






Java集合类框架图

Collection
List
| 类型 | 数据结构 | 查询速度 | 插入速度 | 是否线程安全 |
| ArrayList | 数组 | 快 | 慢 | 否 |
| LinkList | 双向链表,| 慢 | 快 | 否 |
| Vector | 数组 | 慢 | 慢 | 是 |
对于它们三种类型的List的查询、删除、插入的性能(时间复杂度和空间复杂度)可以根据它们底层所依赖的数据结构和算法具体分析,上面的图表只是简单的总结。在实际开发中,存在大量的随机访问和少量的删除、插入时推荐使用ArrayList,反之使用LinkList。在需要保证线程安全的情况下使用Vetor,同样Collections.synchronizedList(new ArrayList())和Collections.synchronizedList(new LinkList())也能获得线程安全的List。Set
Set和List比较
| 类型 | 是否有序 | 元素是否允许重复 |
| List | 是 | 否 |
| Set | 否 | 是 |HashSet
实现Set接口,基于HashMap实现,容器内元素不能重复。
Map
HashMap
HashMap的数据结构
HashMap中的数据结构是数组+链表实现,如图:
 HashMap的查找:首先根据hashcode在table数组中查找,然后根据key在其后的链表中获得key。
HashMap的查找:首先根据hashcode在table数组中查找,然后根据key在其后的链表中获得key。
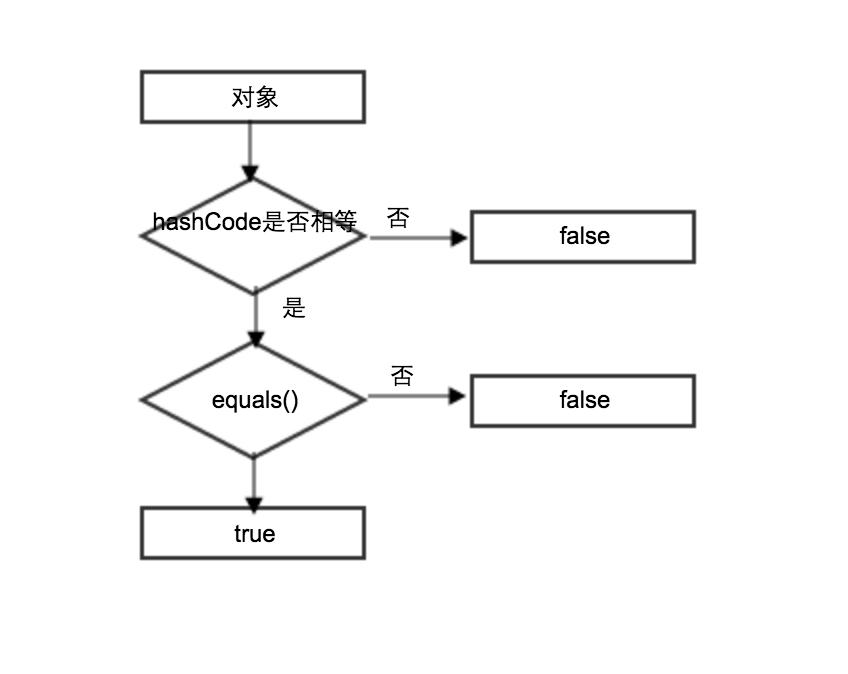
hashcode()和equals()方法
equals()
指示其他某个对象是否与此对象“相等”。
equals 方法在非空对象引用上实现相等关系:
(1)自反性:对于任何非空引用值 x,x.equals(x) 都应返回 true。
(2)对称性:对于任何非空引用值 x 和 y,当且仅当 y.equals(x) 返回 true 时,x.equals(y) 才应返回 true。 (3)传递性:对于任何非空引用值 x、y 和 z,如果 x.equals(y) 返回 true,并且 y.equals(z) 返回 true,那么 x.equals(z) 应返回 true。
(4)一致性:对于任何非空引用值 x 和 y,多次调用 x.equals(y) 始终返回 true 或始终返回 false,前提是对象上 equals 比较中所用的信息没有被修改。
(5)对于任何非空引用值 x,x.equals(null) 都应返回 false。
(6)Object 类的 equals 方法实现对象上差别可能性最大的相等关系;即,对于任何非空引用值 x 和 y,当且仅当 x 和 y 引用同一个对象时,此方法才返回 true(x == y 具有值 true)。(实际JDK中对equals()方法进行了重写)
注意:当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。
//重写equals()方法Demo
public class Student {
protected String name;
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public boolean equals(Object obj){
if(obj instanceof Student){
Student student = (Student) obj;
if(student.getName() == null || name == null){
return false;
}else {
return name.equalsIgnoreCase(student.getName());
}
}
return false;
}
}
public class SeniorStudent extends Student {
//增加一个id属性
private int id;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public SeniorStudent(String name, int id) {
super(name);
this.id = id;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof SeniorStudent) {
SeniorStudent ss = (SeniorStudent) obj;
return super.equals(obj) && ss.getId() == id;
}
return false;
}
}
//测试
public class Test {
public static void main(String[] args) {
SeniorStudent ss1 = new SeniorStudent("zhangsan", 10);
SeniorStudent ss2 = new SeniorStudent("zhangsan", 20);
Student s = new Student("zhangsan");
System.out.println(s.equals(ss1));
System.out.println(s.equals(ss2));
System.out.println(ss1.equals(ss2));
}
}
预期:
false
