控制台可以看到Reducer已经将单词统计好
//Driver端输入Hello world字符串
[INFO] [04/08/2018 14:53:20.805] [main] [Remoting] Starting remoting
[INFO] [04/08/2018 14:53:21.337] [main] [Remoting] Remoting started; listening on addresses :[akka.tcp://Driver@127.0.0.1:3000]
[INFO] [04/08/2018 14:53:21.337] [main] [Remoting] Remoting now listens on addresses: [akka.tcp://Driver@127.0.0.1:3000]
hello world
//Mapper将其分割
[INFO] [04/08/2018 14:53:09.877] [main] [Remoting] Starting remoting
[INFO] [04/08/2018 14:53:10.487] [main] [Remoting] Remoting started; listening on addresses :[akka.tcp://Mapper@127.0.0.1:3001]
[INFO] [04/08/2018 14:53:10.487] [main] [Remoting] Remoting now listens on addresses: [akka.tcp://Mapper@127.0.0.1:3001]
(hello,1)
(world,1)
//Reducer对其统计
[INFO] [04/08/2018 14:52:50.527] [main] [Remoting] Starting remoting
[INFO] [04/08/2018 14:52:51.262] [main] [Remoting] Remoting started; listening on addresses :[akka.tcp://Reducer@127.0.0.1:3002]
[INFO] [04/08/2018 14:52:51.262] [main] [Remoting] Remoting now listens on addresses: [akka.tcp://Reducer@127.0.0.1:3002]
Map(hello -> 1)
Map(world -> 1, hello -> 1)
若在Driver控制台中再输入其他字符串,如Hello spark hello Hadoop,再观看Mapper和Reducer端,可以看到Mapper和Reducer又进行了实时分割和统计。
[INFO] [04/08/2018 14:53:20.805] [main] [Remoting] Starting remoting
[INFO] [04/08/2018 14:53:21.337] [main] [Remoting] Remoting started; listening on addresses :[akka.tcp://Driver@127.0.0.1:3000]
[INFO] [04/08/2018 14:53:21.337] [main] [Remoting] Remoting now listens on addresses: [akka.tcp://Driver@127.0.0.1:3000]
hello world
hello spark hello Hadoop //Driver端再输入字符串
[INFO] [04/08/2018 14:53:09.877] [main] [Remoting] Starting remoting
[INFO] [04/08/2018 14:53:10.487] [main] [Remoting] Remoting started; listening on addresses :[akka.tcp://Mapper@127.0.0.1:3001]
[INFO] [04/08/2018 14:53:10.487] [main] [Remoting] Remoting now listens on addresses: [akka.tcp://Mapper@127.0.0.1:3001]
(hello,1)
(world,1)
(hello,1) //Mapper做了新的分割
(spark,1)
(hello,1)
(Hadoop,1)[INFO] [04/08/2018 14:52:50.527] [main] [Remoting] Starting remoting
[INFO] [04/08/2018 14:52:51.262] [main] [Remoting] Remoting started; listening on addresses :[akka.tcp://Reducer@127.0.0.1:3002]
[INFO] [04/08/2018 14:52:51.262] [main] [Remoting] Remoting now listens on addresses: [akka.tcp://Reducer@127.0.0.1:3002]
Map(hello -> 1)
Map(world -> 1, hello -> 1)
Map(world -> 1, hello -> 2) //Reducer进行了新的统计
Map(spark -> 1, world -> 1, hello -> 2)
Map(spark -> 1, world -> 1, hello -> 3)
Map(spark -> 1, Hadoop -> 1, world -> 1, hello -> 3)本程序中需要改进的地方:
- Mapper 要有多个,要增加并行度
- Reducer要有多个,一方面增加并行度,
- Mapper的输出结果,key相同的应该被发给同一个reducer
- reducer的函数应该放在driver端
- 缺少Master角色,负责整个集群中资源的分配,以及任务的调度















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









