







1.引言
小白以前学过集合框架,也经常用,但这你敢觉得懵懵懂懂。有空重温了一下java的集合框架,记录一下,以免我的记忆只有7秒。
数据结构(data structure)是以某种形式将数据组织在一起的集合,数据结构不仅存储数据,还支持那些些访问和处理数据的操作。例如ArrayList,他是一种将数据存储在线性表中的数据结构。
java还提供了几个能够有效组织和操作数据的数据结构,这些数据结构通常称为集合框架(Java Collections Framework)
在面向对象的思想里,一种数据结构也被认为是一个容器(container)他是一个能存储其他对象的对象,这里的其他对象是指数据或者元素。定义一个数据结构本质上就是定义一个类。数据结构类应该使用数据域存储数据,并提供方法支持查找,插入,和删除操作,因此,创建一个数据结构就是创建这个类的实例。然后可以使用这个实例上的方法来操作这个数据结构,例如像该数据结构中插入一个元素,或者从这个数据结构中删除一个元素。
java集合支持以下两种类型的容器:
一种是为了存储一个元素的集合,简称为集合(collection)
另一种是为了存储键/值对,称为图(map)。
2.集合
Java集合框架支持三种主要类型的集合:规则集(Set)、线性表(List)和队列(Queue)。
Set的实例用于存储一组不重复的元素。List的实例用于存储一个由元素构成的有序集合。Queue的实例用于存储用先进先出方式处理的对象。这些集合的通用特性都被定义在接口中,而它的实现是在具体类中提供的。
java集合框架中定义的所有接口和类都存储在java.util包中.
Java集合框架的设计师使用接口。抽象类和具体类的一个很好的例子。用接口定义框架。为方便起见,用抽象类提供这个接口的部分实现,具体类用具体的数据结构实现这个接口。
Java集合框架中的所有具体类都实现了java.lang.Cloneable和java.io.Serializable接口。所以它们的实例都是可复制且可序列化的。
Collection接口
Collection接口是处理对象集合的根接口,提供了在集合中添加与删除元素的基本操作。
add() 为集合添加一个元素。
addAll() 把指定集合中的所有元素添加到这个集合。
remove() 从集合中删除一个元素。
removeAll() 从集合中删除指定集合中的所有元素。
retainAll() 保留既出现在这个集合中,也出现在指定集合中的元素。
clear() 删除集合中的所有元素。
所有这些方法都返回boolean值,如果执行方法会改变这个集合,那么返回值为true
Collection接口提供了多重查询操作。方法size返回集合中元素的个数,方法contains检测集合中是否包含指定元素,方法CollectionsAll检测这个集合是否包含指定集合中的所有元素,如果集合为空,方法isEmpty返回true。
Collection接口提供的toArray()方法返回一个表示集合的数组。
集合可以是一个规则集,也可以是一个线性表。Iterator接口提供了对不同类型集合中的元素进行遍历的统一方法。Collection接口中的iterator方法返回Iterator接口的一个实例,它使用next()方法顺序访问集合中的元素,也可以使用hasNext()方法来检测迭代器中是否还有元素,remove方法删除从迭代器返回的最后一个元素。
Collection接口中的有些方法是不能再具体子类中实现的,在这种情况下会抛出java.lang.UnsupportedOperationException,他是RuntimeException异常类的子类。
规则集
Set接口扩展了Collection接口,他没有引入新的方法和常量,只是包含Set的实例不包含重复的元素。实现Set的具体类必须保证没有想这个规则集中添加重复的元素。也就是说在一个规则集中不存在元素e1,e2使得
e1.equals(e2)的返回值为true。
一个规则集的散列码是这个规则集中所有元素散列码的和。
Set接口的三个具体类是:散列类HashSet、链式散列表LinkedHashSet和树形集TreeSet。
散列集HashSet
HashSet是用来实现Set接口的具体类,可以使用它的无参构造方法来创建空的散列集,也可以由一个现有的集合创建散列集。默认情况下,初始容量为16而客座率是0.75.如果知道集合的大小,就可以在构造方法中指定初始容量和客座率。否则就使用默认的设置。客座率在0.0到1.0之间。
客座率(load factor)
客座率测量在增加规则集的容量之前,该规则集的饱满程度。当元素个数超过了客座率的乘积,容量就会自动翻倍,通常情况下默认客座率是0.75,他是在时间开销和空间开销上的一个很好的权衡。、
HashSet可以用来存储互不相同的任何元素。考虑到效率的因素,添加到散列集中的对象必须以一种正确分散散列码的方式实现hashCode方法。如果这两个对象相等,那么这两个对象的散列码必须相等,两个不相等的对象可能会有相同的散列码。散列集中的元素是没有特定的顺序的,重复元素只会存储一次。
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class TestHashSet {
/**
* @param args
*/
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("London");
set.add("Paris");
set.add("New York");
set.add("San francisco");