false
false
结果:
true
true
false
原因分析:
我们使用instanceof关键字来检查ss否为Student类,而instanceof是判断其左边对象是否为其右边类的实例,也可以用来判断继承中的子类的实例是否为父类的实现,所以当有继承的时便会出现问题。
//所以在equals()中使用getClass进行类型判断hashcode()
返回该对象的哈希码值。支持此方法是为了提高哈希表(例如 java.util.Hashtable 提供的哈希表)的性能。 hashCode 的常规协定是:
(1)在 Java 应用程序执行期间,在对同一对象多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是将对象进行 equals 比较时所用的信息没有被修改。
(2)从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。 如果根据 equals(Object) 方法,两个对象是相等的,那么对这两个对象中的每个对象调用 hashCode 方法都必须生成相同的整数结果。
(3)如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么对这两个对象中的任一对象上调用 hashCode 方法不要求一定生成不同的整数结果。但是,程序员应该意识到,为不相等的对象生成不同整数结果可以提高哈希表的性能。
实际上,由 Object 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是 JavaTM 编程语言不需要这种实现技巧。)
hashCode()和equals配合使用
//重写hashCode()和equals()的Demo
public class Student1 {
private int age;
private String name;
public Student1(int age, String name) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
System.out.println("调用equals()方法");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student1 student1 = (Student1) o;
if (age != student1.age) return false;
return !(name != null ? !name.equals(student1.name) : student1.name != null);
}
@Override
public int hashCode() {
System.out.println("调用hashCode()方法");
int result = age;
result = 31 * result + (name != null ? name.hashCode() : 0);
System.out.println("name: " + name + " age: " + age + " hashCode "+result);
return result;
}
public static void main(String[] args) {
Student1 s1 = new Student1(1,"张三");
Student1 s2 = new Student1(2,"张三");
Student1 s3 = new Student1(1,"李四");
Student1 s4 = new Student1(1,"张三");
System.out.println("s1 == s4 " + (s1==s4 ));
System.out.println("s1.equals(s4)" + s1.equals(s4));
HashSet<Student1> hashSet = new HashSet();
hashSet.add(s1);
hashSet.add(s2);
hashSet.add(s3);
hashSet.add(s4);
System.out.println(hashSet.size());
}
}
//结果
s1 == s4 false
调用equals()方法
s1.equals(s4)true
调用hashCode()方法
name: 张三 age: 1 hashCode 774920
调用hashCode()方法
name: 张三 age: 2 hashCode 774951
调用hashCode()方法
name: 李四 age: 1 hashCode 842092
调用hashCode()方法
name: 张三 age: 1 hashCode 774920
调用equals()方法 //注意调用equals()方法 s1.equals(s4)==true时
3HashMap常见遍历方式比较
//(方法1)同时获取key-value
Map<String,String> map = new HashMap();
for (Map.Entry<String,String> entry : map.entrySet()) {
entry.getKey();
entry.getValue();
}
//(方法2)获取key
Map<String, String> map = new HashMap();
for (String key : map.keySet()) {