set.add("Beijing");
set.add("New York");
System.out.println(set);
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toUpperCase() + " ");
}
}
}
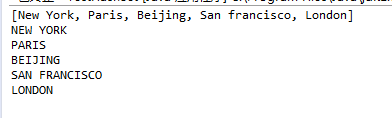
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class TestMethodCollection {
/**
* @param args
*/
public static void main(String[] args) {
Set<String> set1 = new HashSet<String>();
set1.add("London");
set1.add("Paris");
set1.add("New York");
set1.add("San francisco");
set1.add("Beijing");
set1.add("New York");
System.out.println("set1 is"+ set1);
System.out.println(set1.size()+" elements in set1");
set1.remove("London");
System.out.println("set1 is"+set1);
System.out.println(set1.size()+" elements in set1");
Set<String> set2 = new HashSet<String>();
set2.add("London");
set2.add("ShangHai");
set2.add("Paris");
System.out.println("\nset2 is "+set2);
System.out.println(set2.size()+" elements in set2");
System.out.println("\nIs Taipei in set2?"+set2.contains("Taipei"));
set1.addAll(set2);
System.out.println("\nAfter adding set2 to set1,set1 is "+set1);
set1.removeAll(set2);
System.out.println("After removing set2 from set1,set1 is"+set1);
set1.retainAll(set2);
System.out.println("After removing common elements in set2" +"from set1,set1 is" +set1);
}
}

要强加顺序,就需要使用LinkedHashSet类.
LinkedHashSet用一个链表实现来扩展HashSet类,他支持规则集内的元素排序,HashSet中的元素是没有被排序的,而LinkedHashSet中的元素可以按照他们插入规则集的顺序提取。
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
public class TestLinkedHashSet {
/**
* @param args
*/
public static void main(String[] args) {
Set<String> set1 = new LinkedHashSet<String>();
set1.add("London");
set1.add("Paris");
set1.add("New York");
set1.add("San francisco");
set1.add("Beijing");
set1.add("New York");
System.out.println("set is"+ set1);
for(Object ob:set1){
System.out.println(ob.toString().toLowerCase()+" ");
}
}
}
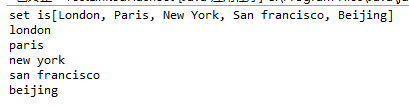
LinkedHashSet保持了元素插入时的顺序。要强加一个不同的顺序(例如,升序或降序),可以使用
树形集TreeSet类。
树形集TreeSet
TreeSet实现了Set接口的子接口SortedSet接口的一个具体类,只要对象互相可以比较,就可以添加到树形集中。
treeSet.first()返回treeSet的第一个元素。
treeSet.last()返回treeSet中的最后一个元素。
treeSet.headSet(“xxx”)返回treeSet中xxx之前的那些元素。
treeSet.tailSet(“xxx”)返回treeSet中的xxx及它之后的元素。
treeSet.lower(“P”)返回treeSet中小于”P”的最大元素。
treeSet.floor(“P”)返回treeSet中小于或等于”P”的最大元素。
treeSet.celling(“P”)返回treeSet中大于或等于”P”的最小元素。
treeSet.pollFirst()删除treeSet中的第一个元素,并返回删除的元素。
treeSet.pollLast()删除treeSet中的最后一个元素,并返回被删除的元素。
Java集合框架中的所有具体类都至少有两个构造方法,一个是创建空集合的无参数构造方法,另一个是用某个集合来创建实例的构造方法。
线性表
规则集只能存储不重复的元素,为了允许在一个集合中存储重复的元素,需要使用线性表。线性表不仅可以存储重复的元素,而且允许用户指定他们的存储位置。用户可以用下标来访问元素。List
接口扩展了Collection接口,以定义一个允许重复的有序集合。List接口增加了面向位置的操作,并且早呢更加了一个能够双向遍历的新列表迭代器。
方法add(index,element)用于指定下标处插入一个元素。
方法addAll(index,collection)用于在指定下标处插入一个集合。
方法remove(index)用于从线性表中删除指定下标处的元素。
方法set(index,element)可以在指定下标处设置一个新元素。
方法indexOf(element)用于获取指定元素在线性表中第一次出现时的下标。
方法lastIndexof(element)用于获取指定元素在线性表最后一次出现的下标。
方法subList(fromIndex,toIndex)可以获得一个子线性表。
方法listIterator()或listIterator(startIndex)都会返回ListIterator的一个实例。ListIterator接口扩展了Iterator接口,以增加对线性表的双向遍历能力。
方法add(element)用于将制定元素插入线性表中。
如果Iterator接口中定义的next()方法的返回值非空,该元素将立即被插入到next()方法返回的元素之前;而且,如果previous()方法的返回值非空,该元素将立即被插入到previous()方法返回的元素之后。
如果线性表中没有元素,这个新元素即成为线性表中唯一的元素。set(element)方法返回用于将next方法或previous方法返回的最后一个元素替换为指定的元素。
在Iterator接口中定义的方法hasNext()用于检测迭代器向前遍历时是否还有元素。
方法hasPrevious()用于检测迭代器向后遍历时是否还有元素。
在Iterator接口中定义的方法next()返回迭代器中的下一个元素,而方法previous()返回迭代器中的前一个元素。方法nextIndex()返回迭代器中下一个元素的下标,previousIndex()返回迭代器中前一个元素的下标。
数组线性表类ArrayList和链表类LinkedList是实现List接口的两个具体类。ArrayList用数组存储元素,这个数组是动态创建的。如果元素个数超过了数组的容量,就会创建一个更大的新数组,并将当前数组中的所有元素都复制到新数组中。LinkedList在一个链表中存储元素。
如果需要通过下标随时访问元素,但是除了在末尾处之外,不能在其他位置插入或删除元素,那么ArrayList提供了更高效率的集合,
如果应用程序需要在线性表的任意位置插入或删除元素,就需要LinkedList类。
如果不需要插入和删除,数组效率最高。
ArrayList是一个实现List接口的大小可变的数组。他还提供一些方法,用于管理存储线性表的内部数组的大小。ArrayList不能自动减小,可以使用方法trimSize()将数组容量减小到线性表大小。
LinkedList是实现List接口的一个链表。除了实现List接口的方法外,这个类还提供从线性表两端提取,插入和删除元素的方法。
若要提取元素或在线性表的尾部插入和删除元素,ArrayList的效率比较高。若要在线性表的任意位置上插入和删除元素,那么LinkedList的效率会更高。
规则集和线性表的性能比较
规则集比线性表更加高效。如果应用程序用规则集就足够,就使用规则集。除此之外,如果程序不需要特别的顺序,就选择散列集。
图
假设程序存储了一百万个学生,而且经常需要使用社保号来搜索某个学生。针对这个任务的有效数据结构就是图(map).图是一种依照键值存储的容器。键值很像下标,在list中,下标是整数;而在map中,键值可以使任意类型的对象。图中不能有重复的键值,每个键值都对应一个值。一个键值和他的对应值构成一个条目,真正在图中存储这个条目。
图的类型有三种:散列图HashMap,链式散列图LinkedHashMap和树形图TreeMap。这些图的通用特性都定义在Map接口中。
Map接口提供了查询,更新和获取集合的值和集合的键值对的方法。
更新方法(update methods)包括clear。put。putAll和remove。
方法clear()从图中删除所有的条目。
方法put(K Key,V value)将一个值和图中的一个键值相关联。如果这个图原来就包含到该键值的一个映射,那么该方法会返回原来和这个键值相关联的旧值。
方法putAll(Map m)将制定的图m添加到这个图中。
方法remove(Object key)将制定键对应的图元素从图中删除。
查询方法(query methods)包括containsKey、containsValue、isEmpty和size。
方法containsKey(Object key)检测图中是否包含指定键值的映射。
方法containsValues(Object value)检测图中是否包含指定值的映射。
方法isEmpty()检测图中是否包含映射。
方法size()返回图中映射的个数。
方法keySet()来获得一个包含图中键值的规则集,也可以使用方法values()获得一个包含图中值的集合。方法entrySet()返回一个实现Map.Entry















 6890
6890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