System.out.println(key);
}
//(方法3)获取value
Map<String, String> map = new HashMap();
for (String key : map.keySet()) {
String value = map.get(key);
}
//(方法4)获取value
Map<String, String> map = new HashMap();
for (String value : map.values()) {
System.out.println(value);
}
//上面的四个例子也可以使用迭代器,方法(1)可以如下,但是不推荐
Map<String, String> map = new HashMap();
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
}
/**
*同时获取key-value是推荐使用方法(1)
*只是获取key推荐方法(2)
*获取方法value(4)
**/Hashtable
Hashtable和HashMap采用同样的数据结构,实现基本相同。
Hashtable和HashMap的比较
| 类型 | key为是否允许为null | key为是否允许为null | 是否线程安全 | 效率 | 父类 |
| Hashtable | 是 | 是 | 否 | 高 | Dictionary |
| HashMap | 否 | 否 | 是 | 低 | AbstractMap |
ConcurrentHashMap
并发下HashMap死循环问题
//案例如下:运行下面代码,使用top命令,CPU会飙升趋于100%
public class HashMapInfLoop {
private HashMap map = new HashMap();
public HashMapInfLoop() {
for(int i =0; i<100000; i++) {
Thread thread = new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 50000000; i++) {
map.put(new Integer(i), Integer.valueOf(i));
}
}
});
thread.start();
}
}
public static void main(String[] args) {
new HashMapInfLoop();
}
}HashMap死循环问题分析
问题出在扩容时,移动oldTable里的数据到newTable里时,在并发条件下会出现环路。源码如下:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}图解分析可以参考:http://ifeve.com/hashmap-infinite-loop/
上面的例子可以说明并发下不能使用HashMap,那我们可以使用线程安全的Hashtable吗?
HashTable中是使用synchronized实现同步,synchronized锁的HashTable的实例对象,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程A使用put进行添加元素,线程B不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。所以就得使用ConcurrentHashMap。
ConcurrentHashMap实现原理
ConcurrentHashMap结构图:
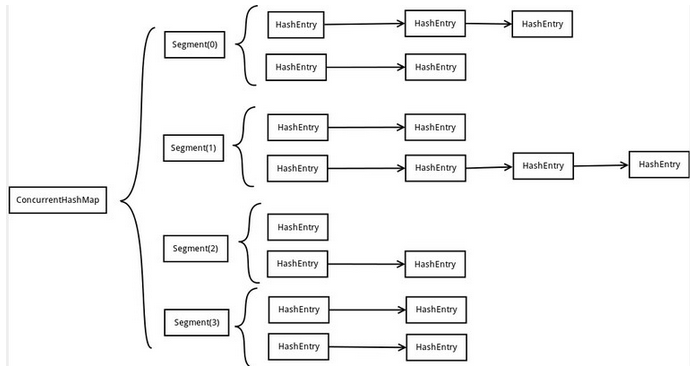
根据ConcurrentHashMap的结构图可以明显看出,ConcurrentHashMap采用的是二次hash的方式,
第一次hash将key映射到对应的segment(Segment是一种可重入锁ReentrantLock),而第二次hash则是映射到segment的不同桶中。为什么要用二次hash,主要原因是为了构造分离锁,使得对于map的修改不会锁住整个容器,提高并发能力。但是二次hash带来的问题是整个hash的过程比hashmap单次hash要长,所以不是并发情况下不要使用ConcurrentHashMap。
WeakHashMap
WeakHashMap 使用 WeakReference 作为 key, 一旦没有指向 key 的强引用, WeakHashMap 在 GC 后将自动删除相关的 entry。
WeakHashMap<String,String> map = new WeakHashMap<String, String>();
map.put("wjk","hello");
map.put("snail","world");
map.put(new String("wjk"),"hello");
map.put(new String("snail"),"world");
System.gc();
System.out.println(map.size());
}
//输出
2Java引用类型可以参考:http://my.oschina.net/u/2361475/blog/603125
TreeMap
扩展
使用Google Guava框架和Apache Commons框架的工具类集合工具类,编写优雅的代码。















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









